






这是一篇AI漫画软件Stable Diffusion保姆级入门教程,由于过于详细,所以图片较多,想要学习一定要有耐心,最好能直接跟着一步一步操作,保证你会有意想不到的收获。
所谓AI漫画推文,本质上来说,还是小说推文,只不过是换了一种不同的视频形式而已。不管是游戏视频、解压视频、美食视频,原则上来说都是没问题的。
那为什么还要费劲来学AI漫画推文呢?
没办法,今年做小说推文的人实在太多,而绝大部分小白刚开始做推文的时候,都是用前面说的这些视频素材,这就导致现在行业实在是太卷了,起号特别难。
而AI漫画是目前做小说推文最容易起号、效果最好的内容形式。
不过,大家一定要记住,AI漫画作图只是小说推文项目中,众多环节中的其中一个,千万不要以为做出来好看的图片,视频就一定能爆,选文和改文依然是小说推文项目中最重要的环节。
Stable Diffusion教程目录:
-
软件安装
-
界面及主要参数讲解
-
大模型和Lora加载
-
提示词写法
-
高质量出图
一、软件安装
软件安装分三种:本地安装、云端部署、云电脑。
本地安装对电脑配置要求较高,本文主要讲后两种。
什么是云电脑呢?可以简单的理解为你在网上租了一台高配电脑,里面已经把SD安装好了,你租来直接就能用。
优点是完全你不用担心安装的问题,缺点是价格比云端部署稍贵一点,为2.5元/小时;而云端部署的操作稍难一点点(其实也很简单),价格为1.58元左右/小时。
1.云电脑
云电脑我们采用的是青椒云(官网地址:https://www.qingjiaocloud.com/about/),注册登录下载客户端自己完成。
第一步,打开客户端,选择【华南4】,点击【新增云桌面】;
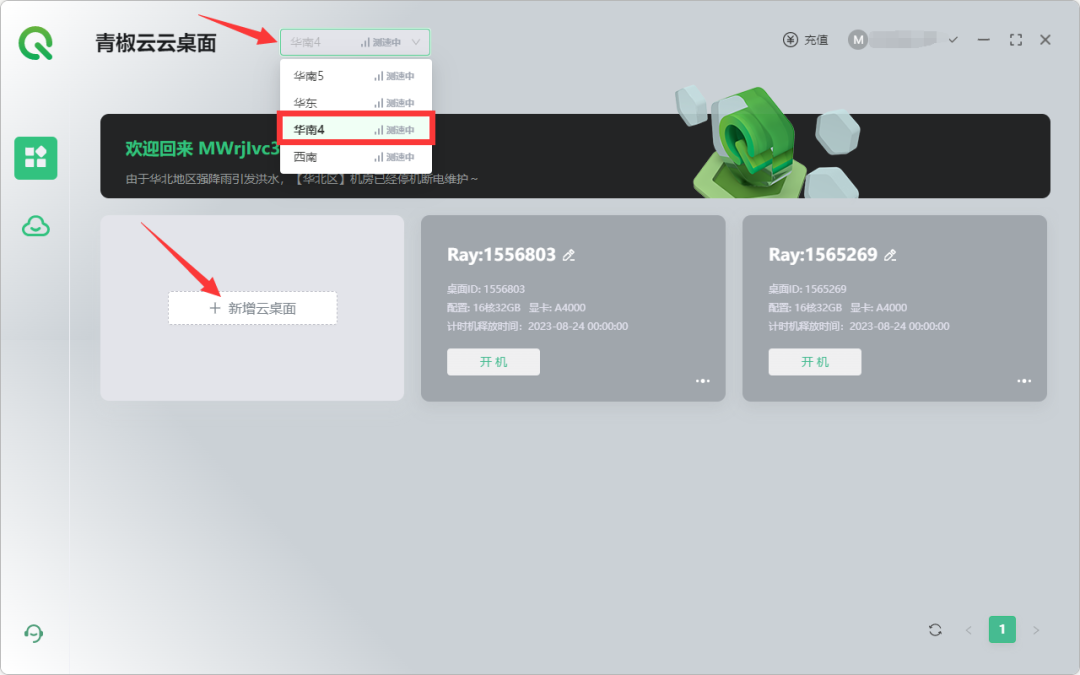
第二步,选择【定制产品】,这里大多都是一些抖音/B站/小红书等平台的博主,跟青椒云合作定制的云桌面,下拉找到【SD-绘唐定制】,点击添加。(这里不是广告,只不过我之前刚好用的是绘唐定制,所以就推荐了,也可以试试其他桌面,只要有SD就可以。)
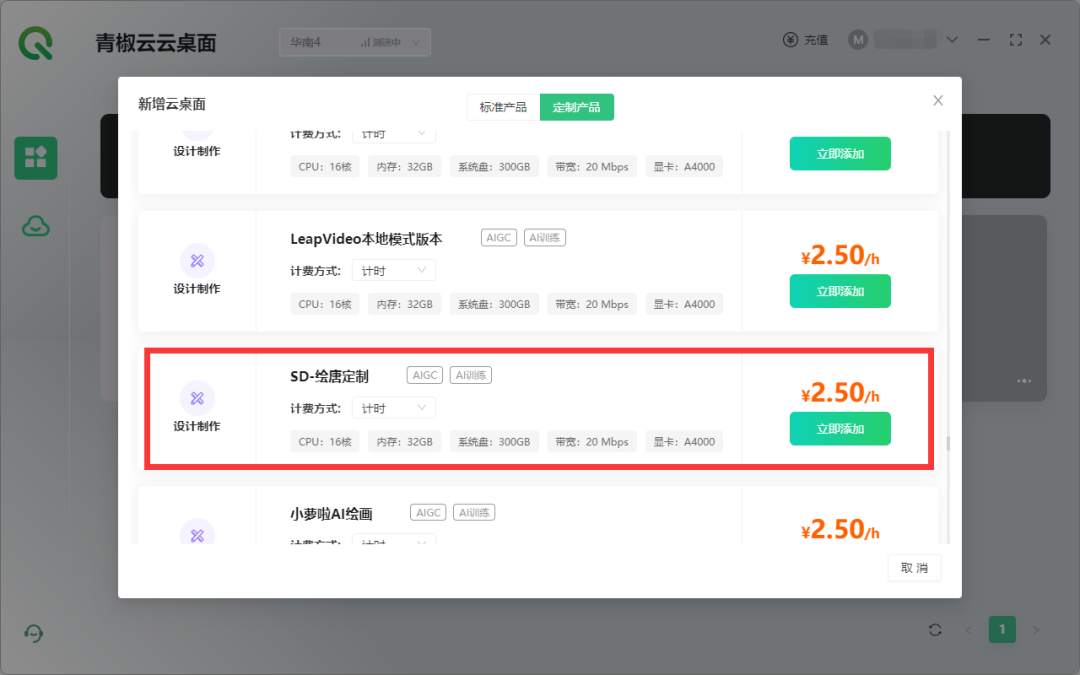
第三步,开机,进入桌面。每次用完以后记得在这个界面点击【关机】,否则会扣费!!!
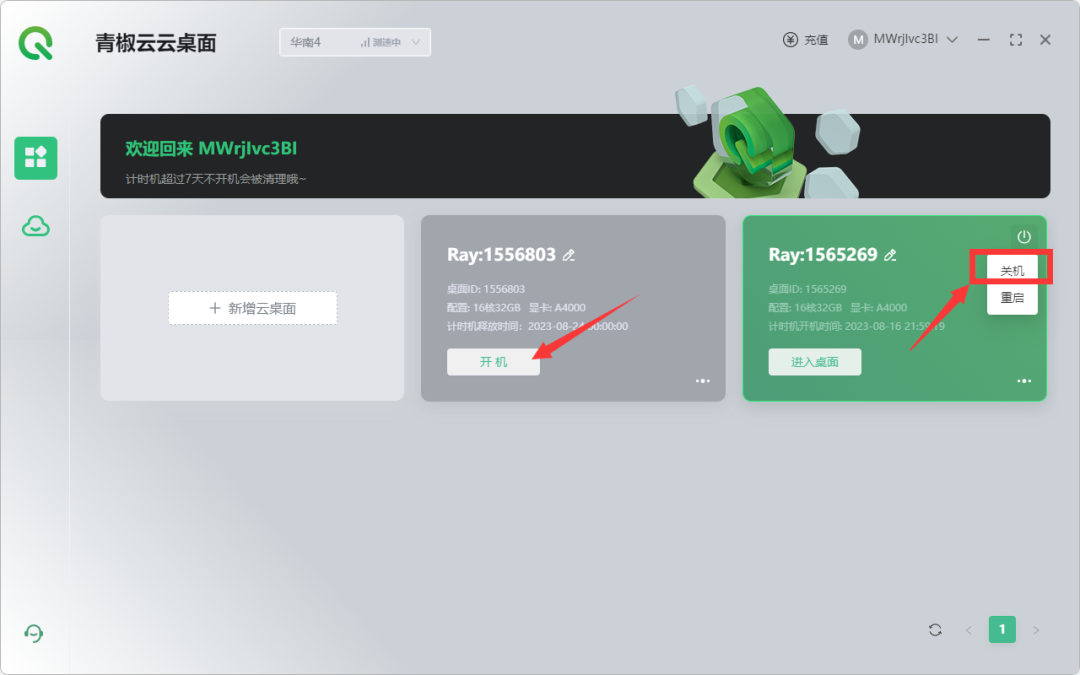
第四步,这个是绘唐的桌面,鼠标放到屏幕顶端中间,会弹出来一个选项框。【AI绘画启动器】就是SD启动器,打开,再点击【一键启动】,就可以进入SD的操作界面;
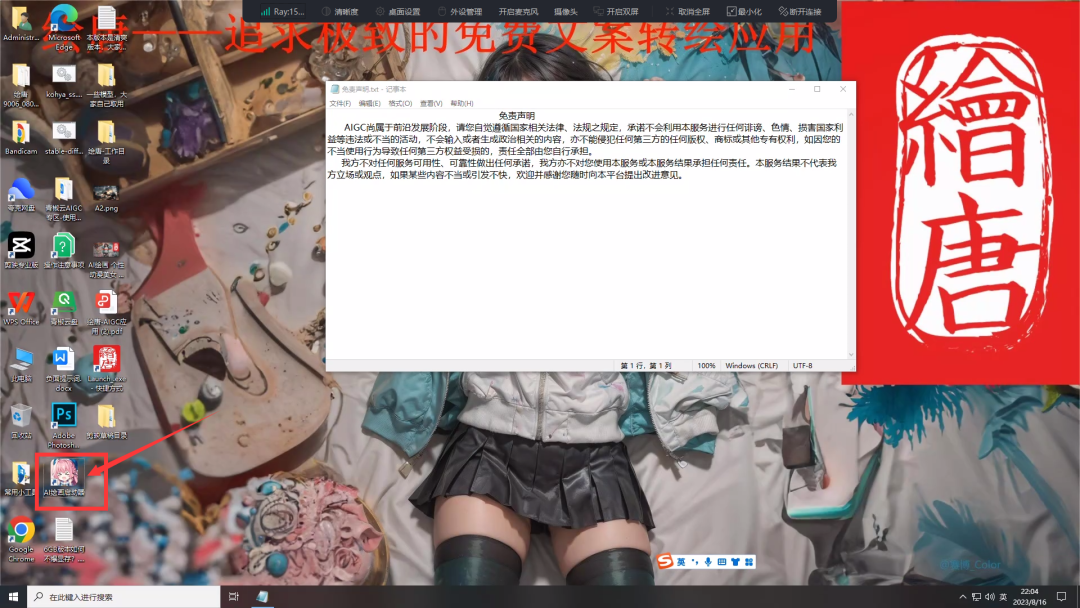
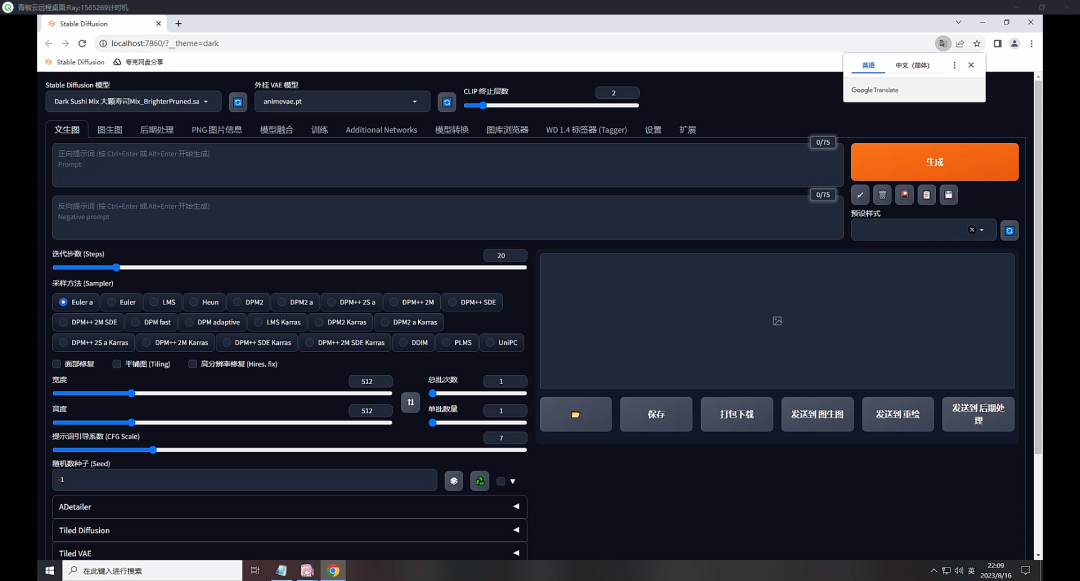
每次用完记得关机!!另外,青椒云上的机器数据保存时间为7天,如果7天没有登录,机器会被释放,所以记得要把重要数据上传云盘保存。
2.云端部署
常用的云平台有谷歌云、阿里云、AutoDL,谷歌云要开魔法,有15G免费空间,但多加载两个大模型就有点不够用了,不太推荐;这里我用AutoDL演示(官网地址:https://www.autodl.com/login),注册登录自己完成。
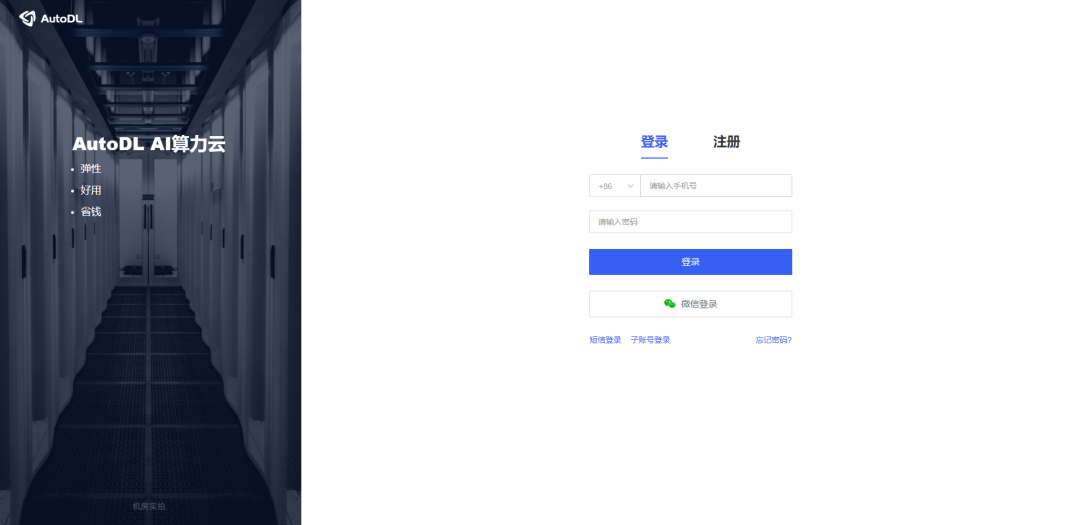
第一步,在算力市场租用服务器,选择按量计费,GPU型号选择【3090】,GPU数量选1,点击下方租用;
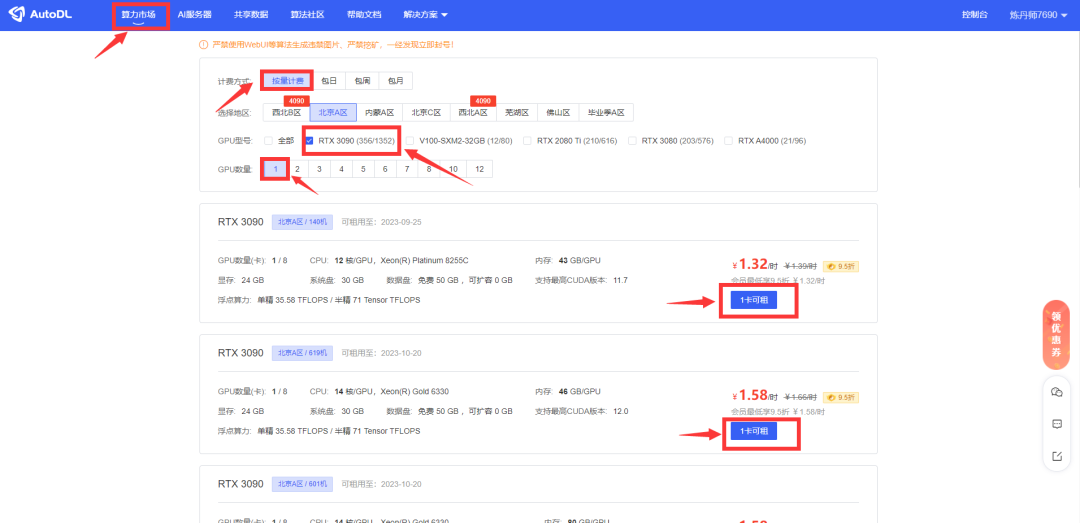
第二步,镜像选项选择【社区镜像】,输入【novelAI】,自动弹出相关的Github项目,下拉选择【xiaolxl】的【3.1:v10】这个镜像,后面的v12是新版本,原理一样。点击【立即创建】;
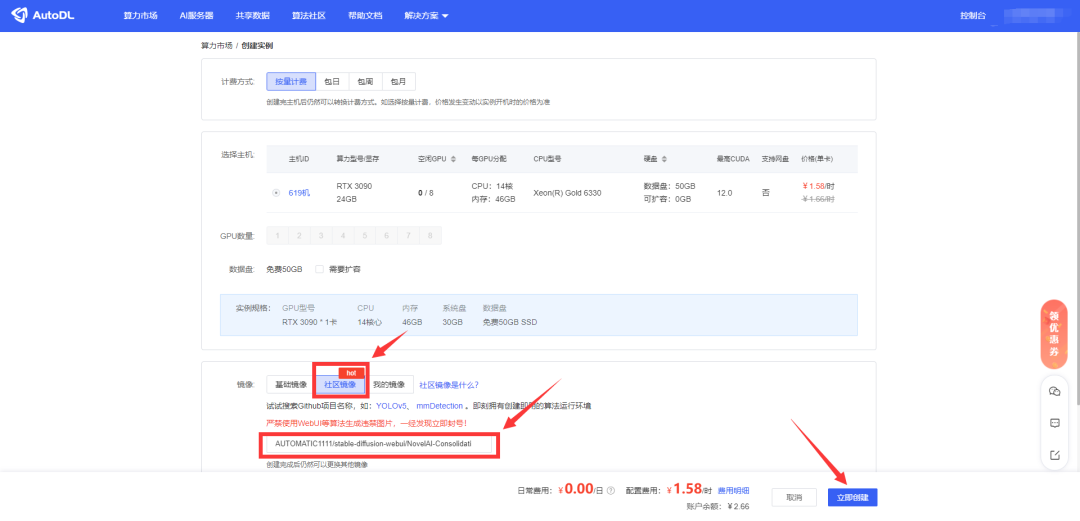
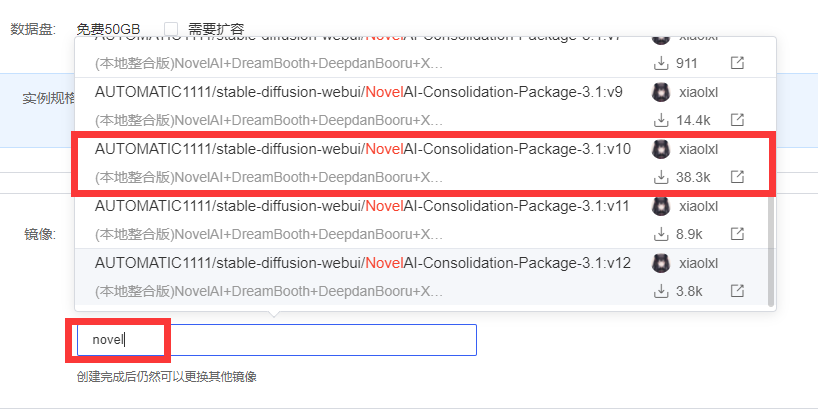
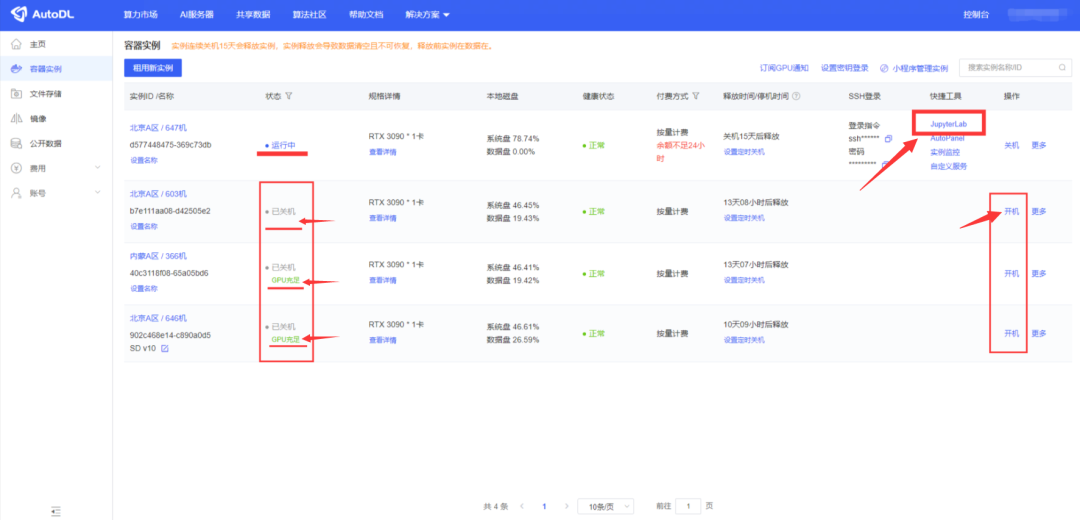
第三步,开机后会显示运行中,点击【JupyterLab】进入下一步;每次用完同样要记得点【关机】;偶尔使用时会发现GPU不足,开不了机,这时可以再重复第一步,租用一台新的;
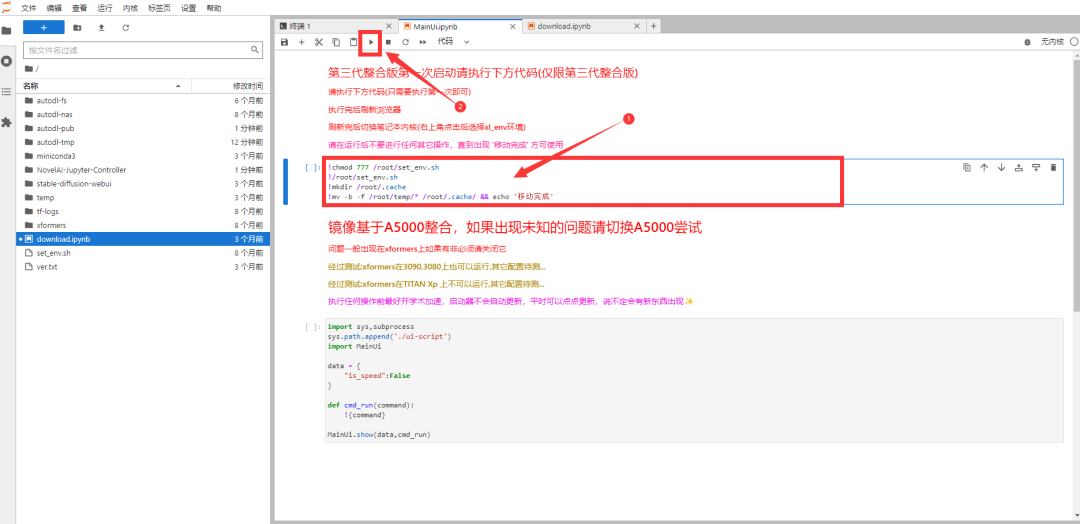
第四步,选择【第一个代码块】①,点击【运行】②;
第五步,出现【移动完成】后,然后【刷新页面】;
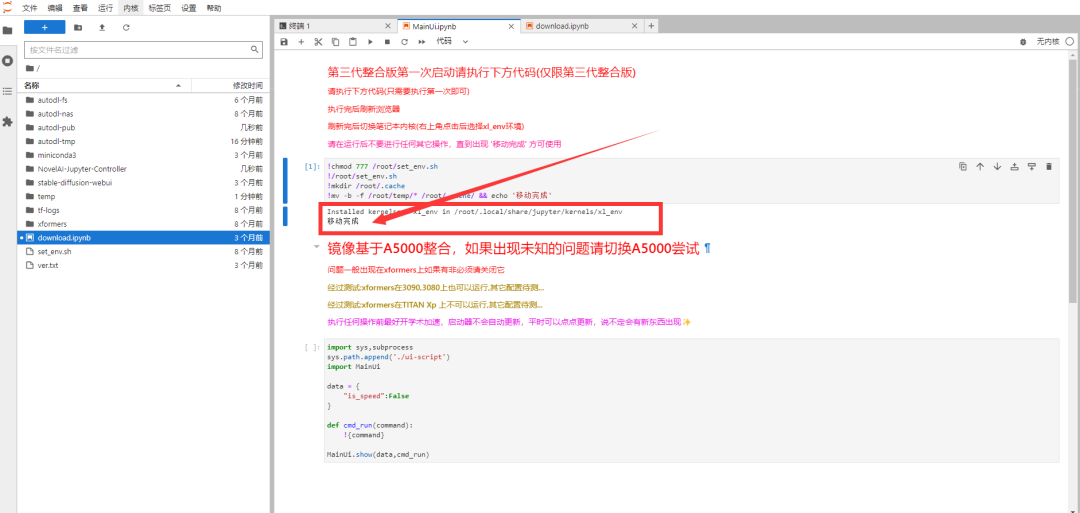

第六步,点击右上角内核,选择【xl_env】内核;
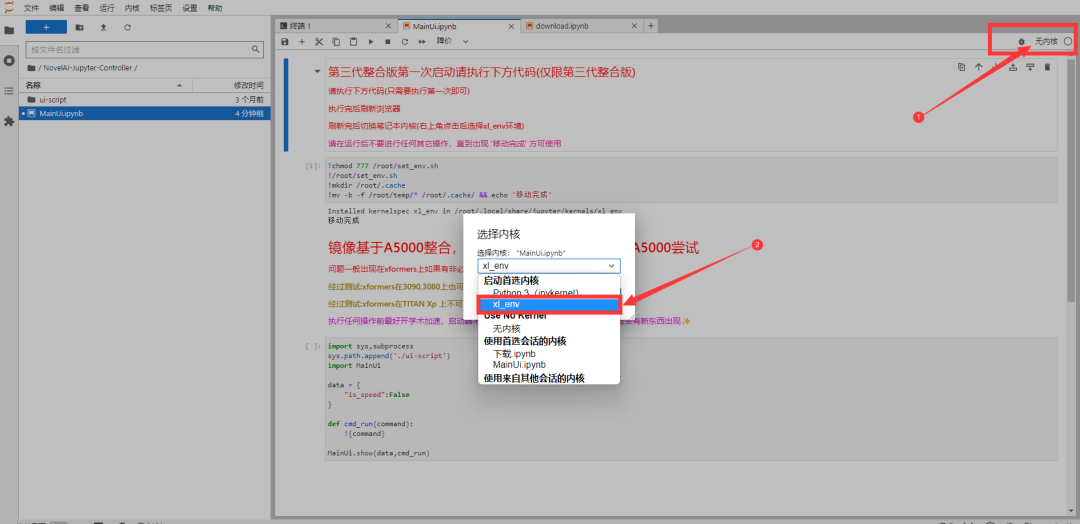
第七步,选择【第二个代码块】①,点击【运行】②,完成后,点击【点我自动学术加速】③,点击【点我移动到数据盘】④;

【内置模型下载】选项里有很多大模型可以用,这里先不下载,后面会讲其他大模型加载方法。
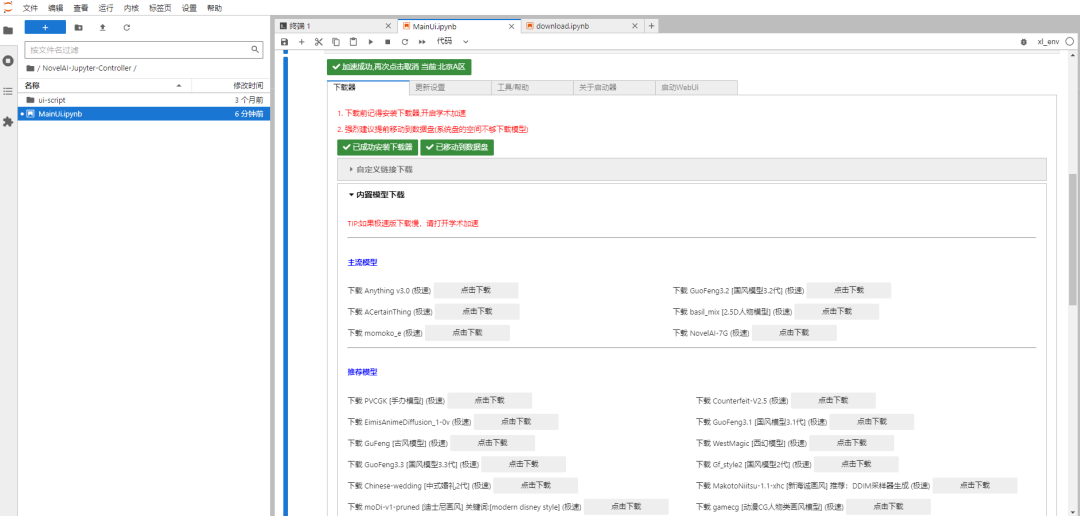
第八步,点击【更新设置】栏①,点击【更新启动器】②,下方日志出现【更新完成…】③后,【关闭窗口】④;
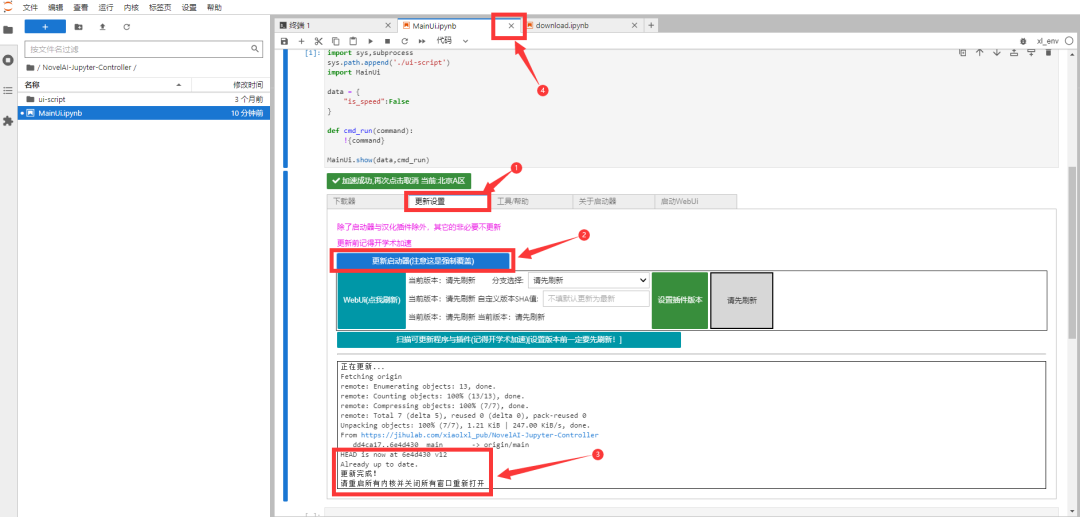
第九步,双击左侧【MainUI.ipynb】再次打开;
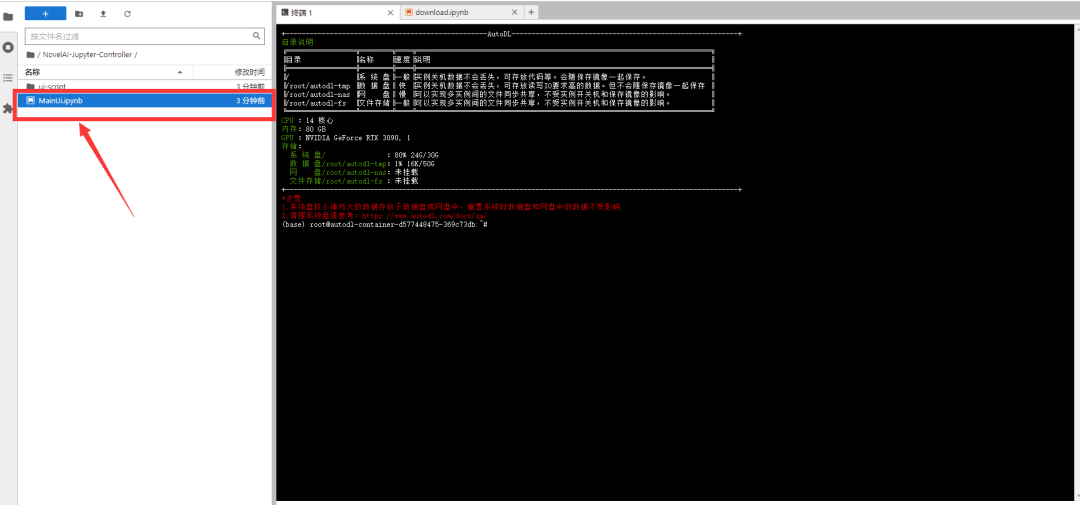
第十步,重复前面的操作:右上角选择【xl_env】内核①,选择代码块②,点击启动③;
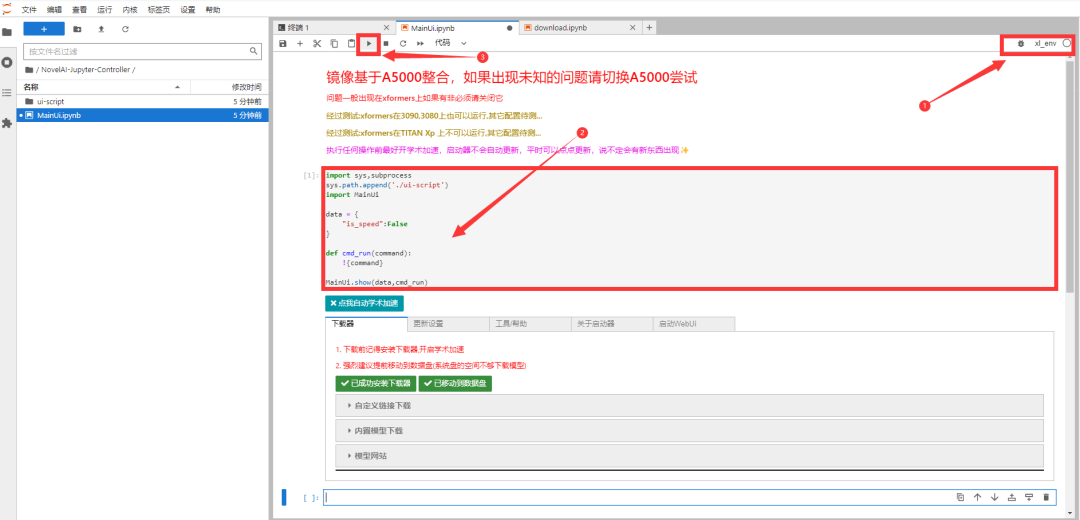
第十一步,点击【启动WebUi】栏①,照图【勾选参数】②,点击下方【运行WebUi】③,这里速度比较慢,需要等一会儿;
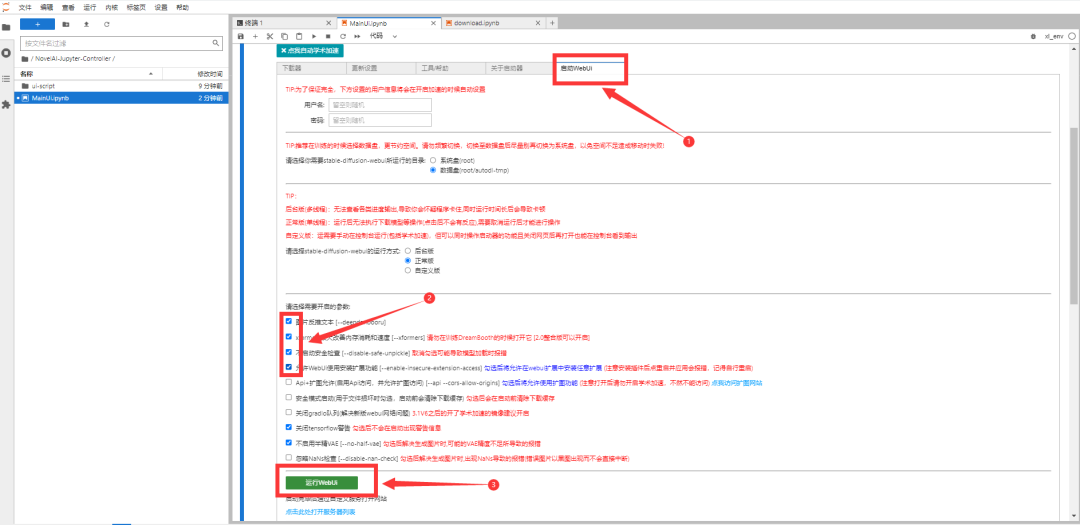
当日志里出现登录地址时,代表WebUi运行成功;
第十二步,回到主机页面,点击【自定义服务】,然后就正式进入SD的操作页面了。第一步完成!

每次用完记得关机!!!AutoDL上实例保存时间为15天,15天如果不开机,系统会自动释放。
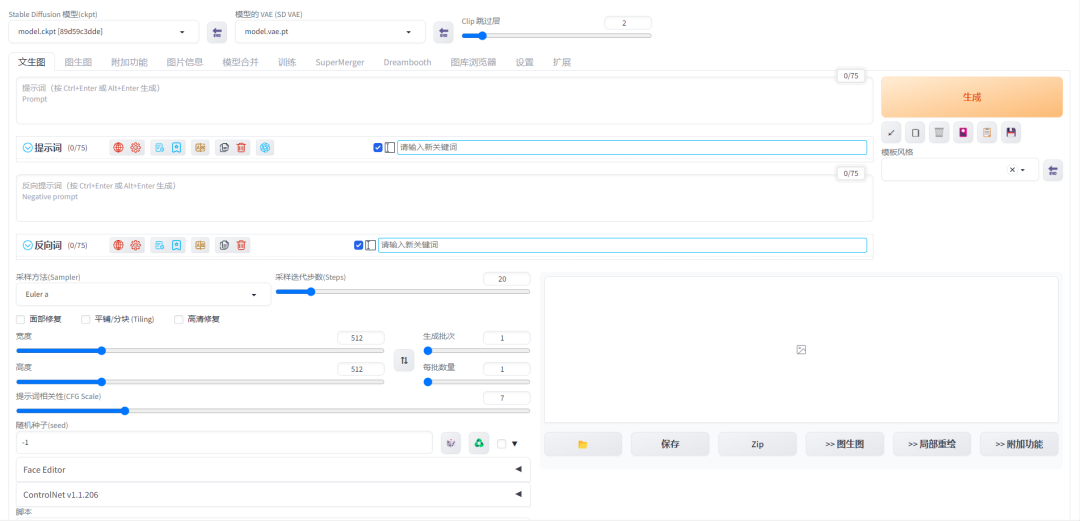
二、界面及主要参数讲解
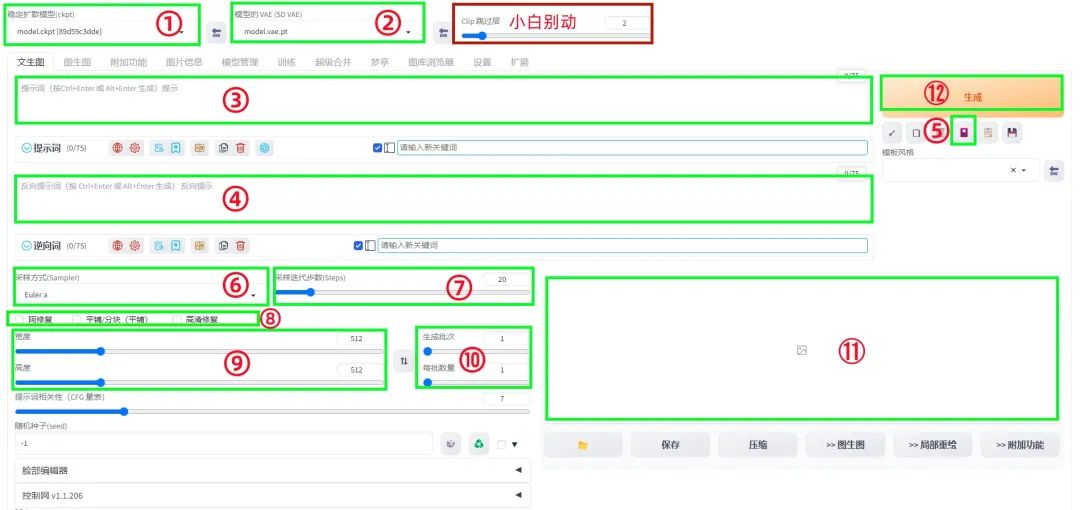
①:大模型,决定图片整体风格基调,如写实、古风、动漫等等;
②:外挂VAE,有的大模型有自己对应的VAE,推荐:animevae、840000;
③:正向提示词,关键词,希望画面中出现的元素;
④:反向提示词,不希望不出现的元素;
⑤:LORA,对模型进行微调,可以用来固定人物形象、动作等,比如给男主女主用单独的Lora;
⑥:采样方式,去噪,推荐:Euler a、DPM++ SDE Karras、DPM++ 2M Karras;
⑦:迭代步数,数值越高,图片越精致,用时就越长,常用:20-30步;
⑧:面部修复/高清修复,让图片更清晰,耗时更长,第一次出图先不勾选,当出图符合预期时再打开;
⑨:图片大小,不要太大,吃显存,常用512*512、512*768(竖版);
⑩:生成批次/每批次数,即生成几次,一次生成几张,常用:4/1;
⑪:生成的图片显示区域;
⑫:点击生成图片。
三、大模型和Lora加载
**模型决定了图片整体的风格基调,对图片的效果影响非常大,**比如有写实类、国风类、动漫类、科幻类等等各种不同风格的模型。
模型对画面影响有多大,看看下面两组图就明白了。画一个夜晚在街上穿着白T短裙的红头发女孩,图1用的大颗寿司Mix模型,图2用的麦橘写实模型,其他参数不变,但出来的两组图风格完全不一样。


LORA会对模型进行微调,可以用来固定人物形象、画风、动作等等。比如:图1是一个女孩子,但给她加上了图2的[古惑男01]Lora后,同样的关键词和参数,画面就变成了图3的样子。


所以,想要出图效果好,选择风格合适的模型、LORA非常重要。
常用的模型和LORA下载网站有C站(要魔法)、哩布、吐司等,各种各样的模型和LORA应有尽有。
资料包里也精选了一些常用的优质模型和LORA,文末自行扫描获取。
四、提示词写法
提示词直接决定了画面的内容和质量,准确的提示词能够帮我们画出更理想的图片。
1.提示词分为正向提示词和负向提示词,正向提示词就是我们想要的效果,而负向提示词则是不希望画面中出现的元素。
它能识别英文、数字、符号、表情;英文能识别单词和短句,SD对单词的理解能力更强,所以我们的提示词,尽量拆成单词。
2.提示词语序为:画面质量-主要元素-细节。
拆得更详细一些就是:图像质量/风格/镜头/灯光/构图,人物/动物/事物/风景/姿态/服装/道具,场景/环境/细小元素。
刚接触SD可能会觉得不好理解,可以简单的理解为先大后小,再简化一点就是:
人物主体特征,服饰穿搭,发型发色,五官特征,面部表情,肢体动作,
场景特征,室内或者室外,大场景,小细节,环境光照,镜头视角。
3.当我们需要强调某个提示词时,可以使用符号()或(提示词:1.2)来对增加该提示词的权重。
比如:
(提示词)=提示词×1.1;
(提示词:1.2)=提示词×1.2。
通用正向提示词:
提升画质:masterpiece,4K,High Quality,realistic,contrast,
负面提示词:
nsfw,sketches,(worst quality:2),(low quality:2),lowres, ((monochrome)), ((grayscale)),skin spots,acnes,skin blemishes,bad anatomy,(long hair:1.4),DeepNegative,(fat:1.2),facing away,looking away,tilted head, lowres,bad anatomy,bad hands, text, error, missing fingers,extra digit, fewer digits,cropped,worstquality, low quality, ,jpegartifacts,signature, watermark,username,blurry,bad feet,cropped,poorly drawn hands,poorly drawn face,mutation,deformed,worst quality,low quality,normal quality,jpeg artifacts,signature,watermark,extra fingers,fewer digits,extra limbs,extra arms,extra legs,malformed limbs,fused fingers,too many fingers,long neck,cross-eyed,mutated hands,polar lowres,bad body,bad proportions,gross proportions,text,error,missing fingers,missing arms,missing legs,extra digit, extra arms, extra leg, extra foot,
五、高质量出图
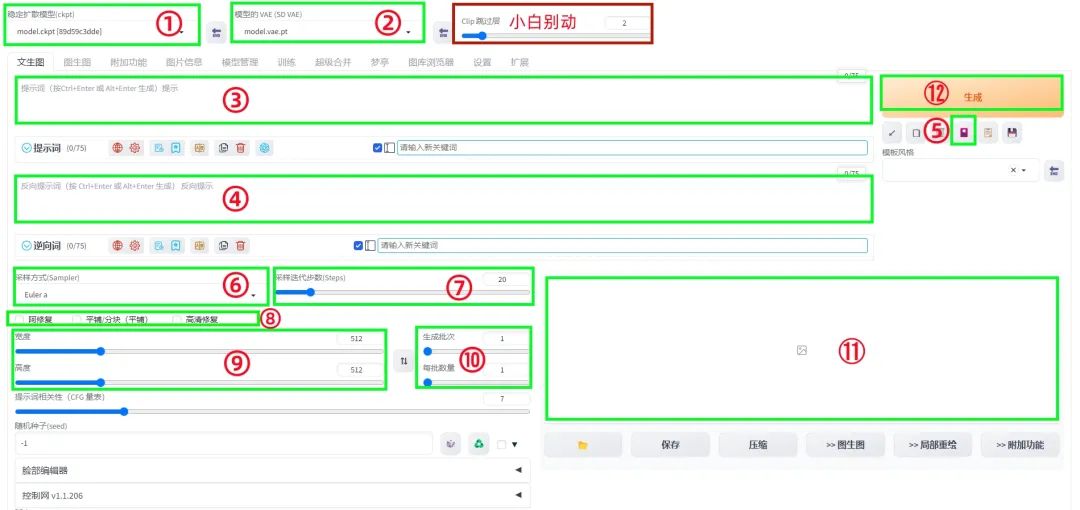
前面讲的模型、LORA、提示词都会影响到画面的质量,除了之外,其他参数同样会对图片的质量有影响。
第一次出图时,位置⑧里的面部修复和高清修复先不勾选,位置⑦步数填20,位置⑨图片大小可以默认512*512,或者512*768(竖版),位置⑩生成批次4,每批数量1。
SD每次出图都有随机性,如果出图效果不理想,可以多生成几次,或者尝试修改提示词后,再生成。
每次出4张图,当里面出现整体画风合适、但细节有瑕疵的图片时,可以单独选中这张图,再进行二次绘制,二次绘制的方法:
⑦步数填30,⑧处勾选面部修复和高清修复,⑩生成批次1,重绘幅度0.5,随机种子数点击绿色按钮(高清修复后随机种子数记得改回-1)。
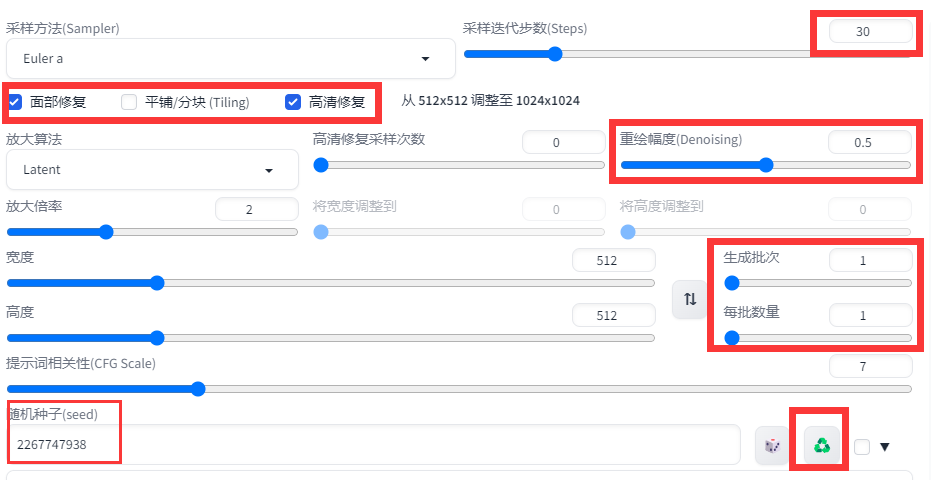
由于打开面部修复和高清修复后,图片生成时间会变长,如果要做的图很多,也可以先把你选中的图片存到本地,最后利用网盘资料包里的[图片画质增强器],在本地统一对图片进行高清修复。
写在最后:
1.如今AI技术发展日新月异,但其实绝大部分离普通人依旧很遥远,有人会趁机利用信息差,过分鼓吹AI技术,制造焦虑割韭菜,大家自己擦亮眼睛。
2.本文仅仅是Stable Diffusion的入门,如果想要更深度的学习,B站等平台有很多专业大佬出的免费教程,大家可以自己学习。
3.AI漫画作图作为小说推文项目的一环,还是那几句话,选文和改文是最重要的,如果能把选文、改文、AI绘图三个环节都做到极致,你不爆单我都不信!
资料软件免费放送
次日同一发放请耐心等待
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

**一、AIGC所有方向的学习路线**
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
















 1301
1301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









