










注意学习这个算法需要随时可以在脑海中输出二叉树的中序遍历的序列
举例:
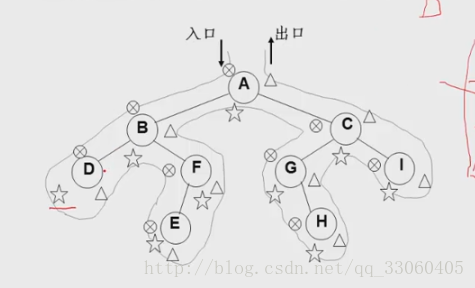
如上图,我们就看到一棵二叉树:那么我们是不是马上可以想到这棵二叉树的中序遍历序列是什么呢?
我直接给出答案:D B EF A G H C I
我们如果不适用递归中序遍历二叉树即实现输出二叉树中的全部数据并且每个节点只访问一次的操作。
那么在我们的算法中是通过单独开内存来保存节点数据,我们这个内存指的其实就是我们学过的栈数据结构Stack.
现在我们需要观察中序序列的规律来把栈数据结构应用到这个算法当中。
首先我们的中序遍历是先遍历A节点的左孩子节点在A节点在A的右孩子节点。 然后对应A的左孩子节点也就是B为根的一棵子树, 我们还是先要访问B节点的左子节点也就是D.
现在我们发现我们是访问的B,然后是A,但是输出结果确是DB, 那么我们就发现一个规律就是先访问的节点数据反而是后输出,是不是和我们的栈数据结构的先进后出相似呢。 因此我们就联系到了stack数据结构,。
下面假如我们在访问的过程就把节点入栈,直到左子节点为null,说明我们已经找到了可以输出的数据起点,这个时候刚好我是把这个数据起点保存在了栈数据结构最后一个,那么这个时候我们入栈的次顺依次是ABD。那么我们出栈就等于是开始输出中序遍历的第一个数据,我们开始出栈D,由于是中序遍历那么我们接着出栈B,这个时候不能出栈了,因为我们需要输出B节点的右子全部节点。因此我们又开始入栈F,然后是E.
然后我们在出栈栈首元素也就是E,我们用一个变量保存下来,然后输出E中的数据,接着出栈F,输出其中的数据。 这个时候我们到了A这里,我们在出栈A,在把右子树入栈。在出栈。
大家发现了没有,其实不用递归的话,我们中序遍历输出数据,用的是栈先入栈在出栈就得到数据。
现在我来贴上实现代码:
//上的代码类似伪代码
//非递归中序遍历算法 BT:保存了二叉树的地址 BT默认是根节点的地址
void InorderTraversal(BTree BT)
{
//开辟临时变量保存
BTree T =BT
//申明栈数据结构对象
Stack s = CreatStack(MaxSize); //初始化栈,默认大小为MaxSize
//使用循环中序遍历输出节点数据
while(T) //什么时候停止循环 假如T已经拿不到节点数据或者栈
{
//用一个循环来压栈
while(T) //我们需要T中保存了节点的地址才可以压栈
{
s.Push(T); //把当前节点入栈
T->left; //转向当前节点的左孩子节点
}
//在用一个循环来出栈输出数据
while(!s.Empty)
{
temp = s.Pop(); //出栈保存当前栈顶节点
//准备输出节点里的数据内容
printf("%d",T->data);
}
//转到右子树压栈
T = T->right;
if(s.Empty) //当栈当中没有元素说明已经输出全部数据,那么就要跳出循环
{
break;
}
}
}
















 1249
1249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











