






大家好我是阿道夫!!!在人工智能领域,扩散模型(Diffusion Model)的推理速度一直是技术挑战的重点。英伟达推出的AlignYourSteps,是一款专门为加速SD和SVD推理速度而设计的工具,同时优化了扩散模型的采样计划。现在,我们为你带来ComfyUI工作流,帮助你更好地利用AlignYourSteps的强大功能。
扩散模(DMs)已成为视觉领域领域最先进生成建模方法。然而,DMs有一个关键缺点就是采样速率慢,依赖于通过大型神经网络的许多顺序函数评估。从DMs采样可以看作是通过称为采样schedules的离散噪声水平集解决微分方程。虽然过去的工作主要集中在推导高效求解器上,但很少有研究关注寻找最优采样schedules,几乎所有文献方法都依赖于手工制作(hand-crafted)的启发式方法。
因此,英伟达研究团队首次提出了一种通用和原则性的方法: “Align Your Steps” 方法。用于优化DMs的采样schedules以产生高质量的输出。利用随机微积分方法,为不同的求解器、训练有素的DMs和数据集找到特定的最优schedules。
研究团队在多个图像、视频以及2D玩具数据合成基准上评估了 “Align Your Steps” 新方法,使用不同的求解器,并观察到优化的schedules在几乎所有实验中都优于以前的手工制作(hand-crafted)schedules。评估实验结果,展示了采样schedules优化的未开发潜力,特别是在少步骤合成领域。并且 “Align Your Steps” 的优化schedules可以在推理时以即插即用的方式使用。
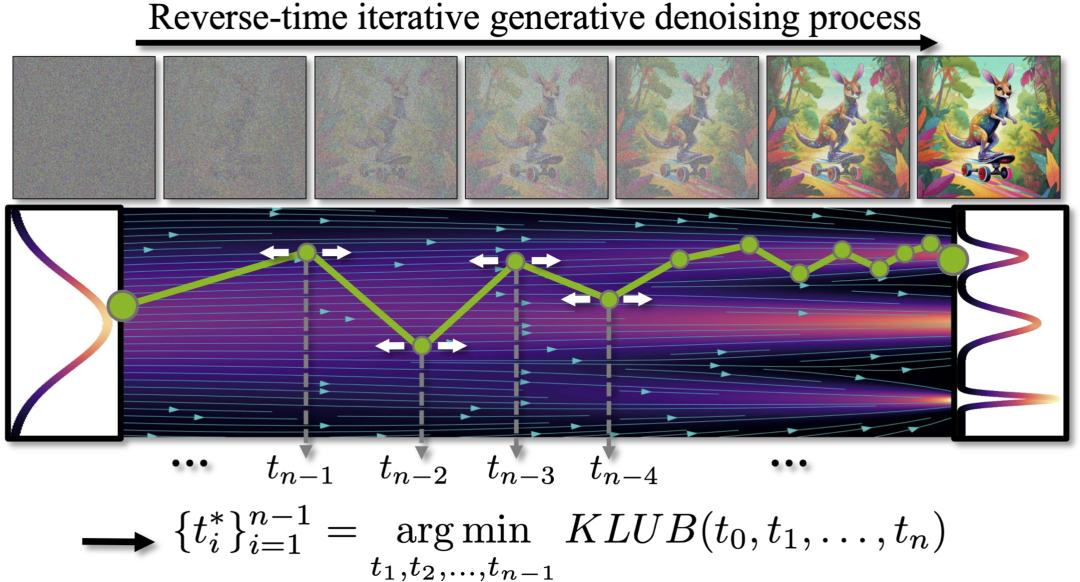
优化扩散模型中的采样schedules
扩散模型(DMs)在图像领域已经被证明是非常可靠的概率生成模型,能够产生高质量的数据。它们已成功应用于图像合成、图像超分辨率、图像到图像的转换、图像编辑、修复、视频合成、文本到3D生成,甚至是规划等应用。然而,从DMs采样相当于在反向时间中解决一个生成随机或常微分方程(SDE/ODE),并且需要通过大型神经网络进行多次顺序前向传递,这限制了它们的实时应用性。
在时间间隔内解决SDE/ODEs的工作原理是将其离散化为称为采样schedules的更小的子间隔,并对连续值之间的微分方程进行数值求解。目前,大多数先前的工作采用一些启发式schedules,例如简单的多项式和余弦函数,很少有工作致力于优化这个schedules。研究团队尝试通过引入一种原则性的方法来优化特定于数据集和模型的schedules,从而在相同的计算预算下获得改进的输出。
假设表示精确运行反向时间SDE(由学习到的模型定义)的分布,而表示使用随机Stochastic-DDIM和sampling schedule解决它的分布,可以使用Girsanov定理推导出这两种分布之间Kullback-Leibler散度的上界。
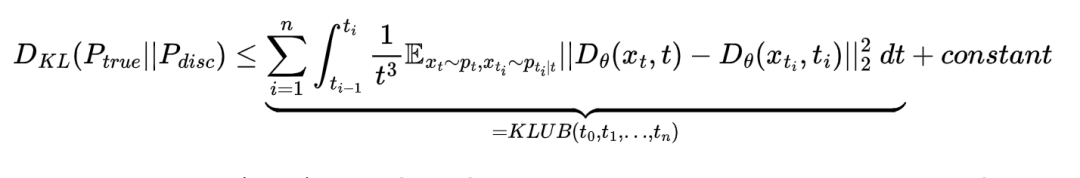
对于其他随机SDE求解器,可以找到类似的Kullback-Leibler上界(KLUB)。因此,将优化采样schedules的问题表述为最小化其时间离散化的KLUB项,即采样schedules。使用蒙特卡洛积分和重要性抽样来估计期望值,并对schedules进行迭代优化。同时也能够在2D玩具分布上展示体现出优化schedules的优势。
Align Your Steps评估实验
为了评估优化schedules的实用性,研究团队在标准的图像生成基准(CIFAR10、FFHQ、ImageNet)上进行了严格的定量实验,并发现这些schedules在图像质量(通过FID测量)方面一致改进了各种流行的采样器。同时还对文本到图像模型(特别是Stable Diffusion 1.5)进行了用户研究,并发现使用这些schedules生成的图像更受欢迎。
以下是一些文本到图像的示例,展示了使用优化schedule如何在相同数量的前向评估(NFEs)下生成具有更多视觉细节和更好文本对齐的图像。这里提供了优化的schedules与两种最流行的实践schedules(EDM和Time-Uniform)的比较结果。所有图像都是使用10步的随机(stochastic)或确定性(deterministic)版本的DPM-Solver++(2M)生成的。
Stable Diffusion 1.5
01. 图书馆
1girl, blue dress, blue hair, ponytail, studying at the library, focused

02. 森林小径
An enchanting forest path with sunlight filtering through the dense canopy, highlighting the vibrant greens and the soft, mossy floor

03. 彩色玻璃花瓶
A glass-blown vase with a complex swirl of colors, illuminated by sunlight, casting a mosaic of shadows on a white table

DeepFloyd-IF
01. 夜空
Long-exposure night photography of a starry sky over a mountain range, with light trails

02. 太空港
AA bustling spaceport on a distant planet, with ships of various designs taking off against a backdrop of twin moons

SDXL
01. 建筑工人-虎

02. 赛博朋克-城市
Cyberpunk cityscape with towering skyscrapers, neon signs, and flying cars

Stable Video Diffusion
同时研究团队还研究了在视频生成中使用优化schedules的效果,使用开源图像到视频模型Stable Video Diffusion。发现使用优化schedules可以生成更稳定的视频,并随着视频的进行减少颜色失真。下面展示了使用两种不同schedules生成的10步DDIM的视频的并排比较。
Align Your Steps体验
在项目主页中也提供了使用手册,在这里笔者使用Colab在线体验:https://github.com/greengerong/awesome-llm/blob/main/colab/img/Align_your_steps_sdxl.ipynb
注:最新版的ConfyUI也支持了,需要更新到最新版本,选择ASY schedules。感兴趣的同学可用ComfyUI体验(工作流文件文末获取)。

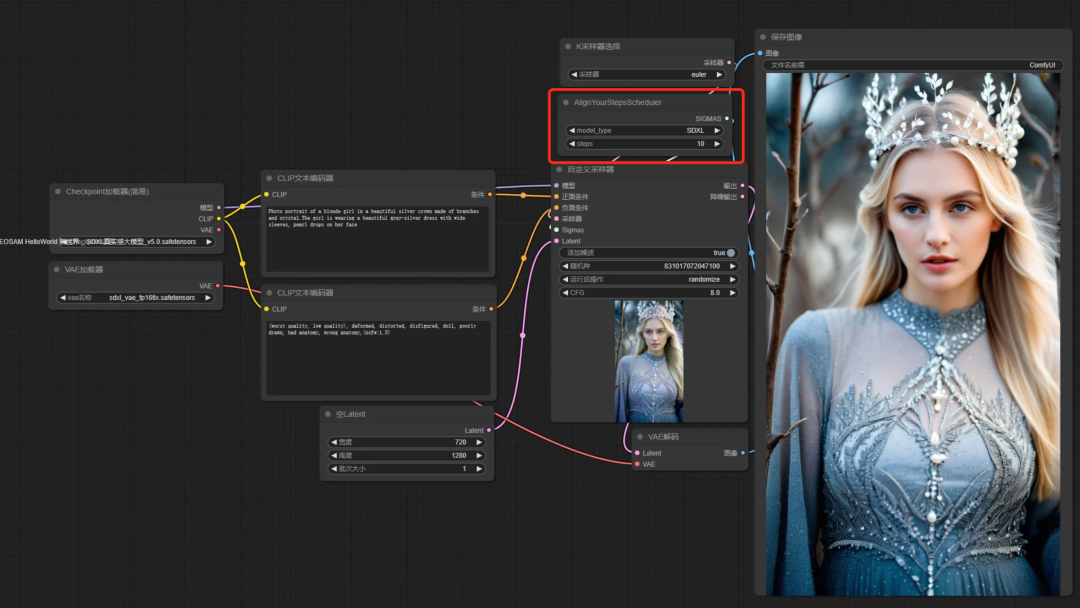
环境安装
%%capture
!pip install -q diffusers accelerate
自定义DPMSolverMultistepScheduler
由于默认的 DPMSolverMultistepScheduler 不支持设置自定义计划。因此,增加 StableDiffusionPipeline 中的 timesteps 参数来传递我们的自定义计划。
import torch
import numpy as np
from diffusers import StableDiffusionPipeline
from diffusers.utils import make_image_grid
from IPython.display import display
from diffusers import DPMSolverMultistepScheduler as DefaultDPMSolver
# Add support for setting custom timesteps
class DPMSolverMultistepScheduler(DefaultDPMSolver):
def set_timesteps(
self, num_inference_steps=None, device=None,
timesteps=None
):
if timesteps is None:
super().set_timesteps(num_inference_steps, device)
return
all_sigmas = np.array(((1 - self.alphas_cumprod) / self.alphas_cumprod) ** 0.5)
self.sigmas = torch.from_numpy(all_sigmas[timesteps])
self.timesteps = torch.tensor(timesteps[:-1]).to(device=device, dtype=torch.int64) # Ignore the last 0
self.num_inference_steps = len(timesteps)
self.model_outputs = [
None,
] * self.config.solver_order
self.lower_order_nums = 0
# add an index counter for schedulers that allow duplicated timesteps
self._step_index = None
self._begin_index = None
self.sigmas = self.sigmas.to("cpu") # to avoid too much CPU/GPU communication
推理
`from diffusers import StableDiffusionXLPipeline, AutoencoderKL`
`vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16) pipe = StableDiffusionXLPipeline.from_pretrained( "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True, vae=vae, add_watermarker=False, ).to("cuda") pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config) seed = 20 num_steps = 10 sampling_schedule = [999, 845, 730, 587, 443, 310, 193, 116, 53, 13, 0] # prompt = "a photo of an astronaut riding a horse on mars" # prompt = "(venus,goddess),(pink and white entanglement),Masterpiece, beautiful details, uniform 8K wallpaper, high resolution,perfect light,glowing eye,(purple and golden entanglement), (crystal and silver entanglement),Crystal Blue,details,High quality,sfw" prompt = "[提示语]" negative_prompt = "[负向提示语] # Default schedule torch.manual_seed(seed) default_images = pipe( prompt, negative_prompt=negative_prompt, num_images_per_prompt=4, num_inference_steps=num_steps, ).images display(make_image_grid(default_images, rows=1, cols=len(default_images))) # AYS schedule torch.manual_seed(seed) ays_images = pipe( prompt, negative_prompt=negative_prompt, num_images_per_prompt=4, timesteps=sampling_schedule, ).images display(make_image_grid(ays_images, rows=1, cols=len(ays_images)))`
输出效果
01. 天使女神
(venus,goddess),(pink and white entanglement),Masterpiece, beautiful details, uniform 8K wallpaper, high resolution,perfect light,glowing eye,(purple and golden entanglement), (crystal and silver entanglement),Crystal Blue,details,High quality,sfw
默认Schedule:
 AYS Schedule:
AYS Schedule:
02. 超现实模特
`A hyperrealistic model with delicate, watercolor-inspired makeup, soft pastel washes on the eyelids and cheeks, against an ethereal, blurred floral background. The gentle, diffuse lighting enhances the watercolor effect, creating a dreamy, serene atmosphere. Created Using: DSLR camera, macro lens for detailed close-ups, watercolor makeup techniques, natural light with reflectors, high dynamic range imaging, natural style`
默认Schedule:
 AYS Schedule:
AYS Schedule:
最后,经过笔者实测,在图像质量细微并不是特别大的细节质量的变化,出图速率快了2秒。在svd视频生成或许更快。这对于低显存硬件算提升,对于足够显存硬件没有太大区别。不过寻找最优采样schedules,是一个值得探索的理论方法和路径。
资料软件免费放送
次日同一发放请耐心等待
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。
需要的可以扫描下方CSDN官方认证二维码免费领取【保证100%免费】

**一、AIGC所有方向的学习路线**
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
















 1157
1157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









