







二叉树及其数据结构定义
二叉树是计算机当中最重要的数据结构之一,其应用非常广泛,例如数据库的索引使用的B+树是一种特殊的二叉树,堆排序所使用的堆是一种特殊的二叉树,Java当中HashMap使用的红黑树是一种特殊的二叉树。可见,二叉树在计算机编程当中有着重要地位。二叉树的遍历是二叉树的基本操作,不仅是面试的常考考点,也是程序员用来锻炼思维的小把戏。
二叉树的定义是递归的,即满足如下条件的树是二叉树:
- 一棵树当中的每个节点,最多有2棵子树;
- 如果一个节点有子树,那么子树必须是二叉树。
我们可以看到,二叉树的定义是递归的,递归的边界是一个节点没有子树。如下图所示,是一棵二叉树:
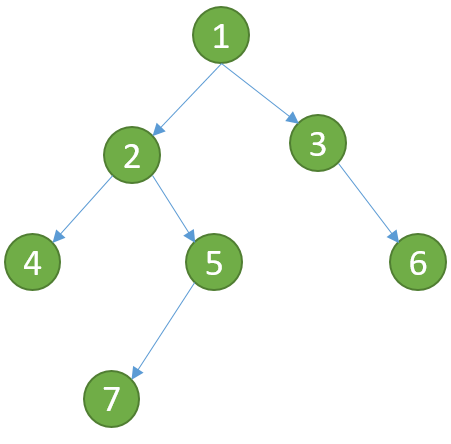
可以看到,二叉树当中的每个节点,有值,也可能有左子节点,也可能有右子节点,因此我们经常用二叉链表的形式存储。上述二叉树在内存当中将以以下形式存储。
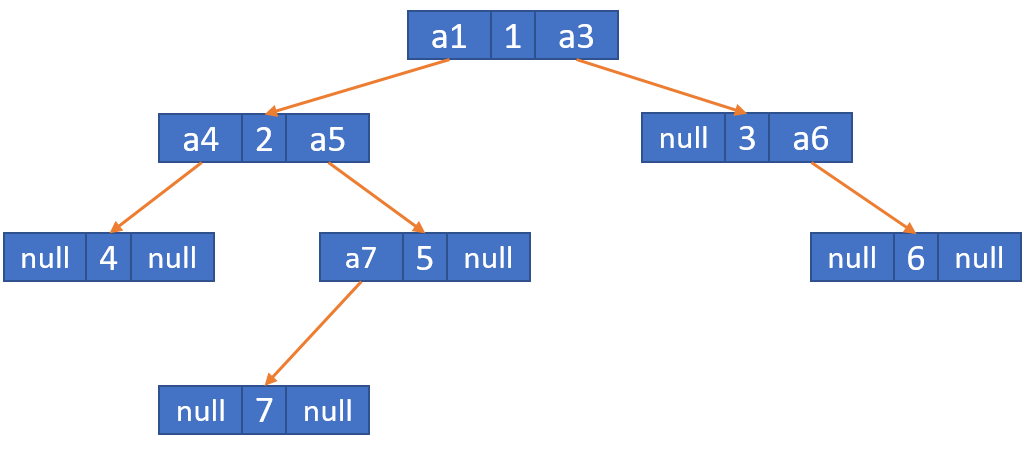
图中,每个节点对应三个字段,或者叫域(field),包括:值(val)、左子节点的地址(left)、右子节点的地址(right),地址用ax表示,表示节点x的内存地址(address)。如果一个节点没有左子节点,那么对应的字段为null。
二叉树的节点对应的Python类可以写成如下形式:
# 节点的数据结构
# val表示值、left表示当前节点的左子节点地址、right表示右子节点地址
class Node(object):
def __init__(self, val, left, right):
self.val = val
self.left = left
self.right = right
既然二叉树用上面这种形式存储起来了,那么给定一个根节点(上图当中的第1个节点,值为1的节点),我们就可以知道这个二叉树的所有信息了,这和链表类似:对于一个单链表,只给一个头指针节点,就可以知道这个单链表的所有信息。因此,当我们说给定一个二叉树的时候,其实就是给定一个二叉树的根节点,因为知道根节点就知道这棵二叉树的全部了。
三种递归方式
二叉树的遍历方式可以分为两类:深度优先遍历(Depth First Search, DFS)和广度优先遍历(Breadth First Search, BFS)。广度优先遍历BFS会在后续的博客中再谈,而深度优先遍历又包含前序、中序、后序遍历,是今天的重点。
前序、中序、后序遍历中的“序”指的是在遍历过程中,根节点遍历的时间,相对左子树和右子树的次序。三者的定义分别如下:
- 前序遍历:先遍历根节点,再遍历左子树,最后遍历右子树。(根节点在前)
- 中序遍历:先遍历左子树,再遍历根节点,最后遍历右子树。(根节点在中)
- 后序遍历:先遍历左子树,再遍历右子树,最后遍历根节点。(根节点在后)
说明:我们规定,无论是哪种顺序,左子树和右子树的顺序是,先左子树后右子树。这两个的顺序不是很关键,不重要。
可以看到,上面三种遍历方式的定义,也是递归的,“遍历左子树”、“遍历右子树”,我们知道二叉树的某个节点的子树,也是二叉树,这就是递归,但是问题规模减小了,所以这个递归是可解的。那么,递归边界是什么?边界是:当一棵二叉树的左子节点和右子节点,都不存在,都为null的时候,就不继续往下遍历了。
前序遍历
针对上图的例子,前序遍历的过程如下:
首先遍历根节点1,如下图,将1存储在结果数组的最开始位置。然后发现有两棵子树,先不考虑两棵子树怎么遍历,我们只需要知道,左子树遍历的结果排在数组当中根节点1的后面,右子树的遍历结果存储在左子树遍历结果的后面,如下图所示。
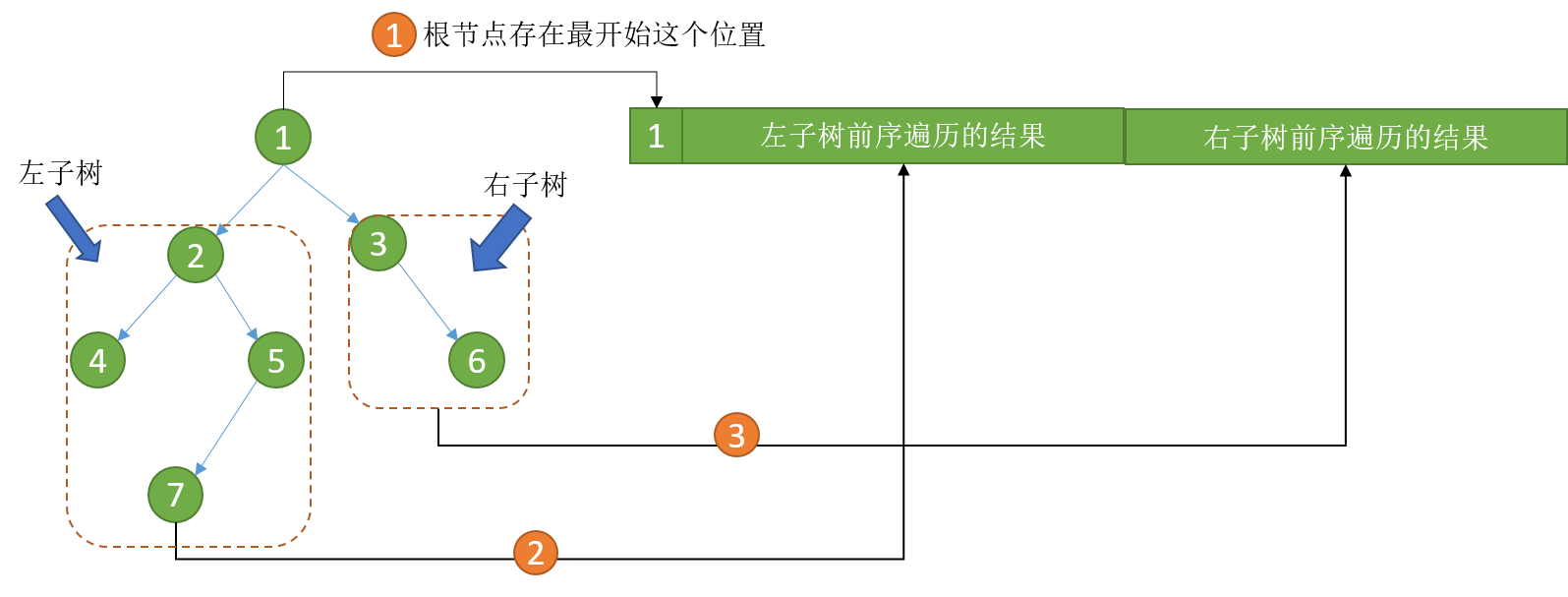
上图中,绿色长条表示我们编程时候使用的结果数组。遍历分为三大步骤:
- 先遍历根节点,把根节点1,存储在数组最开始的位置;
- 然后遍历左子树,把左子树进行前序遍历(具体怎么遍历先不考虑),将结果存储在1的后面;
- 最后遍历右子树,将右子树进行前序遍历(具体怎么遍历先不考虑),将结果存储在左子树遍历结果的后面。
那么左子树、右子树该怎么遍历呢,采用和上述步骤相同的步骤。拿左子树举例,如下图所示:
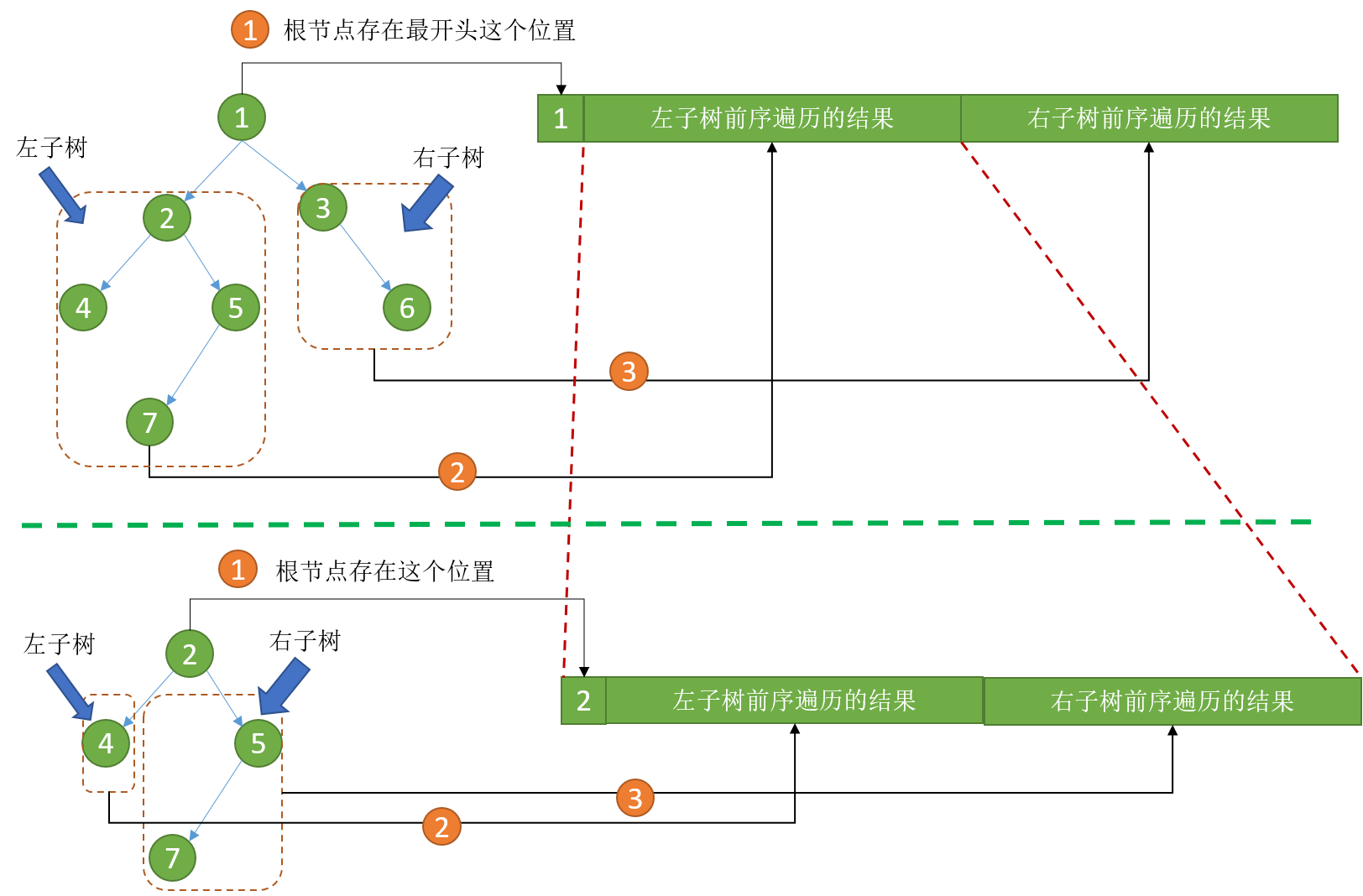
左子树也是一棵二叉树,根节点是2,新的根节点有左右两棵子树。类似地,这棵树的遍历分为三大步骤:
- 遍历根节点2,写到结果数组的最开始,注意这里的最开始依然是在上图中上半部分的数组中的节点1的后面;
- 遍历2的左子树,将结果写到节点2的位置的后面;
- 遍历2的右子树,将结果写到上一步的后面。
因此,这棵树的遍历结果是:2 (4) (5 7),括号表示左子树和右子树,展开就是2 4 5 7。
而原二叉树的右子树的遍历结果是:3 () (6),其中括号()表示左子树是空的,没有元素,展开就是3 6。
所以将(2 4 5 7)和(3 6)追加到根节点1的后面,就得到了原二叉树的前序遍历结果:1 (2 4 5 7) (3 6)。
下面再来看中序遍历和后序遍历。方便起见,二叉树的图再贴到下面:
中序遍历
上面我们已经得到了前序遍历的结果是1 (2 4 5 7) (3 6),其中(2 4 5 7)是左子树的前序遍历的结果,(3 6)是右子树前序遍历的结果。中序遍历的结果就是先遍历左子树,再遍历根节点,最后遍历右子树。那么是不是可以根据前序遍历直接得到中序遍历的结果呢:(2 4 5 7) 1 (3 6)?不能!因为这里要求左子树和右子树也必须是中序遍历的,而(2 4 5 7)是前序遍历的结果。
中序遍历的结果,可以分为三大步骤:
- 中序遍历左子树:先遍历
4,再遍历2,最后遍历5和7(5相对7是根节点,7相对5是左子树,应该先遍历7,再遍历5,所以是(7 5))。因此左子树中序遍历的结果是:(4) 2 (7 5)。 - 遍历根节点:即
1。 - 中序遍历右子树:右子树是
3和6,发现这颗子树当中,根节点3的左子树为空,那么就遍历根节点3,再遍历右子树6,而右子节点6没有子树了,结束了。所以这颗右子树的中序遍历结果是:3 (6)
所以,上述二叉树的中序遍历结果是:(4 2 7 5) 1 (3 6) 。打括号知识为了标记谁是子树,最终结果不需要括号。
后序遍历
后序遍历,将根节点放到最后,那么大致的顺序是(2 4 5 7) (3 6 ) 1,根节点1的位置确定放到最后了。
左子树(2 4 5 7),根节点是2放到最后,剩下左子树4(遍历左子树,发现为空,遍历右子树,发现为空,最后遍历根节点4)和右子树(5 7)(遍历根节点5的左子树7,遍历右子树为空,最后遍历根节点5),因此右子树(5 7)的后续遍历结果是(7 5)。因此这整个左子树的结果是(4 7 5 2),
右子树(3 6)先遍历6,最后遍历3,因此是(6 3)。
所以,上述二叉树的后序遍历结果是:(4 7 5 2) (6 3) 1。打括号知识为了标记谁是子树,最终结果不需要括号。
递归实现
根据上面的讨论,我们已经了解了三种遍历方式。三种遍历的定义本身就是递归的,因此用递归的方式编写相对更简单,三种遍历方式的递归实现Python代码如下(经测试有效):
# 全局变量记录遍历的结果
result = []
# 前序
def dfs_before(root):
if root == None: # 遇到None,说明不用继续搜索下去
return
result.append(root)
dfs_before(root.left)
dfs_before(root.right)
# 中序遍历
def dfs_middle(root):
if root == None:
return
dfs_middle(root.left)
result.append(root)
dfs_middle(root.right)
# 后序遍历
def dfs_after(root):
if root == None:
return
dfs_after(root 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 435
435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









