






大家好我是AIGC阿道夫
之前我曾经多次介绍过,可以一键生成视频的模型。包括能够有效解决视频闪烁的Rerender A Video模型
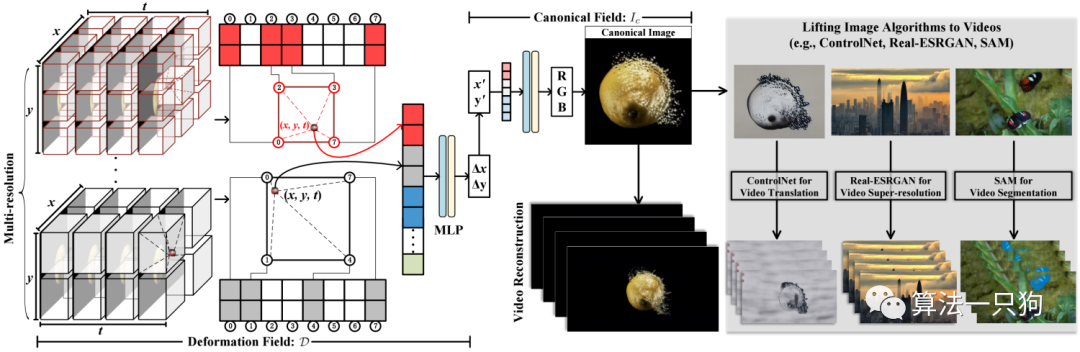
还有开源的CoDeF模型 :
这些模型要不就是没有开源,要不就是有一定的上手难度。因此本期介绍简单易上手的Stable Video Diffusion。
它是由Stability AI发布的,一个基于图像模型稳定扩散的生成视频模型。
目前它已经提供了相应的模型和开源代码,普通人可以在20秒内简单上手。

Stability AI宣称,该视频模型可以轻松适应各种下游任务,包括通过对多视图数据集进行微调,或者从单个图像进行多视图合成。

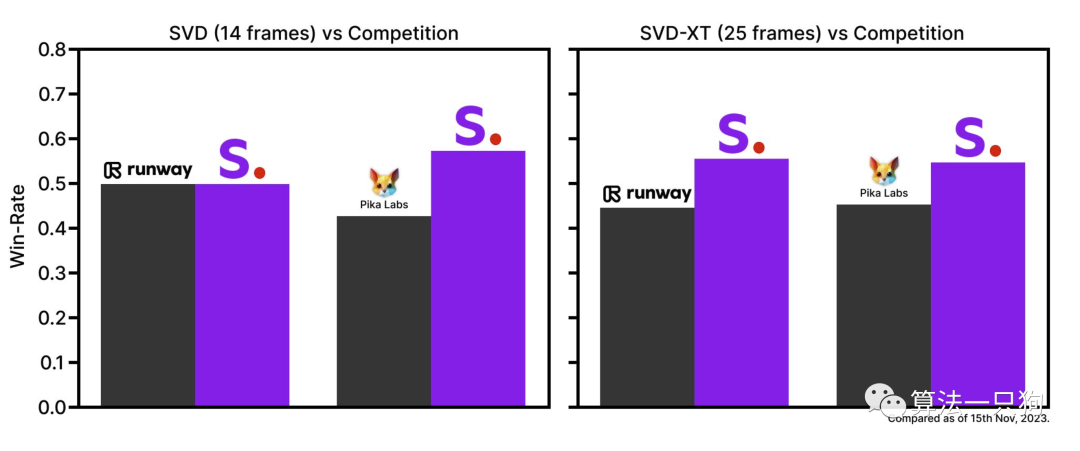
稳定视频扩散以两种图像到视频模型的形式发布,能够以每秒 3 到 30 帧之间的可定制帧速率生成 14 和 25
帧。在不同模型对比来看,SVD模型比目前尚未开源的一些模型效果要好:
手把手教学
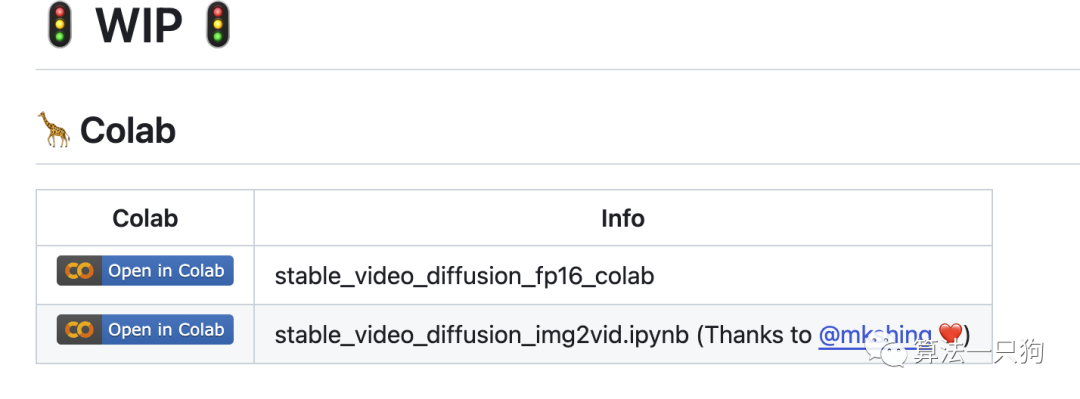
目前可以直接使用C solab尝试一下该模型生成的效果。可以登陆网站
https://github.com/camenduru/stable-video-diffusion-colab
点击下面任意一个代码链接Colab:
点击运行后,可以看到会生成一个网页链接:
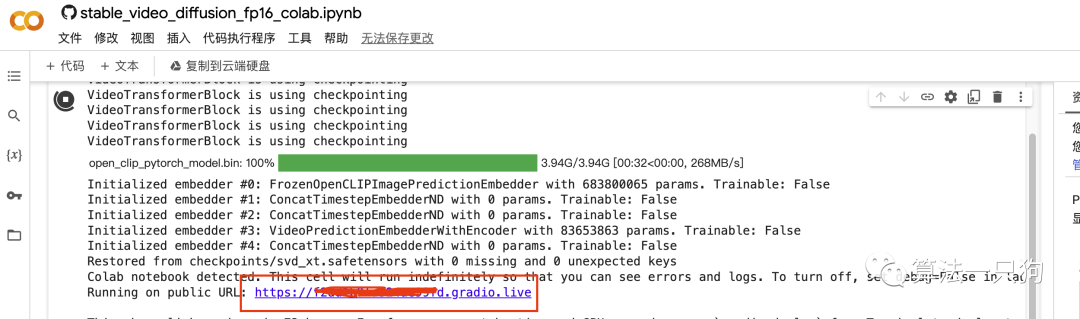
打开网页后,就可以上传自己的图片进行视频转换了
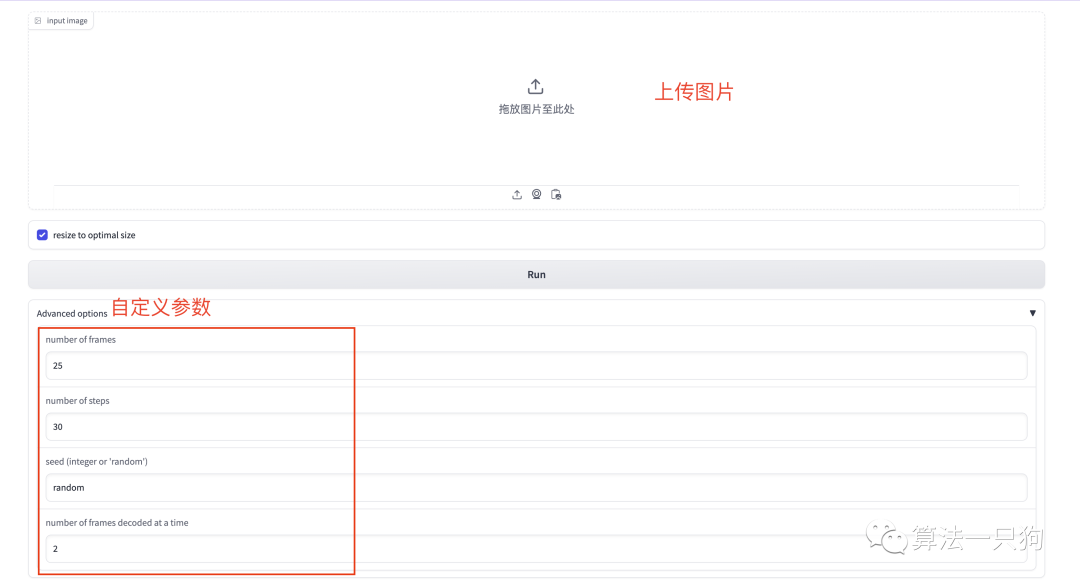
下面我们来看看不同的类型这个模型能够转换的效果。
1
人物图片转换
在人物图片转换成视频可以看到,其像是转移了拍摄角度,且很好的保留原始图片的信息并做了额外背景的补全。

而在控制人物的表情方面,这个模型也能够有效的在细节上做控制。比如下面的这个视频,可以看到人物的眼睛有一个明显的上移。

2
风景图片转换
这里上传了一张蓝色汽车的图片。
从视频效果中可以看到,生成的效果使得汽车在运动,且车速较快,因为它的运动模糊效果很强烈。

这是一张描绘夜晚城市街道的图片,一辆银色的汽车停在路边。背景补全了不同视角的高楼大厦和霓虹灯牌。

3
动画图片转换
在动画风格的转换上,它能够很好的模拟出烟花的效果。比如上传的是一张静态的烟花图:

它则能够模拟出烟花的动画效果:

未来计划
目前仅仅开源了图片生成视频模型,但是未来将会把文本生成视频模型也一并开源。
目前可以加入到它的waitlist中尝试一下。
https://stability.ai/contact
但由于AIGC刚刚爆火,网上相关内容的文章博客五花八门、良莠不齐。要么杂乱、零散、碎片化,看着看着就衔接不上了,要么内容质量太浅,学不到干货。
这里分享给大家一份Adobe大神整理的《AIGC全家桶学习笔记》,相信大家会对AIGC有着更深入、更系统的理解。
有需要的朋友,可以长按下方二维码,免费领取!

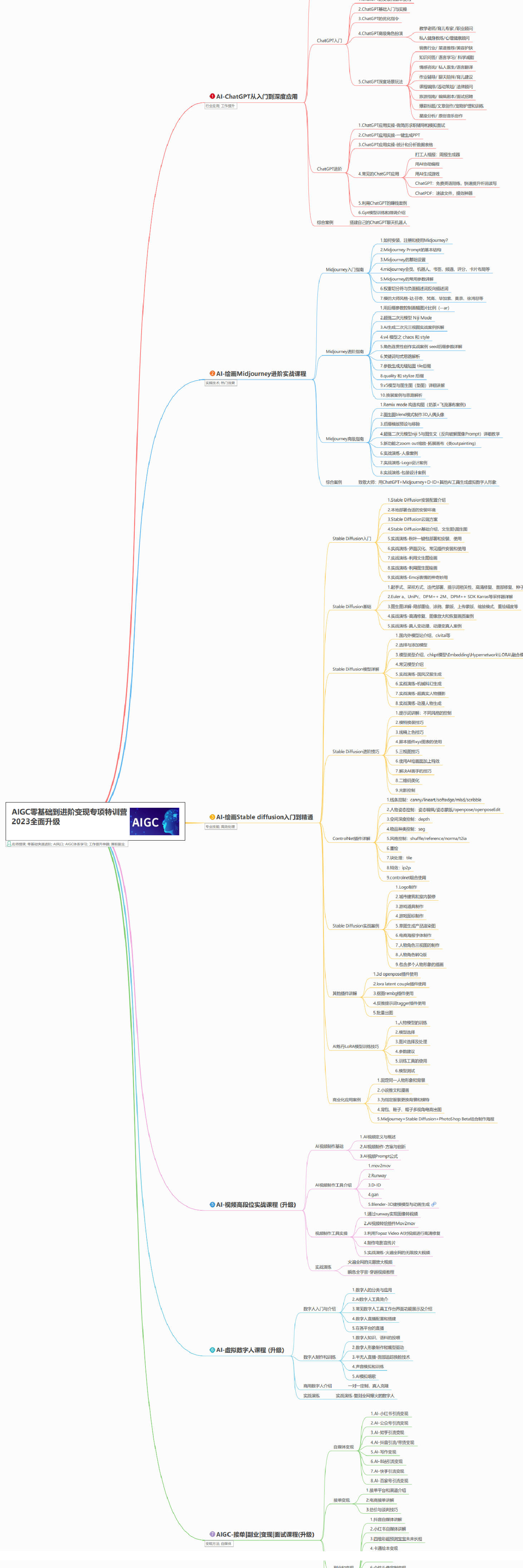
AIGC所有方向的学习路线思维导图
这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。如果下面这个学习路线能帮助大家将AI利用到自身工作上去,那么我的使命也就完成了:
AIGC工具库
AIGC工具库是一个利用人工智能技术来生成应用程序的代码和内容的工具集合,通过使用AIGC工具库,能更加快速,准确的辅助我们学习AIGC

有需要的朋友,可以点击下方卡片免费领取!
精品AIGC学习书籍手册
书籍阅读永不过时,阅读AIGC经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验,结合自身案例融会贯通。
AI绘画视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,科学有趣才能更方便的学习下去。

有需要的朋友,可以长按下方二维码,免费领取!

















 1582
1582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









