







 文章探讨了编译器优化如-O3、constexpr以及如何利用size_t提升效率。讲解了64位X86新增寄存器、浮点数运算的xmm寄存器和SIMD技术。还提到了指针别名问题及__restrict关键字的作用,以及volatile用于禁止优化的场景。同时,介绍了循环优化、循环展开、结构体对齐和面向数据编程的SOA模式。
文章探讨了编译器优化如-O3、constexpr以及如何利用size_t提升效率。讲解了64位X86新增寄存器、浮点数运算的xmm寄存器和SIMD技术。还提到了指针别名问题及__restrict关键字的作用,以及volatile用于禁止优化的场景。同时,介绍了循环优化、循环展开、结构体对齐和面向数据编程的SOA模式。
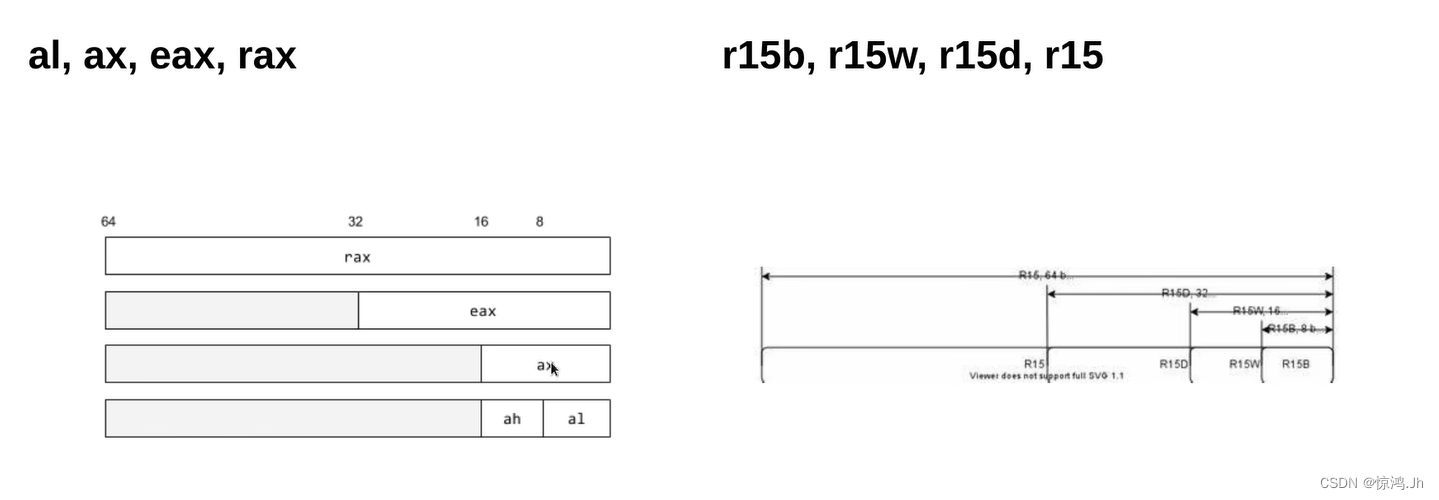
64位X86新增了r8-r15八个寄存器
AT&T(GCC)汇编语言与学过的Intel稍有区别
表达式往往是从左至右的
开启优化:-O3
![]()
一次函数都可以被优化成leal
1.指针的索引:尽量使用size_t
int func(int* a,std::size_t b){
return a[b];
}
for(std::size_t i=0; ;i++)
a[i]*=2;
因为size_t在64位系统上相当于uint64_t
生成汇编代码时,不需要将int(32bit)扩展到int*(64bit)做运算,更高效。此外
浮点数作为参数和返回:xmm系列寄存器128位(可以放两个double,四个float)
addss //汇编指令
add表加法
s表标量,只对xmm最低位进行计算;也可以是p表矢量,对xmm所有位进行运算。
s表单精度浮点数(float),也可以是d表示双精度浮点数(double)
SIDM(single-instruction multiple-data)
这种方式可以大大增加计算密集型程序的吞吐量。
编译器优化:不是万能的
尽量避免代码复杂化,避免使用会造成new\delete的容器。

constexpr关键词:强迫编译器在编译期间求值
也是不能有堆上的数据
分文件编写,调用外部函数编译器无法优化。
局部可见函数static,使用此关键词声明,就不会将该函数暴露给其他函数,此时编译器优化后,压根就不会定义该函数,直接内联。
因此在现代编译器中inline根本不会内联。
godbolt.org //可以做编译器实验
指针别名现象:
void func(int*a,int*b,int*c){
*c=*a; //就是怕出现指针别名现象,所以编译器不会优化掉该语句
*c=*b;
}
int main(){
int a,b;
func(&a,&b,&b);
}
//宁慢不错解决方式:__restrict关键字,也就是告诉编译器,指针间不会重叠,大胆优化!
void func(int*__restricet a,int*__restricet b,int*__restricet c){
*c=*a; //就是怕出现指针别名现象,所以编译器不会优化掉该语句
*c=*b;
}禁止优化:volatile关键词(保证内存可见性)
int func(int volatile *a){
*a=42;
return *a;//此时编译器会老实的去读该地址,而不是直接返回42
}
for(volatile int i=0;i<1000;i++)//嘿嘿,此时编译器不会将这个空循环优化掉,会老老实实执行,可以实现类似于计时器的效果。编译器优化:合并写入
void func(int *a){
a[0]=123;
a[1]=456;
}对于连续的地址,两个32位的写入,编译器可以直接优化为一个64位写入。
更宽的合并写入,128位(xmm),会使用矢量化指令。
SIMD加速4的倍数并行写入;对于非4的倍数,编译器也会自动进行边界特判。尽量使所有数组都是16的整数倍,避免编译器特判。
循环
void func(float* __restrict a,float* __restrict b){
for(int i=0;i<1024;i++){
a[i]=b[i]+1;
}
}
void func(float* a,float* b){
for(int i=0;i<1024;i++){
a[i]=b[i]+1;
}
}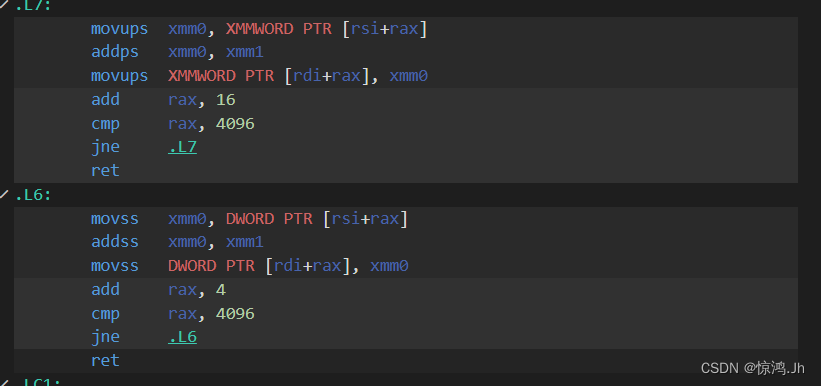
同理,编译器为了防止指针别名现象,会生成两份汇编代码(普通版和SIMD版本),然后进行指针做差运算判断有无指针别名现象,为了避免此操作造成的效率损失,也应加入__restrict关键字。
void func(float*a,float*b){
#pragma omp simd//还可以这么写,OpenMP指令强制生成SIMD版本
for(int i=0;i<1024;i++){
a[i]=b[i]+1;
}
}对于GCC编译器
#pragma GCC ivdep//针对GCC编译器(ignore vector dependency)也可以实现类似操作
对于循环之中的判断语句,编译器会挪到外面,前提是判断语句在循环当中不会改变。
对于常量表达式,编译器也会挪到循环外运算,减少运算次数。
void func(float*__restrict a,float*__restrict b,float dt){
for(int i=0;i<1024;i++){
a[i]=a[i]+b[i]*(dt*dt);//对于常量的乘法必须加括号,因为乘法是左结合,若不加()则无法优化
}
}注:调用外部文件函数也会导致优化失败。所以热循环尽量不使用外部函数。
循环展开:
void func(float*a){
#pragma GCC unroll 4//使用此指令,可以表示把循环体展开为4个
for(int i=0;i<1024;i++){
a[i]=1;
}
}
//相当于以下
void func(float* a){
for(int i=0;i<1024;i+=4){
a[i+0]=1;
a[i+1]=1;
a[i+2]=1;
a[i+3]=1;
}
}目的是在每次循环中增加实际计算的比重,提高效率
循环展开前

循环展开后
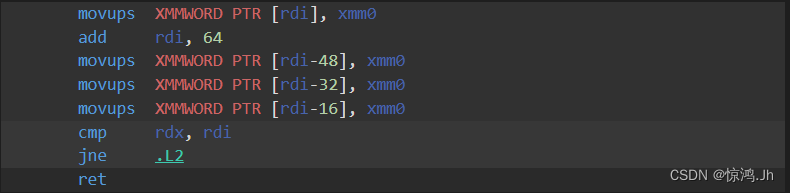
但是太大的循环体则不要unroll,会造成指令缓存的压力反而会变慢。
结构体:
使结构体变为2的整数幂大小有利于SIMD优化,可以加一些无用的四字节变量来保证。
或者使用alignas(需要对齐的字节数)
struct alignas(16) MyVec{//C++11新增的关键词
float x;
float y;
float z;
};但也可以会变慢,因为可能会导致内存带宽的占用,总之要结合实际综合考虑。

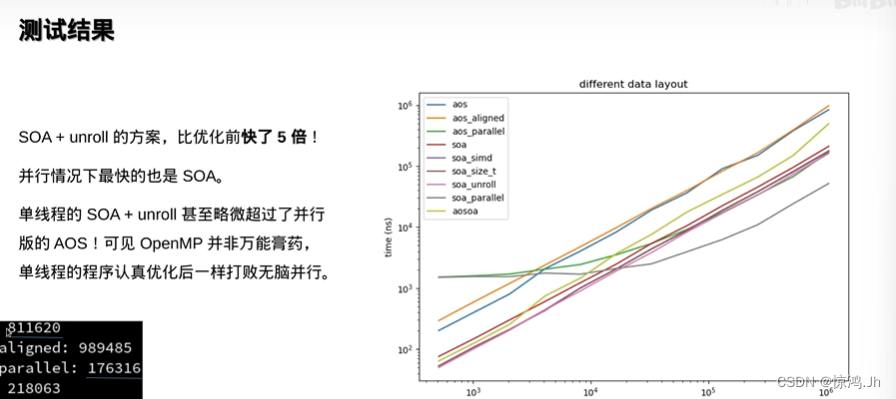
AOS符合面向对象的思想,但常常不利于性能。
//AOS形式:
struct MyVec{
float x;
float y;
float z;
};
Myvec a[1024];
//SOA形式,更高效,面向数据编程思想(DOP)
struct MyVec{
float x[1024];
float y[1024];
float z[1024];
};
MyVec a;
//AOSOA:中间方案,既有AOS的直观,又有SOA的高效
struct MyVec{
float x[4];
float y[4];
float z[4];
};
MyVec a[1024/4];
AOSOA的缺点:访问时需要双重循环,而且不利于随机访问。
STL
vector也有指针别名问题:
解决方法:#pragma omp simd 或#pragma GCC ivdep
数学优化:
编译器会将除法转换为乘法进行优化。
//但是这种情况下编译器会放弃优化,因为不知道b是否会为0;
void func(float *a,float b){
for(int i=0;i<1024;i++){
a[i]/=b;
}
}
解决方案1:手动优化
void func(float *a,float b){
float inv_b=1/b;
for(int i=0;i<1024;i++){
a[i]*=inv_b;
}
}解决方案2:gcc-ffast-math -O3
这条指令让GCC更大胆的尝试浮点运算的优化,但是得保证程序中不会出现NAN和无穷大
数学函数请假std::前缀!c版本的数学处理函数有些只接受返回double浪费性能。


















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









