






说是CPU篇,其实还是跟GPU扯上关系,Larrabee是比较新颖的Fusion实现,而这一篇则是介绍比较传统的一种Fusion解决方案,一种异构多核的实现。
主要参考文献有:
ISCA 06的 Multiple Instruction Stream Processor
PLDI 07的 EXOCHI: Architecture and Programming Environment for A Heterogeneous Multi-core Multithreaded System
PACT 08的 Pangaea: A Tightly-Coupled IA32 Heterogeneous Chip MultiProcessor
这三篇均出自Intel实验室之手,Pangaea就是 IA32的CPU加Intel GMA X4500的异构片上多处理器。
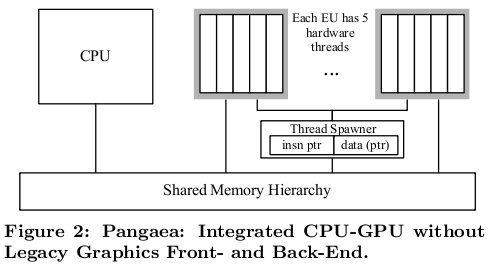
上图即为Pangaea的结构图,EU是GMA X4500的计算单元,每个EU有5个硬线程,每个线程支持8-wide SIMD操作。Pangaea把与图形相关的GPU的前端和后端都阉割了,留下了EU充当CPU协处理器的角色。从上图可见,Pangaea最大的特点就是共享内存,GPU分离的内存空间给GPGPU带来了很大的数据传输开销,Pangaea的共享内存的实现是借助于参考文献2 PLDI 07的文章提出的EXO的执行模式,以及CHI的编程环境,具体细节下面会介绍。Pangaea的另一贡献就是增加了3条扩展指令,用于CPU对EU的管理监控。用了用户级的中断(ULI)来作为CPU跟EU的通信机制。
EXO is an architecture to represent heterogeneous accelerators as ISA-based MIMD architecture resources, and a shared virtual memory heterogeneous multithreaded program execution model that tightly couples specialized accelerator cores with general purpose CPU cores。Intel实现了Core2加GMA X3000的异构平台原型。CHI是EXO的平台编程环境,通过内嵌汇编以及类似OpenMP的编译器指导两种方法来实现异构平台的多线程编程。
EXO是ISCA 06的 Multiple Instruction Stream Processor(MISP)的扩展。MISP的目的是来解决异构多核的并行性问题,用一个sequencer的资源来抽象处理器核,每个core是由2个或者多个sequencer组成,其中一个是OS管理,其他的是应用程序管理,也就是说,在OS层面,只有一个sequencer可调度,其他的sequencer并行的执行用户级线程。这样的设计,使得对于异构多处理器,OS可以只关注其中的一种,通过一条扩展指令signal来调度另外异构的核。
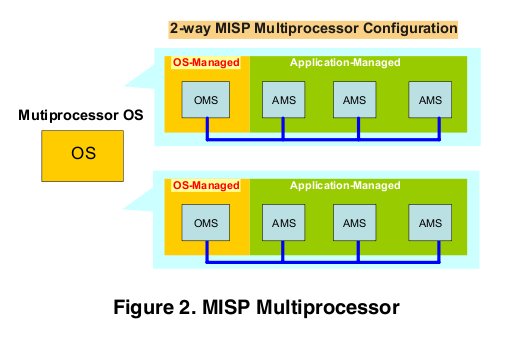
每个OS-Managed Sequencer和由他调度的Application-Managed Sequencer是共享虚地址空间的,OMS被调度的时候,他对应的AMS也得做调度,MISP可以用扩增的指令实现Pthread等多线程API,能 够由软件调度这些用户级线程AMS,以及相应的上下文切换,这样大大的解放了OS,可以不需要作什么修改就能够支持异构的多核。OMS跟AMS之间的通信 是靠MISP的一条扩展指令SIGNAL,SIGNAL(sid, eip, esp)发送信号给ID为sid的sequncer,AMS一旦接受到信号,就创建一个用户级线程。MISP还有一个比较新颖的设计叫proxy execution,对于那些会触发用户级异常的条件,可以通知OMS来处理,例如,Pangaea采用的是共享的虚地址空间,但EU跟CPU的页表都不 一样,一旦出现page fault,就会由proxy execution机制通知CPU代理处理这个page fault。Proxy execution机制使得AMS在功能上等价于一个OMS,既可以作page fault这样的异常处理,也可以实现OS的系统调用。MISP的其他细节,可以去读Multiple Instruction Stream Processor这篇文章。
EXO在MISP的基础上的扩展有三方面,一,增加了非IA32指令集的异构多核支持,EU上的sequencer称为exo-sequencer。二,Address Translation Remapping(ATR),这个就是上面介绍的,CPU在代理EU做page fault处理的时候,由于两者页表的结构的差异所作的地址转换。三,Collaborative Exception Handling,为exo-sequencer提供了异常机制,这个就是用proxy exectution来实现,主要加入一些硬件机制来解决异构多核的情况下的一些faulting数据类型不一致的情况。
CHI是EXO上的一套编程模型,C for Heterogeneous Integration,它是在ICC基础上作了些提高,支持内嵌exo-sequencer相关的汇编,通过EU加速器特定的汇编器以及CHI的运行时 库,生成一个特定的section来作为exo-sequencer执行的代码段,这最终的包含多种ISA的可执行代码被称为fat binary。除此之外,还提供了OpenMP的扩展,利用parallel pragma来自动生成并行的异构多线程。
Pangaea 就是在MISP和EXO/CHI的基础上设计的一种GPU跟CPU融合的异构片上多处理器。他扩展了三条指令来帮助CPU对EU进行控制监督,提供用户级的中断。SIGNAL之前已经介绍过,EMONITOR能够注册事件(如果异常、EU线程结束等)的处理函数,一旦事件发生,EU就挂起,CPU作为代理执行进入硬件内置的microcode handler,关掉ULI,清空流水线,保存当前指令,进入用户自定义的处理函数。中断处理函数是发生在用户级的,被称为User-Level Interrupts。ERETURN是ULI handler的返回指令。为了支持ULI,硬件上需要,一,新的寄存器来存放event同handler之间的映射。二,修改中断执行单元,能够识别ULI的触发,以及指令是从指令译码器还是从microcode来,三,指令译码部件,增加对上面三条指令的译码。四,增加microcode handler。
Pangaea的具体其他细节可以参考论文,从设计上来讲它解决了GPGPU的两个大难题,一是分离的虚地址空间导致过多的数据传输开销,二是没有中断支持,CPU与GPU之间的通信不方便。















 508
508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









