




 本文介绍了如何使用TensorFlow在手机端实现文档检测,通过HED网络替代传统边缘检测算法,解决传统技术方案的局限性。文章详细探讨了HED网络的结构、训练过程、数据集创建以及在手机端运行TensorFlow的挑战,包括模型转换、裁剪和优化。此外,还讨论了OpenCV算法在神经网络之后的辅助作用。
本文介绍了如何使用TensorFlow在手机端实现文档检测,通过HED网络替代传统边缘检测算法,解决传统技术方案的局限性。文章详细探讨了HED网络的结构、训练过程、数据集创建以及在手机端运行TensorFlow的挑战,包括模型转换、裁剪和优化。此外,还讨论了OpenCV算法在神经网络之后的辅助作用。
作者:冯牮
前言
- 本文不是神经网络或机器学习的入门教学,而是通过一个真实的产品案例,展示了在手机客户端上运行一个神经网络的关键技术点
- 在卷积神经网络适用的领域里,已经出现了一些很经典的图像分类网络,比如 VGG16/VGG19,Inception v1-v4 Net,ResNet 等,这些分类网络通常又都可以作为其他算法中的基础网络结构,尤其是 VGG 网络,被很多其他的算法借鉴,本文也会使用 VGG16 的基础网络结构,但是不会对 VGG 网络做详细的入门教学
- 虽然本文不是神经网络技术的入门教程,但是仍然会给出一系列的相关入门教程和技术文档的链接,有助于进一步理解本文的内容
- 具体使用到的神经网络算法,只是本文的一个组成部分,除此之外,本文还介绍了如何裁剪 TensorFlow 静态库以便于在手机端运行,如何准备训练样本图片,以及训练神经网络时的各种技巧等等
需求是什么

需求很容易描述清楚,如上图,就是在一张图里,把矩形形状的文档的四个顶点的坐标找出来。
传统的技术方案
Google 搜索 opencv scan document,是可以找到好几篇相关的教程的,这些教程里面的技术手段,也都大同小异,关键步骤就是调用 OpenCV 里面的两个函数,cv2.Canny() 和 cv2.findContours()。
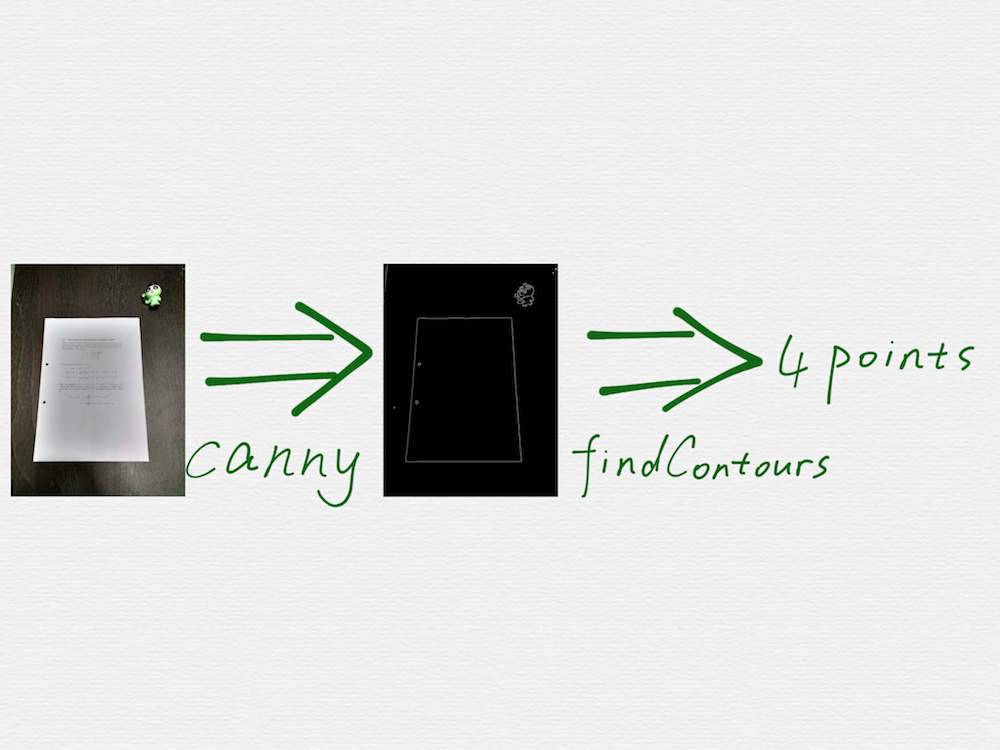
看上去很容易就能实现出来,但是真实情况是,这些教程,仅仅是个 demo 演示而已,用来演示的图片,都是最理想的简单情况,真实的场景图片会比这个复杂的多,会有各种干扰因素,调用 canny 函数得到的边缘检测结果,也会比 demo 中的情况凌乱的多,比如会检测出很多各种长短的线段,或者是文档的边缘线被截断成了好几条短的线段,线段之间还存在距离不等的空隙。另外,findContours 函数也只能检测闭合的多边形的顶点,但是并不能确保这个多边形就是一个合理的矩形。因此在我们的第一版技术方案中,对这两个关键步骤,进行了大量的改进和调优,概括起来就是:
- 改进 canny 算法的效果,增加额外的步骤,得到效果更好的边缘检测图
- 针对 canny 步骤得到的边缘图,建立一套数学算法,从边缘图中寻找出一个合理的矩形区域
传统技术方案的难度和局限性
- canny 算法的检测效果,依赖于几个阀值参数,这些阀值参数的选择,通常都是人为设置的经验值,在改进的过程中,引入额外的步骤后,通常又会引入一些新的阀值参数,同样,也是依赖于调试结果设置的经验值。整体来看,这些阀值参数的个数,不能特别的多,因为一旦太多了,就很难依赖经验值进行设置,另外,虽然有这些阀值参数,但是最终的参数只是一组或少数几组固定的组合,所以算法的鲁棒性又会打折扣,很容易遇到边缘检测效果不理想的场景
- 在边缘图上建立的数学模型很复杂,代码实现难度大,而且也会遇到算法无能为力的场景
下面这张图表,能够很好的说明上面列出的这两个问题:

这张图表的第一列是输入的 image,最后的三列(先不用看这张图表的第二列),是用三组不同阀值参数调用 canny 函数和额外的函数后得到的输出 image,可以看到,边缘检测的效果,并不总是很理想的,有些场景中,矩形的边,出现了很严重的断裂,有些边,甚至被完全擦除掉了,而另一些场景中,又会检测出很多干扰性质的长短边。可想而知,想用一个数学模型,适应这么不规则的边缘图,会是多么困难的一件事情。
思考如何改善
在第一版的技术方案中,负责的同学花费了大量的精力进行各种调优,终于取得了还不错的效果,但是,就像前面描述的那样,还是会遇到检测不出来的场景。在第一版技术方案中,遇到这种情况的时候,采用的做法是针对这些不能检测的场景,人工进行分析和调试,调整已有的一组阀值参数和算法,可能还需要加入一些其他的算法流程(可能还会引入新的一些阀值参数),然后再整合到原有的代码逻辑中。经过若干轮这样的调整后,我们发现,已经进入一个瓶颈,按照这种手段,很难进一步提高检测效果了。
既然传统的算法手段已经到极限了,那不如试试机器学习/神经网络。
无效的神经网络算法
end-to-end 直接拟合
首先想到的,就是仿照人脸对齐(face alignment)的思路,构建一个端到端(end-to-end)的网络,直接回归拟合,也就是让这个神经网络直接输出 4 个顶点的坐标,但是,经过尝试后发现,根本拟合不出来。后来仔细琢磨了一下,觉得不能直接拟合也是对的,因为:
- 除了分类(classification)问题之外,所有的需求看上去都像是一个回归(regression)问题,如果回归是万能的,学术界为啥还要去搞其他各种各样的网络模型
- face alignment 之所以可以用回归网络得到很好的拟合效果,是因为在输入 image 上先做了 bounding box 检测,缩小了人脸图像范围后,才做的 regression
- 人脸上的关键特征点,具有特别明显的统计学特征,所以 regression 可以发挥作用
- 在需要更高检测精度的场景中,其实也是用到了更复杂的网络模型来解决 face alignment 问题的
YOLO && FCN
后来还尝试过用 YOLO 网络做 Object Detection,用 FCN 网络做像素级的 Semantic Segmentation,但是结果都很不理想,比如:
- 达不到文档检测功能想要的精确度
- 网络结构复杂,运算量大,在手机上无法做到实时检测
有效的神经网络算法
前面尝试的几种神经网络算法,都不能得到想要的效果,后来换了一种思路,既然传统的技术手段里包含了两个关键的步骤,那能不能用神经网络来分别改善这两个步骤呢,经过分析发现,可以尝试用神经网络来替换 canny 算法,也就是用神经网络来对图像中的矩形区域进行边缘检测,只要这个边缘检测能够去除更多的干扰因素,那第二个步骤里面的算法也就可以变得更简单了。
神经网络的输入和输出

按照这种思路,对于神经网络部分,现在的需求变成了上图所示的样子。
HED(Holistically-Nested Edge Detection) 网络
边缘检测这种需求,在图像处理领域里面,通常叫做 Edge Detection 或 Contour Detection,按照这个思路,找到了 Holistically-Nested Edge Detection 网络模型。
HED 网络模型是在 VGG16 网络结构的基础上设计出来的,所以有必要先看看 VGG16。
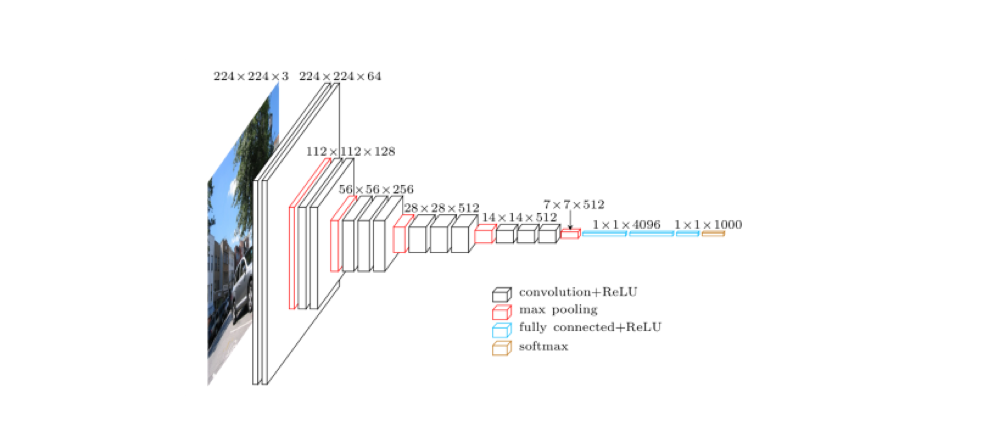
上图是 VGG16 的原理图,为了方便从 VGG16 过渡到 HED,我们先把 VGG16 变成下面这种示意图:
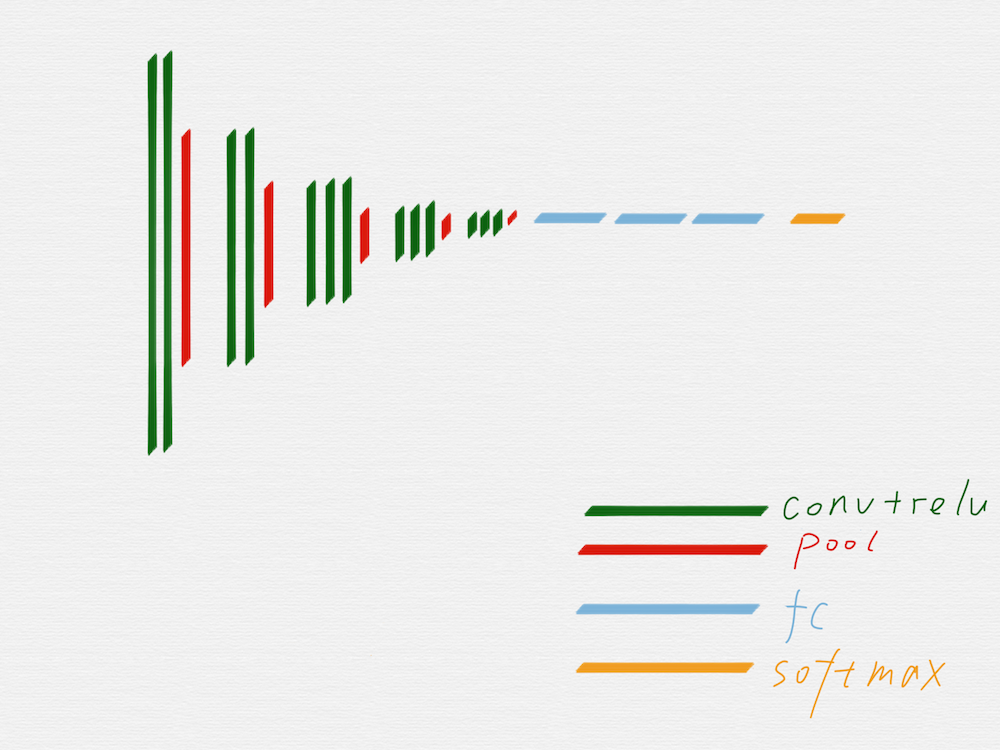
在上面这个示意图里,用不同的颜色区分了 VGG16 的不同组成部分。
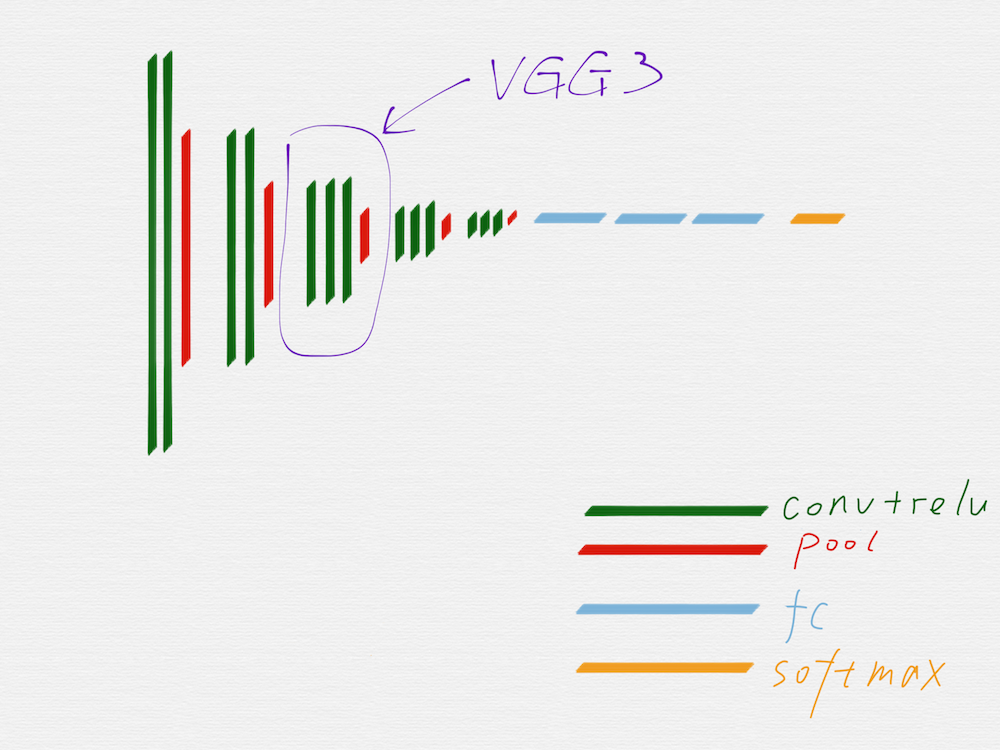
从示意图上可以看到,绿色代表的卷积层和红色代表的池化层,可以很明显的划分出五组,上图用紫色线条框出来的就是其中的第三组。
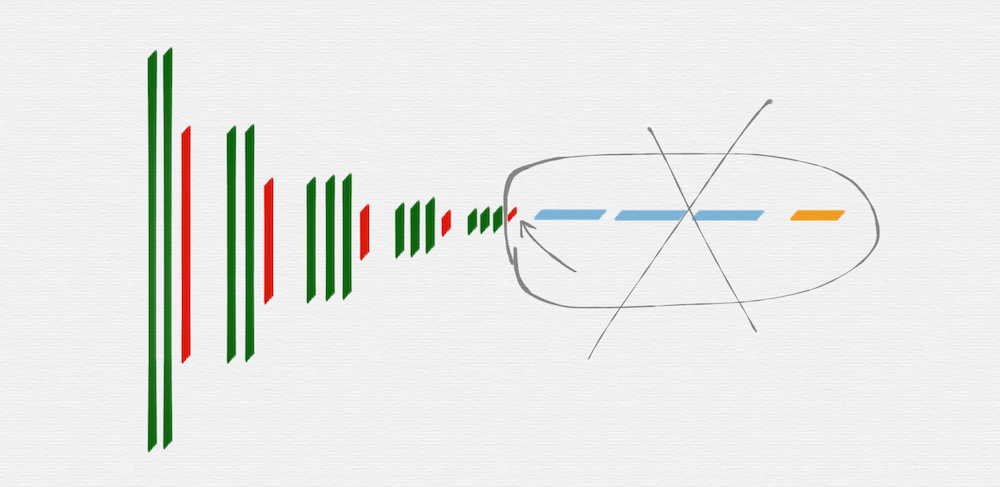
HED 网络要使用的就是 VGG16 网络里面的这五组,后面部分的 fully connected 层和 softmax 层,都是不需要的,另外,第五组的池化层(红色)也是不需要的。

去掉不需要的部分后,就得到上图这样的网络结构,因为有池化层的作用,从第二组开始,每一组的输入 image 的长宽值,都是前一组的输入 image 的长宽值的一半。
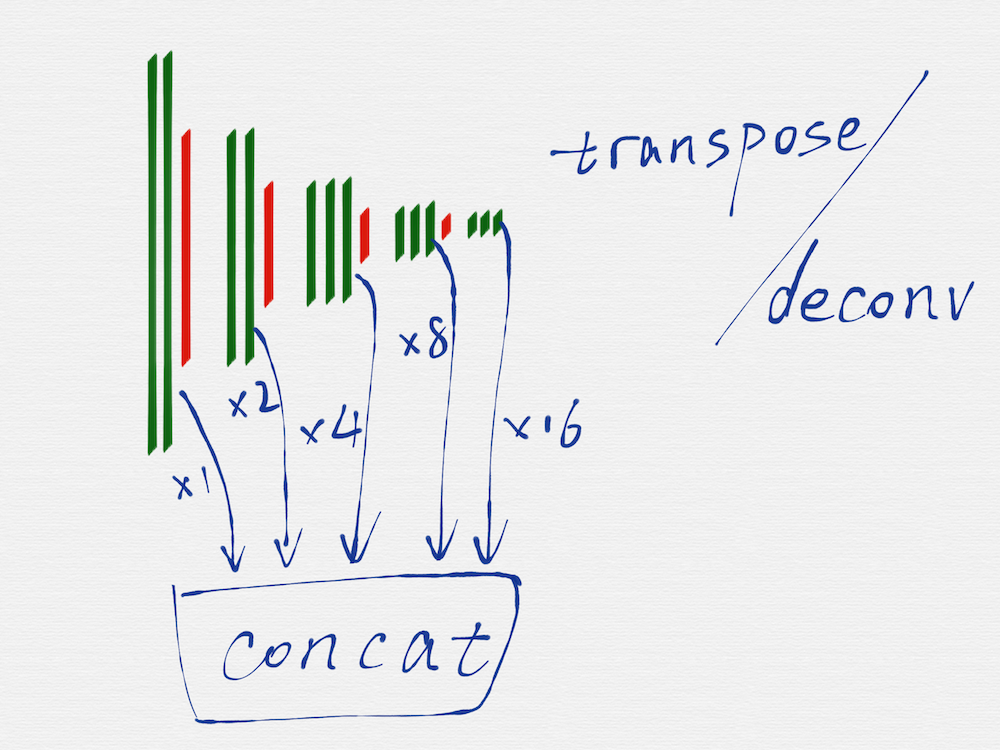
HED 网络是一种多尺度多融合(multi-scale and multi-level feature learning)的网络结构,所谓的多尺度,就是如上图所示,把 VGG16 的每一组的最后一个卷积层(绿色部分)的输出取出来,因为每一组得到的 image 的长宽尺寸是不一样的,所以这里还需要用转置卷积(transposed convolution)/反卷积(deconv)对每一组得到的 image 再做一遍运算,从效果上看,相当于把第二至五组得到的 image 的长宽尺寸分别扩大 2 至 16 倍,这样在每个尺度(VGG16 的每一组就是一个尺度)上得到的 image,都是相同的大小了。
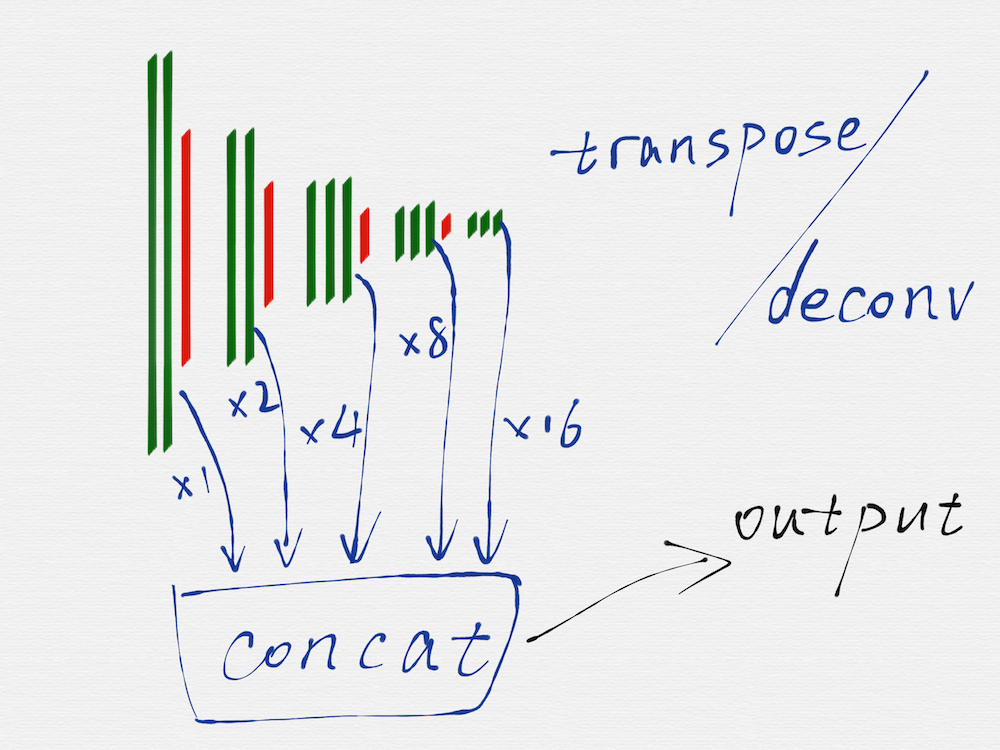
把每一个尺度上得到的相同大小的 image,再融合到一起,这样就得到了最终的输出 image,也就是具有边缘检测效果的 image。
基于 TensorFlow 编写的 HED 网络结构代码如下:
def hed_net(inputs, batch_size):
# ref https://github.com/s9xie/hed/blob/master/examples/hed/train_val.prototxt
with tf.variable_scope('hed', 'hed', [inputs]):
with slim.arg_scope([slim.conv2d, slim.fully_connected],
activation_fn=tf.nn.relu,
weights_initializer=tf.truncated_normal_initializer(0.0, 0.01),
weights_regularizer=slim.l2_regularizer(0.0005)):
# vgg16 conv && max_pool layers
net = slim.repeat(inputs, 2, slim.conv2d, 12, [3, 3], scope='conv1')
dsn1 = net
net = slim.max_pool2d(net, [2, 2], scope='pool1')
net = slim.repeat(net, 2, slim.conv2d, 24, [3, 3< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9768
9768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









