








m) In normal operation, the Capacity Scheduler does not preempt containers by forcibly killing them,so if a queue is under capacity due to lack of demand, and then demand increases, the queue will only return to capacity as resources are released from other queues as containers complete. It is possible to mitigate this by configuring queues with a maximum capacity so that they don’t eat into other queues’ capacities too much. This is at the cost of queue elasticity, of course, so a reasonable trade-off should be found by trial and error.
在正常的操作中,Capacity调度器不会通过强制杀死它们来优先获取container,因此,如果一个队列由于缺乏需求而容量过低,那么随着需求的增加,当container完成时随着其他队列容量的释放,队列将会恢复容量。通过配置队列的容量到最大值这种方式,是可以缓解侵占其他队列太多容量这种情况的。这是以队列的弹性为代价的,当然,如此一个合理的权衡应该同步不断的实验摸索来实现。
n) Imagine a queue hierarchy that looks like this:
root
├── prod
└── dev
├── eng
└── science
想象一下一个队列的层级结构像这样:
o) The listing in Example 4-1 shows a sample Capacity Scheduler configuration file, called capacity-scheduler.xml, for this hierarchy. It defines two queues under the root queue, prod and dev, which have 40% and 60% of the capacity, respectively. Notice that a particular queue is configured by setting configuration properties of the form yarn.scheduler.capacity.., where is the hierarchical (dotted) path of the queue, such as root.prod.
在例子4-1中的罗列展示了一个简单的Capacity调度器配置文件,被称作capacity-scheduler.xml,其针对上述这种层级结构的。其在root队列下定义了两个队列,分别是prod和dev,且各自占有40%和60%的容量。需要注意的是一个特定的队列需要通过设置yarn.scheduler.capacity..的格式属性,其中是其队列的层级路径,比如root.prod
p) Example 4-1. A basic configuration file for the Capacity Scheduler
一个基本的Capacity调度器的配置文件
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>prod,dev</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.queues</name>
<value>eng,science</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.prod.capacity</name>
<value>40</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.capacity</name>
<value>60</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.maximum-capacity</name>
<value>75</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.eng.capacity</name>
<value>50</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.science.capacity</name>
<value>50</value>
</property>
</configuration>q) As you can see, the dev queue is further divided into eng and science queues of equal capacity. So that the dev queue does not use up all the cluster resources when the prod queue is idle, it has its maximum capacity set to 75%. In other words, the prod queue always has 25% of the cluster available for immediate use. Since no maximum capacities have been set for other queues, it’s possible for jobs in the eng or science queues to use all of the dev queue’s capacity (up to 75% of the cluster), or indeed for the prod queue to use the entire cluster.
正如你说看到的,dev队列还可以进一步被分割为相等容量的eng和science队列,且dev队列的最大容量设置为集群的75%,因此当prod队列空闲的时候,dev队列不会耗尽集群资源。换句话说,prod队列始终有25%的集群资源可以立刻使用。由于其他队列没有设置最大的容量,因此对于eng或science队列中的作业来说使用dev队列的所有容量(不高于集群资源的75%)是可能的,亦或者对于prod队列来说可以使用整个集群资源。
r) The way that you specify which queue an application is placed in is specific to the application. For example, in MapReduce, you set the property mapreduce.job.queuename to the name of the queue you want to use. If the queue does not exist, then you’ll get an error at submission time. If no queue is specified, applications will be placed in a queue called default.
指定应用程序在哪个队列的方式对于应用程序来说是特定的,举个例子,在MapReduce中,你设置mapreduce.job.queuename属性为你想使用的队列的名称。如果这个队列不存在,将在提交的时候发生异常错误。如果没指定队列的话,应用程序将会被置于默认队列之中。
s) Fair Scheduler Configuration
t) The Fair Scheduler attempts to allocate resources so that all running applications get the same share of resources. Figure 4-3 showed how fair sharing works for applications in the same queue; however, fair sharing actually works between queues, too, as we’ll see next.
公平调度器试图去分配资源以便于所有在运行的程序都可以得到一样份额的资源。图表4-3展示了公平分配规则对同一队列中的应用程序如何工作。然而,正如我们接下来将要看到的一样,公平分配实际上是在队列之间进行的。
u) 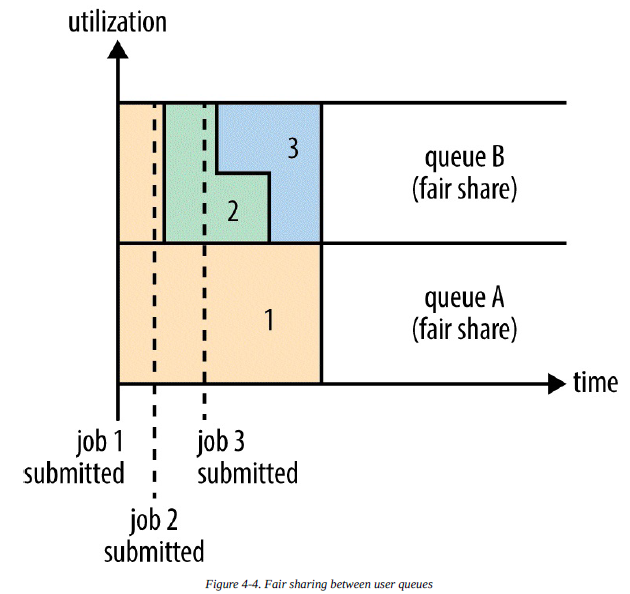
v) To understand how resources are shared between queues, imagine two users A and B, each with their own queue (Figure 4-4). A starts a job, and it is allocated all the resources available since there is no demand from B. Then B starts a job while A’s job is still running, and after a while each job is using half of the resources, in the way we saw earlier. Now if B starts a second job while the other jobs are still running, it will share its resources with B’s other job, so each of B’s jobs will have one-fourth of the resources, while A’s will continue to have half. The result is that resources are shared fairly between users.
为了理解资源在队列之间是如何分配的,可以假定有两个用户A和B,每一个都有他们自己的队列(图表4-4),用户A启动了一个作业,由于没有来自用户B的需求,故用户A的作业获得了所有可用的资源,接着当A的作业仍然在运行的时候,B启动了一个作业,一段时间之后,每一个作业都使用了一半的资源,这个在我们之前看到的方式中有所体现。现在当其他作业仍然在运行的时候,如果用户B启动了第二个作业,其将会与B的其他作业一起分享B的资源,因此,B的每一个作业将会获得四分之一的资源,而A则继续保持一半的资源。结果就是资源在用户之间公平的分配。
w) The scheduler in use is determined by the setting of yarn.resourcemanager.scheduler.class. The Capacity Scheduler is used by default (although the Fair Scheduler is the default in some Hadoop distributions, such as CDH), but this can be changed by setting yarn.resourcemanager.scheduler.class in yarnsite. xml to the fully qualified classname of the scheduler, org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler.
使用何种调度器是由设置yarn.resourcemanager.scheduler.class来实现的。默认的情况下使用Capacity调度器(尽管Fair调度器在某些Hadoop版本中是默认的,比如CDH中),但是这是可以改变的,通过设置yarnsite.xml中的yarn.resourcemanager.scheduler.class为调度器的全称即可,比如:org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler.
x) The Fair Scheduler is configured using an allocation file named fair-scheduler.xml that is loaded from the classpath. (The name can be changed by setting the property yarn.scheduler.fair.allocation.file.) In the absence of an allocation file, the Fair Scheduler operates as described earlier: each application is placed in a queue named after the user and queues are created dynamically when users submit their first applications.
Fair调度器通过fair-scheduler.xml分配文件来配置,这个文件可以从classpath类路径来装载。(这个名称可以通过设置属性yarn.scheduler.fair.allocation.file.来更改。)在缺少分配文件的情况下,Fair调度器按照之前描述的那样进行操作:每一个应用程序被置于一个由用户名称命名的队列中,当用户提交第一个应用程序时队列将会被动态创建。
y) Per-queue configuration is specified in the allocation file. This allows configuration of hierarchical queues like those supported by the Capacity Scheduler. For example, we can define prod and dev queues like we did for the Capacity Scheduler using the allocation file in Example 4-2.
每一个队列的配置都是在分配文件中指定的。这将允许像Capacity调度器支持的那样进行层级队列的配置。举个例子,在例4-2中使用分配文件后,我们可以像在Capacity调度器中做的那样来定义prod和dev。
z) Example 4-2. An allocation file for the Fair Scheduler
Fair调度器的分配文件
<?xml version="1.0"?>
<allocations>
<defaultQueueSchedulingPolicy>fair</defaultQueueSchedulingPolicy>
<queue name="prod">
<weight>40</weight>
<schedulingPolicy>fifo</schedulingPolicy>
</queue>
<queue name="dev">
<weight>60</weight>
<queue name="eng" />
<queue name="science" />
</queue>
<queuePlacementPolicy>
<rule name="specified" create="false" />
<rule name="primaryGroup" create="false" />
<rule name="default" queue="dev.eng" />
</queuePlacementPolicy>
</allocations>aa) Queues can have different scheduling policies. The default policy for queues can be set in the top-level defaultQueueSchedulingPolicy element; if it is omitted, fair scheduling is used. Despite its name, the Fair Scheduler also supports a FIFO (fifo) policy on queues, as well as Dominant Resource Fairness (drf), described later in the chapter.
队列可以有不同的调度政策,默认的队列政策可以在顶级元素defaultQueueSchedulingPolicy中设置,如果这一项设置遗漏了,将会使用Fair调度器。尽管它的名字是Fair调度器,但是在队列上它也支持FIFO规则以及将会在后面的章节中描述到的drf。
bb) The policy for a particular queue can be overridden using the schedulingPolicy element for that queue. In this case, the prod queue uses FIFO scheduling since we want each production job to run serially and complete in the shortest possible amount of time. Note that fair sharing is still used to divide resources between the prod and dev queues, as well as between (and within) the eng and science queues.
一个特定队列的政策可以使用其schedulingPolicy元素来进行重载。在这种情况下,由于我们想让每一个产品作业连续性运行,且在尽可能最短的时间内完成,故prod队列可以使用FIFO调度器。注意,公平分配仍然在prod和dev以及eng和science队列之间进行资源分割。
cc) The Fair Scheduler uses a rules-based system to determine which queue an application is placed in.
Fair调度器使用基于规则的系统来决定一个应用程序放置于哪一个队里中。
dd) The queuePlacementPolicy can be omitted entirely, in which case the default behavior is as if it had been specified with the following:
queuePlacementPolicy可以彻底的忽略,在这种情况下,默认的动作就犹如在以下代码中已经指定的一样:
<queuePlacementPolicy>
<rule name="specified" />
<rule name="user" />
</queuePlacementPolicy>In other words, unless the queue is explicitly specified, the user’s name is used for the queue, creating it if necessary.
换句话说,除非队列已经明确指定了,否则队列将会用户的名称命名,如果需要的,将会被创建。
ee) Another simple queue placement policy is one where all applications are placed in the same (default) queue. This allows resources to be shared fairly between applications, rather than users. The definition is equivalent to this:
<queuePlacementPolicy>
<rule name="default" />
</queuePlacementPolicy>另一个简单的队列布置政策是所有的应用程序都将被置于同一个(默认)队列中,这将允许资源在应用程序而不是用户之间进行公平分配。这个定义等同于如下这样:
ff) It’s also possible to set this policy without using an allocation file, by setting yarn.scheduler.fair.user-as-default-queue to false so that applications will be placed in the default queue rather than a per-user queue. In addition, yarn.scheduler.fair.allow-undeclared-pools should be set to false so that users can’t create queues on the fly.
不使用分配文件来进行设置队列政策也是有可能的,通过设置yarn.scheduler.fair.user-as-default-queue为false来使得应用程序放置于默认的队列中,而不是每一个用户对用的队列中。另外,yarn.scheduler.fair.allow-undeclared-pools应该设置为false,来使得用户不会即时产生队列。
gg) When a job is submitted to an empty queue on a busy cluster, the job cannot start until resources free up from jobs that are already running on the cluster. To make the time taken for a job to start more predictable, the Fair Scheduler supports preemption.
当一个作业提交到一个繁忙的集群中的空队列的使用,此作业将不会启动直到已经运行在集群上的作业释放资源。为了使得一个作业的启动时间更有预见性,Fair调度器支持优先占有。
hh) Preemption allows the scheduler to kill containers for queues that are running with more than their fair share of resources so that the resources can be allocated to a queue that is under its fair share. Note that preemption reduces overall cluster efficiency, since the terminated containers need to be reexecuted.
优先占有权允许调度器杀死正在运行且拥有超过了其公平份额的资源的队列对应的container,以便于资源可以分配给那些低于其公平份额的队列。注意,由于终结的container需要重新执行,因此优先占有降低了整个集群的效率。
ii) Preemption is enabled globally by setting yarn.scheduler.fair.preemption to true. There are two relevant preemption timeout settings: one for minimum share and one for fair share, both specified in seconds. By default, the timeouts are not set, so you need to set at least one to allow containers to be preempted.
通过设置yarn.scheduler.fair.preemption为true,可以使得优先占有对全局有效,有两个相关的优先占有超时设置:一个是最小份额,一个是公平份额,二者都被指定为秒级别。默认情况下,超时是不会设置的,因此你需要设置至少一个来进行container的优先占有。
jj) All the YARN schedulers try to honor locality requests. On a busy cluster, if an application requests a particular node, there is a good chance that other containers are running on it at the time of the request. The obvious course of action is to immediately loosen the locality requirement and allocate a container on the same rack. However, it has been observed in practice that waiting a short time (no more than a few seconds) can dramatically increase the chances of being allocated a container on the requested node, and therefore increase the efficiency of the cluster. This feature is called delay scheduling, and it is supported by both the Capacity Scheduler and the Fair Scheduler.
所有的YARN调度器都试图满足位置请求,在一个忙碌的集群中,如果一个应用请求一个特定的节点,那么对于此时运行在此节点上的container来说是一个好机会。显而易见的做法就是立刻放开这个位置需求,并且在同一个机架上分配一个container。然而,在实际当中已经注意到了一个问题,那就是等待一个很短的时间(不超过几秒钟)就可以显著的增加在请求的节点上分配一个container的机会,也因此而增加了集群效率。这个特征就是所谓的延迟调度,Capacity和Fair调度器都支持。
kk) Every node manager in a YARN cluster periodically sends a heartbeat request to the resource manager — by default, one per second. Heartbeats carry information about the node manager’s running containers and the resources available for new containers, so each heartbeat is a potential scheduling opportunity for an application to run a container.
在YARN集群中的每一个节点管理者周期性的发送脉冲请求给资源管理器,默认情况下是每一秒发送一次。脉冲信息携带者关于节点管理者的正在运行的container,以及到达新container的资源信息,因此,对于一个应用程序运行一个container来说,每一次脉冲就是一次潜在的调度机会。
ll) When using delay scheduling, the scheduler doesn’t simply use the first scheduling opportunity it receives, but waits for up to a given maximum number of scheduling opportunities to occur before loosening the locality constraint and taking the next scheduling opportunity.
当使用延迟调度时,调度器不会简单的使用它所接收到的第一个调度机会,但是它会在放开位置限制以及采用下一个调度机会之前等待,直到所给定的最大调度机会次数发生之前。
mm) When there is only a single resource type being scheduled, such as memory, then the concept of capacity or fairness is easy to determine. If two users are running applications, you can measure the amount of memory that each is using to compare the two applications. However, when there are multiple resource types in play, things get more complicated. If one user’s application requires lots of CPU but little memory and the other’s requires little CPU and lots of memory, how are these two applications compared?
当仅有一个单资源类型被调度时,比如内存,这时容量或者公平的概念是很容易定义的。如果两个用户正在运行应用,你可以通过比较两个应用来测量每个应用程序使用的内容容量。然而,当有多种类型的资源工作时,事情会变得更加复杂。如果一个用户的应用程序需要占用大量的CPU,但是需要少量的内存,另一个用户则相反,这个时候这两个应用程序该怎么比较?
nn) The way that the schedulers in YARN address this problem is to look at each user’s dominant resource and use it as a measure of the cluster usage. This approach is called Dominant Resource Fairness, or DRF for short. The idea is best illustrated with a simple example.
YAARN中调度器处理这个问题的方式就是去看每个用户占绝对优势的资源,并且使用它作为集群使用的程度。这种方式叫做优势资源公平,或者简称DRF。这个思想用一个简单的例子就可以很好的说明。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









