








Most importantly, MapReduce programs are inherently parallel, thus putting very large-scale data analysis into the hands of anyone with enough machines at their disposal.MapReduce comes into its own for large datasets, so let’s start by looking at one.
更重要的是,MapReduce程序天生就适合并发,因此任何人只要有足够的机器就可以进行大规模的数据分析。MapReduce因大数据而盛行起来,所以让我们先来看一个这样的大数据集。
1) Analyzing the Data with Unix Tools
a) It’s generally easier and more efficient to process a smaller number of relatively large files, so the data was preprocessed so that each year’s readings were concatenated into a single file.
处理较少数量的相关大文件通常会更加容易和高效,因此这些数据已经被预处理,以便可以把每一年的读取数据都拼接到一个单个文件中。
b) To speed up the processing, we need to run parts of the program in parallel. First, dividing the work into equal-size pieces isn’t always easy or obvious. Second, combining the results from independent processes may require further processing. Third, you are still limited by the processing capacity of a single machine. So, although it’s feasible to parallelize the processing, in practice it’s messy.
为了加快处理进程,我们需要并发的运行部分程序。首先,将工作任务划分成相等的大小的块并不总是那么容易或明显。其次,整合不同独立进程的结果可能需要更进一步的处理。最后,你将仍然受限于单个机器的处理能力。因此,尽管并发处理是可行的,但实际上有点麻烦。
2) Analyzing the Data with Hadoop
a) MapReduce works by breaking the processing into two phases: the map phase and the reduce phase. Each phase has key-value pairs as input and output, the types of which may be chosen by the programmer. The programmer also specifies two functions: the map function and the reduce function.
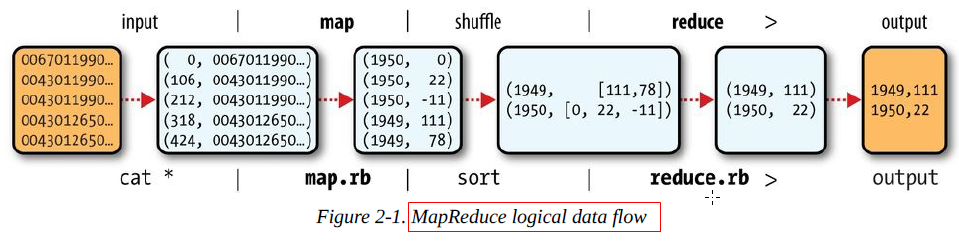
MapReduce处理任务主要有两个阶段:map阶段和reduce阶段,每一个阶段都有相应的键值对(key-value)作为输入和输出,它们的类型对于程序员来说是可选的。程序员也可以指定两个函数:map函数和reduce函数。
b) Having run through how the MapReduce program works, the next step is to express it in code. We need three things: a map function, a reduce function, and some code to run the job.
知道了MapReduce程序的工作原理之后,下一步就是用代码实现它,为此,我们需要三样东西:一个map函数,一个reduce函数,以及一些代码用来执行这个任务。
c) Here we use LongWritable, which corresponds to a Java Long, Text (like Java String), and IntWritable (like Java Integer).
在这里,我们使用LongWritable,Text,IntWritable,对应于Java中的Long类型,String以及Integer类型。
d) Rather than explicitly specifying the name of the JAR file, we can pass a class in the Job’s setJarByClass() method, which Hadoop will use to locate the relevant JAR file by looking for the JAR file containing this class.
我们可以使用setJarByClass()方法在任务作业中传递一个类名,这样hadoop通过查找包含此类名的JAR文件来定位相关的JAR文件,而不需要直接明确的指定jar文件名。
e) Having constructed a Job object, we specify the input and output paths.
在创建了一个job对象之后,我们需要指定输入和输出路径。
f) Next, we specify the map and reduce types to use via the setMapperClass() and setReducerClass() methods.
接下来,我们通过setMapperClass()和setReducerClass()方法来指定map和reduce的类别。
g) Knowing the job and task IDs can be very useful when debugging MapReduce jobs.
当需要调试MapReduce作业时,知道作业和任务的ID编号是非常有用的。
h) The last section of the output, titled “Counters,” shows the statistics that Hadoop generates for each job it runs. These are very useful for checking whether the amount of data processed is what you expected.
输出的最后一部分,以“计数器”为标题,显示了在hadoop上面运行的每个作业的一些统计信息。
3) Scaling Out
a) A MapReduce job is a unit of work that the client wants to be performed: it consists of the input data, the MapReduce program, and configuration information. Hadoop runs the job by dividing it into tasks, of which there are two types: map tasks and reduce tasks. The tasks are scheduled using YARN and run on nodes in the cluster. If a task fails, it will be automatically rescheduled to run on a different node.
一个MapReduce作业就是客户端想要执行的一个工作单元:它包含了输入数据,MapReduce程序,以及配置信息。hadoop把这个工作单元切分成多个任务块来运行,这些任务块有两种类型:map任务和reduce任务。这些任务被安排使用YARN框架来运行在集群中的节点上。如果某个任务失败,它将会被自动重新安排到一个不同的节点上运行。
b) Hadoop divides the input to a MapReduce job into fixed-size pieces called input splits, or just splits. Hadoop creates one map task for each split, which runs the user-defined map function for each record in the split.
hadoop把一个MapReduce作业的输入数据切分成固定大小的片,称之为输入分片或简称分片。
hadoop为每一个输入分片创建一个map任务,这个map任务将会为本分片中的每一条数据运行自定义的map函数。
c) On the other hand, if splits are too small, the overhead of managing the splits and map task creation begins to dominate the total job execution time. For most jobs, a good split size tends to be the size of an HDFS block, which is 128 MB by default, although this can be changed for the cluster (for all newly created files) or specified when each file is created.
在另一方面,如果分片太小的话,管理这些分片 的开销以及为此创建map任务将会占据整个作业执行的大部分时间。对于大部分作业来说,一个良好的分片大小应该是一个HDFS块的大小,在默认情况下是128M,当然,大小也可以改变(对于所有新创建的文件)或者当创建文件时就指定大小。
d) Hadoop does its best to run the map task on a node where the input data resides in HDFS,because it doesn’t use valuable cluster bandwidth. This is called the data locality optimization.
hadoop会在那些在HDFS中存在输入数据的节点上竭力的运行map任务,因为这样可以不必使用珍贵的集群带宽。这就是所谓的数据本地化优化。
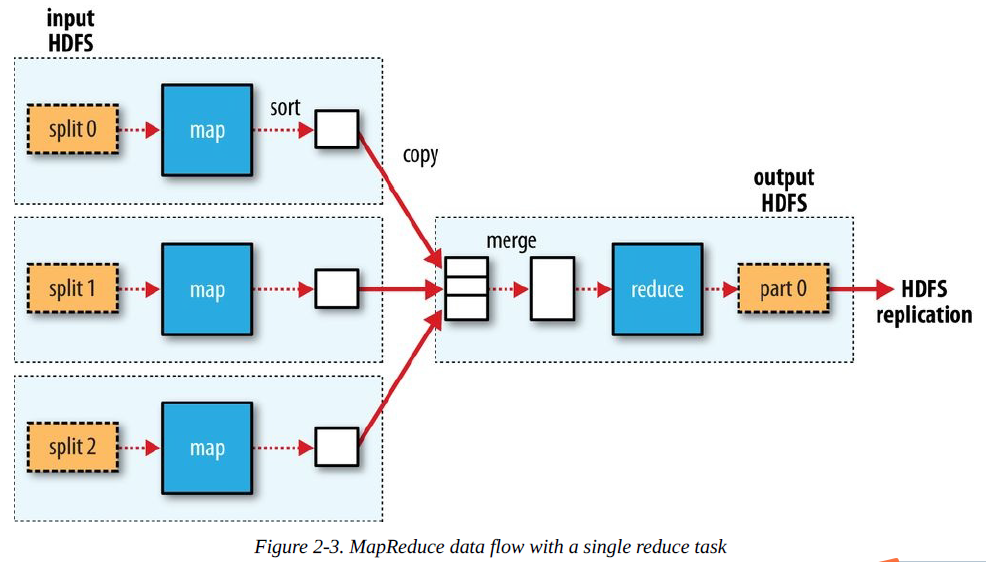
e) Map tasks write their output to the local disk, not to HDFS. Why is this? Map output is intermediate output: it’s processed by reduce tasks to produce the final output, and once the job is complete, the map output can be thrown away. So, storing it in HDFS with replication would be overkill. If the node running the map task fails before the map output has been consumed by the reduce task, then Hadoop will automatically rerun the map task on another node to re-create the map output.
map任务会将输出数据写入本地磁盘,而不是HDFS,为什么会这样呢?map任务的输出数据是中间输出物:它会被reduce任务进一步处理来产生最终的输出数据,而且,一旦作业完成,map 的输出数据就会被丢弃。因此,在HDFS中存储它并实现备份,就有些过度滥用了。如果某个节点在reduce任务解析map任务的输出数据之前运行map任务失败,hadoop将会自动在另一个节点上再次运行map任务以便再次生成map输出数据。
f) Therefore, the sorted map outputs have to be transferred across the network to the node where the reduce task is running, where they are merged and then passed to the user-defined reduce function. The output of the reduce is normally stored in HDFS for reliability.
因此,经过排序的map输出数据将会通过网络传送到正在运行reduce任务的节点上,在那里,这些数据将会被融合,紧接着会被传送到自定义的reduce函数中。为了可靠性,reduce任务的数据数据通常会被存储在HDFS中。
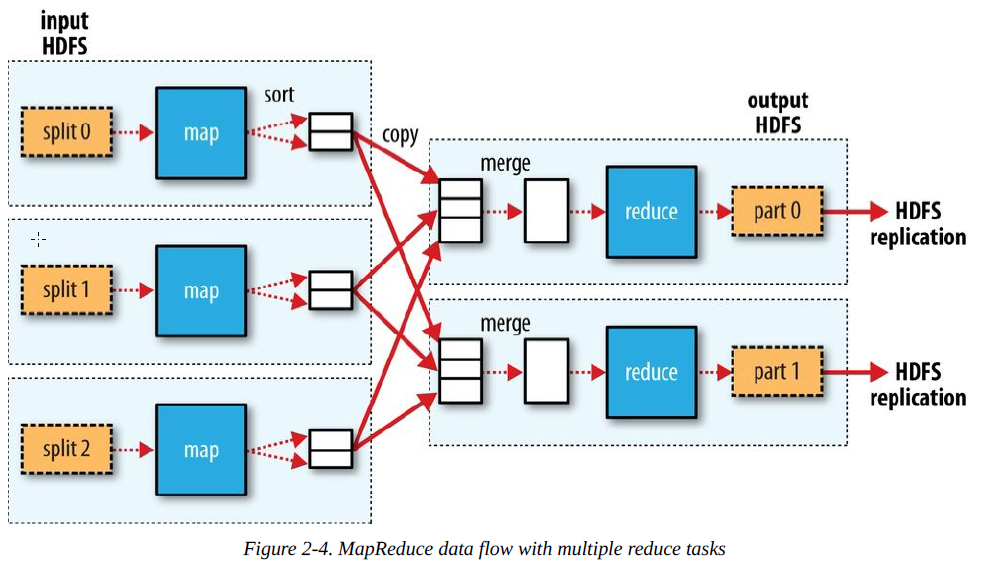
g) When there are multiple reducers, the map tasks partition their output, each creating one partition for each reduce task.
当存在多个reduce任务时,map任务就会分割他们的输出数据,使得每一个reduce任务都有一个分割数据可处理。
h) Hadoop allows the user to specify a combiner function to be run on the map output, and the combiner function’s output forms the input to the reduce function.
hadoop允许用户指定一个组合函数来运行map任务的输出数据,并且这个组合函数的输出可以作为reduce函数的输入。
i) The combiner function doesn’t replace the reduce function. (How could it? The reduce function is still needed to process records with the same key from different maps.) But it can help cut down the amount of data shuffled between the mappers and the reducers, and for this reason alone it is always worth considering whether you can use a combiner function in your MapReduce job.
组合函数不能替代reduce函数。(怎么会?reduce函数仍然需要处理不同map输出中相同key的记录。)但是它可以帮助我们减少mapper和reducer之间的需要整理的数据量,如果只从这个原因考虑的话,你是否在MapReduce作业中使用组合函数应该总是需要慎重考虑的。
j) The same program will run, without alteration, on a full dataset. This is the point of MapReduce: it scales to the size of your data and the size of your hardware.
无需修改,就可以在一个完整的数据集上运行同样的程序,这就是MapReduce的优势之一:它可以根据你的数据量大小以及硬件规模来扩展。
4) Hadoop Streaming
a) Hadoop Streaming uses Unix standard streams as the interface between Hadoop and your program, so you can use any language that can read standard input and write to standard output to write your MapReduce program.
hadoop的Streaming使用Unix的标准流作为hadoop和应用程序之间的接口,因此你可以使用任何可以读取标准输入/写入标准输出的语言去编写MapReduce程序。
b) Streaming is naturally suited for text processing. Map input data is passed over standard input to your map function, which processes it line by line and writes lines to standard output.
Streaming天生就适合于文本处理。map的输出数据通过标准输入流传送到map函数,经过逐行的处理之后写入到标准输出流。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









