







提升模型是提升树算法的前提。提升模型的基本思想就是多个简单的模型线性组合成一个最终的模型,提升树算法的实现当然也是这个思路。看过好多的介绍,基本上在提升树算法中,每个简单的模型都是一颗树高为1的二叉树模型,因为每次都是选择一个特征及特征值,然后将数据集分开为不同的集合,然后对其进行相应的线性组合。当然可以简单的这么理解,下面结合自己的理解介绍一下提升树算法。
当然理解提升树算法的前提是,需要了解CART树,如果不了解可以看我的其他文章(决策树:一二三系),或者自行了解,还有就是前向分步算法要了解,因为提升模型中很多就用到了这个算法,如果不了解提升树算法虽然能看懂,但是也会比较迷茫。这里我写的提升树模型基本上是按照李航《统计学习方法》一书中讲的,因为人家已经讲得很好了,我只加了一些自己的理解,使之更容易理解。后面的GBDT(梯度提升算法)会详细说下但也是自己的理解。
1.提升树模型以及算法
提升树模型是一种加法模型,基本表达式如下:
![]() (式1)
(式1)
其中的T(x;θm)表示决策树;θm表示决策树的参数;M为数的个数。通过这个模型表达式,我们可以看到提升树模型就是多个决策树的“和”形成的,m就是第m个决策树模型,其表达式如下:
![]() (式2)
(式2)
通过式2我们可以看出,每步的最终模型都是前一步得到的模型加上当前拟合的模型。到这里可能有人就会有比较疑惑,其实每一步的T(x;θm)并不是直接拟合结果的模型,通过后面的介绍就明白了,这个是对残差的拟合,而加上前一步得到的模型,才是每步最终的模型。式2中f1(x)= T(x;θ1)。
其实这里可能还有疑问,决策树怎么能表达成加法模型呢?其实我觉得这里的加法可以理解宽泛一些,只是概念上的叠加,多个决策树组合在一起形成最终的模型;我觉得可以这么理解,但是对于单单提升树而言,它确实是每次拟合残差(每步模型),然后通过前向分步算法用前一个最终模型fm-1(x)加上当前拟合模型的残差,得到当前的模型fm(x)的。这样通过多次迭代最终得到理想的模型。
在回归树模型中,我们对于每个根节点的做法是,通过启发式算法,用平方误差最小化,找出一个合适的特征值s,然后将根节点中的训练值分到不同的子节点;提升树的做法类似,也是通过启发式方法,每步找出一个合适的s值,将训练数据分成不同的小区间;每一步我们需要计算预测值和实际值之间的误差,那么预测值怎么算呢,我们取每个区间的均值作为该区间的预测值。
提升树中我们也用平方误差最小化的方式求每一步的最优参数s:
![]() (式3)
(式3)
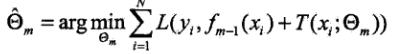 (式4)
(式4)
其中式3使我们每一步用到的损失函数,式4表示我们在每一步损失最小的情况下,求得的最佳参数s。结合式2,我们得到以下推理:
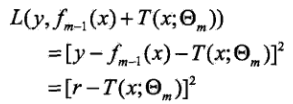
其中
![]()
r就是当前模型拟合数据的残差,y是实际值,fm-1(x)是前一步得到的最终模型的预测值。
下面我们结合一个具体的例子来看看这个模型的具体过程:
如表1所示的值,x的取值范围是[0.5,10.5],y的取值范围是[5.0,10.0]:

表1
我们先求f1(x)= T(x;θ1)。通过启发式方法求解。先给出一系列的切分点:1.5,2.5,3.5,4.5,5.5,6.5,7.5,8.5,9.5,分别取这些切分点,将训练数据分成两个不同的结合![]() ,然后分别取这两个集合中的均值,作为预测值,然后通过平方误差的方式,求出不同切分点的情况下,两个集合的误差:
,然后分别取这两个集合中的均值,作为预测值,然后通过平方误差的方式,求出不同切分点的情况下,两个集合的误差:
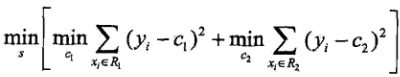 。
。
当s=1.5时R1={1},R2={2,3,4,5,6,7,8,9,10},c1=5.56,c2=7.50,然后我们求其平方误差如下: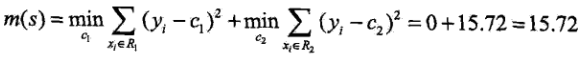 ,然如表二所示,我们求出所有的误差:
,然如表二所示,我们求出所有的误差:

表2
所以由表2可知,当s是6.5的时候,误差叨叨最小值,此时R1={1,2,3,4,5,6},R2={7,8,9,10},c1=6.24,c2=8.91,所以回归树为
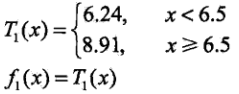
然后我们计算残差表:

然后我们第二步只拟合残差按照平方误差的方式求出误差表,x还取以上s取的不同值,不断划分区间,取均值求误差。
表2
| s | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 | 9.5 |
| m(s) | 1.43 | 1.02 | 0.80 | 1.15 | 1.69 | 1.95 | 1.95 | 1.91 | 1.92 |
所以由表2可得,当s是3.5的时候,误差最小,这时候我们给出残差表
| x | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| r3i | -0.16 | -0.02 | 0.18 | -0.01 | 0.37 | 0.63 | -0.18 | -0.38 | -0.08 | -0.03 |
然后我们可以得到残差表的划分区间:
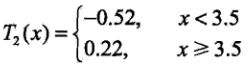
进而得到f2(x)
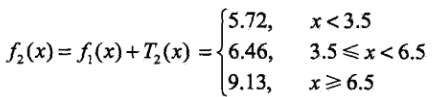
依次迭代上面的过程,然后最终得到:
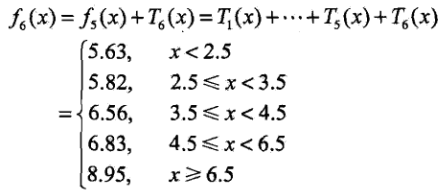
其平方损失如下:
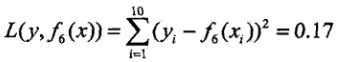
假设此时已满足要求,那么f(x)=f6(x)即为所求的提升树。
2.GBDT算法
提升树利用加法模型与前向分步算法实现学习的优化过程。当损失函数是平方损失和指数损失函数时,每一步的优化很简单的。但是每一步优化是很简单的。但是对一般损失函数而言,往往每一步的优化并不那么容易。针对这一问题,Freidman提出了梯度提升(gradient Boosting)算法,这个利用最速下降法的近似方法,关键是利用损失函数的负梯度在当前模型的值:
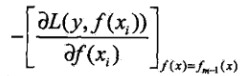
作为回归问题提升树算法中的残差的近似值,拟合一个回归树。
下面直接给出算法的步骤:

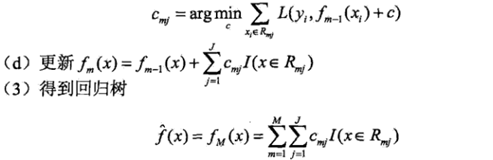
算法的第1步初始化,估计使用损失函数及消化的常数值,他是只有一个根节点的树,第2(a)步计算损失函数的负梯度在当前模型的值,将它作为残差的估计值。对于平方损失函数,它就是通常所说的残差(这个可以结合上面提升树的例子理解);对于一般的损失函数,他就是残差的近似值,第2(b)步估计回归树叶子结点区域,以拟合残差的近似值。第2(c)步利用线性搜索估计叶子结点区域的值,使损失函数最小化。第2(d)步更新回归树。第3步得到最终的输出模型。
其实总结一下,这个模型就是每次拟合一个负梯度的值,上面提升树的例子中,负梯度,我们用残差y1-f(x1),来表示负梯度。每次拟合梯度,每一次的模型都是在上一个模型加上当前拟合的残差模型。
3.GBDT算法用于分类
我们上面提到的GBDT算法,通过拟合迭代过程中的负梯度来生成算法,当其用于分类时就不能再用回归树中的残差来拟合结果了,因为分类过程中计算残差没有太大的意义。对于分类问题我们最终的结果就只能说是(+1,-1)的情况,表示是与不是的概念。
分类问题有二分类问题和多分类问题,我们首先讨论二分类问题。对于二分类问题可以直接将AdaBoost算法中的基本分类限制为二分类情况即可,可以参考Adaboost算法。
对于多分类问题,可以简化成二分类问题,假设有3个分类,每次迭代计算看成是三个二分类的问题:是否是1分类,是否是2分类,是否是3分类。然后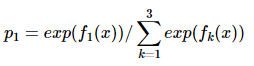 ,更新第一步的概率。等第一步计算完成后再进行第二步的迭代。这个是我根据网上的一些资料的自己的理解,不过也没有十分看明白,下面给出参考链接,希望看明白的能不吝赐教。
,更新第一步的概率。等第一步计算完成后再进行第二步的迭代。这个是我根据网上的一些资料的自己的理解,不过也没有十分看明白,下面给出参考链接,希望看明白的能不吝赐教。
https://blog.csdn.net/qq_22238533/article/details/79199605
https://blog.csdn.net/anshuai_aw1/article/details/82888222
https://www.cnblogs.com/ModifyRong/p/7744987.html















 2038
2038











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









