







neuron_layers.hpp:
NeuronLayer类
AbsValLayer类
BNLLLayer类
DropoutLayer类
PowerLayer类
ReLULayer类,CuDNNReLULayer类
SigmoidLayer类,CuDNNSigmoidLayer类
TanHLayer类,CuDNNTanHLayer类
ThresholdLayer类
这里面的所有类好像都是没有属性变量的,那么这些层的作用是什么呢?由于这里面至少有两个比较熟悉的层(对于初步使用过caffe的人来说),一个DropoutLayer,一个ReLULayer。以caffeNet为例的部分网络模型截图如下:
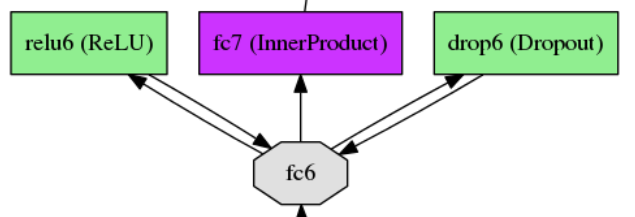
也就是说,这些类的操作数据其实是别的层里面的,所以没有属性变量是可以理解的。
当然也不是说完全没有属性变量,因为这些类都继承了Layer这个最抽象的类。
由于后面的类都是继承NeuronLayer类的,所以我们先来看看NeuronLayer类长什么样:
1 NeuronLayer:
An interface for layers that take one blob as input (@f$ x @f$) and produce one equally-sized blob as output (@f$ y @f$), where each element of the output depends only on the corresponding input element.
定义如下:
template <typename Dtype>
class NeuronLayer : public Layer<Dtype> {
public:
explicit NeuronLayer(const LayerParameter& param)
: Layer<Dtype>(param) {}
virtual void Reshape(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top);
virtual inline LayerParameter_LayerType type() const {
return LayerParameter_LayerType_NONE;
}
virtual inline int ExactNumBottomBlobs() const { return 1; }
virtual inline int ExactNumTopBlobs() const { return 1; }
};这几个函数看起来好像没有什么特别的样子。那么为什么会让它存在呢?还让那么多别的类来继承它?暂时不能理解~
2 AbsValLayer:
Computes @f$ y = |x| @f$
从这个类开始的后面所有类都会涉及到前馈反馈了。
那么我们一个个的来说。
2.1 原理介绍:
这个类顾名思义,就是计算绝对值的:
从构造函数可以看到,这个层是不允许bottom和top一样,也就是说和ReLULayer这种层是不一样的。
前馈的时候将bottom层的数据求绝对值,之后再将数据传递给top层。
反馈的时候可以这样子来看:
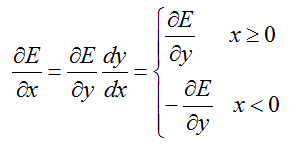
2.2 构造函数:
template <typename Dtype>
void AbsValLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
NeuronLayer<Dtype>::LayerSetUp(bottom, top);
CHECK_NE((*top)[0], bottom[0]) << this->type_name() << " Layer does not "
"allow in-place computation.";
}这里可以看到,通过该类定义的层是不允许bottom层与top层相同的!
2.3 前馈反馈函数:
因为前馈和反馈函数中会用到一些math_function.cpp中的函数,先做一个统一的介绍:
template <>
void caffe_abs<float>(const int n, const float* a, float* y) {
vsAbs(n, a, y);
}
template <>
void caffe_abs<double>(const int n, const double* a, double* y) {
vdAbs(n, a, y);
}相当于是y = |a|,当然都是按元素计算的。
template <>
void caffe_div<float>(const int n, const float* a, const float* b,
float* y) {
vsDiv(n, a, b, y);
}
template <>
void caffe_div<double>(const int n, const double* a, const double* b,
double* y) {
vdDiv(n, a, b, y);
}y = a/b,也都是按元素的。
template <>
void caffe_mul<float>(const int n, const float* a, const float* b,
float* y) {
vsMul(n, a, b, y);
}
template <>
void caffe_mul<double>(const int n, const double* a, const double* b,
double* y) {
vdMul(n, a, b, y);
}y = a * b
现在再来看前馈函数:
template <typename Dtype>
void AbsValLayer<Dtype>::Forward_cpu(
const vector<Blob<Dtype>*>& bottom, vector<Blob<Dtype>*>* top) {
const int count = (*top)[0]->count();
Dtype* top_data = (*top)[0]->mutable_cpu_data();
caffe_abs(count, bottom[0]->cpu_data(), top_data);
}这个就很好理解了吧,相当于是吧bottom中的数据全部求绝对值之后放入top中。
反馈函数:
template <typename Dtype>
void AbsValLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, vector<Blob<Dtype>*>* bottom) {
const int count = top[0]->count();
const Dtype* top_data = top[0]->cpu_data();
const Dtype* top_diff = top[0]->cpu_diff();
if (propagate_down[0]) {
const Dtype* bottom_data = (*bottom)[0]->cpu_data();
Dtype* bottom_diff = (*bottom)[0]->mutable_cpu_diff();
caffe_div(count, top_data, bottom_data, bottom_diff);
caffe_mul(count, bottom_diff, top_diff, bottom_diff);
}
}反馈的时候应该也不难理解,只需要弄清楚top层的误差与bottom层的误差有什么关系。
举个简单的例子,bottom的数据为[2, -3],那么到了top层的数据就变成了[2, 3];如果top层的误差为[1, 2],那么bottom的误差是什么呢?只是与正负号有关系而已,所以先使用top层的数据与bottom的数据做一个除法,得到正负号关系[1, -1],再乘以top层的误差,就变成了bottom层的误差了[1, -2]。仔细想想,你会理解到的。
3 BNLLLayer:
Computes @f$ y = x + \log(1 + \exp(-x)) @f$ if @f$ x > 0 @f$; @f$ y = \log(1 + \exp(x)) @f$ otherwise.
3.1 原理介绍:
全称是:binomial normal log likelihood
前馈的过程是:
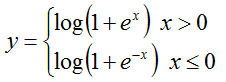
那么反馈呢?感觉前馈都还是相对比较简单,反馈就会变得比较复杂一点,例如这个的反馈:

3.2 前馈反馈函数:
前馈函数:
template <typename Dtype>
void BNLLLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = (*top)[0]->mutable_cpu_data();
const int count = bottom[0]->count();
for (int i = 0; i < count; ++i) {
top_data[i] = bottom_data[i] > 0 ?
bottom_data[i] + log(1. + exp(-bottom_data[i])) :
log(1. + exp(bottom_data[i]));
}
}相当于是直接按照公式计算就是了。
反馈函数:
template <typename Dtype>
void BNLLLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
vector<Blob<Dtype>*>* bottom) {
if (propagate_down[0]) {
const Dtype* bottom_data = (*bottom)[0]->cpu_data();
const Dtype* top_diff = top[0]->cpu_diff();
Dtype* bottom_diff = (*bottom)[0]->mutable_cpu_diff();
const int count = (*bottom)[0]->count();
Dtype expval;
for (int i = 0; i < count; ++i) {
expval = exp(std::min(bottom_data[i], Dtype(kBNLL_THRESHOLD)));
bottom_diff[i] = top_diff[i] * expval / (expval + 1.);
}
}
}其中的expval中涉及到了一个kBNLL_THRESHOLD,具体的作用是什么呢?
然后expval/(expval+1)相当于是前馈函数的导数。
4 DropoutLayer:
During training only, sets a random portion of @f$x@f$ to 0, adjusting the rest of the vector magnitude accordingly.
4.1 原理介绍:
只将部分的数据传递下去,感觉有点类似于pooling(类似于随机降采样),只是在这里的过滤器大小就是bottom的大小,而且传递下去的值还做了缩放。
4.2 属性变量:
/// when divided by UINT_MAX, the randomly generated values @f$u\sim U(0,1)@f$
Blob<unsigned int> rand_vec_;
/// the probability @f$ p @f$ of dropping any input
Dtype threshold_;
/// the scale for undropped inputs at train time @f$ 1 / (1 - p) @f$
Dtype scale_;
unsigned int uint_thres_;rand_vec_:在后面的Reshape()函数中会看到,该Blob的大小跟bottom的一样。还是服从二项分布的,也就是说,这个里面只存储0-1两种值。
threashold_:相当于是有多少比例的元素会被丢掉。
scale_:应该是用于将没有丢掉的元素做一个缩放。
4.3 构造函数:
template <typename Dtype>
void DropoutLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
NeuronLayer<Dtype>::LayerSetUp(bottom, top);
threshold_ = this->layer_param_.dropout_param().dropout_ratio();
DCHECK(threshold_ > 0.);
DCHECK(threshold_ < 1.);
scale_ = 1. / (1. - threshold_);
uint_thres_ = static_cast<unsigned int>(UINT_MAX * threshold_);
}
template <typename Dtype>
void DropoutLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
NeuronLayer<Dtype>::Reshape(bottom, top);
// Set up the cache for random number generation
rand_vec_.Reshape(bottom[0]->num(), bottom[0]->channels(),
bottom[0]->height(), bottom[0]->width());
}在LayerSetUp中看到,threashold_的取值范围是(0,1)。
4.4 前馈和反馈函数:
前馈函数:
template <typename Dtype>
void DropoutLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = (*top)[0]->mutable_cpu_data();
unsigned int* mask = rand_vec_.mutable_cpu_data();
const int count = bottom[0]->count();
if (Caffe::phase() == Caffe::TRAIN) {
// Create random numbers
caffe_rng_bernoulli(count, 1. - threshold_, mask);
for (int i = 0; i < count; ++i) {
top_data[i] = bottom_data[i] * mask[i] * scale_;
}
} else {
caffe_copy(bottom[0]->count(), bottom_data, top_data);
}
}这里用到了一个boost里面的随机数触发器:(math_function.cpp中)
template <typename Dtype>
void caffe_rng_bernoulli(const int n, const Dtype p, int* r) {
CHECK_GE(n, 0);
CHECK(r);
CHECK_GE(p, 0);
CHECK_LE(p, 1);
boost::bernoulli_distribution<Dtype> random_distribution(p);
boost::variate_generator<caffe::rng_t*, boost::bernoulli_distribution<Dtype> >
variate_generator(caffe_rng(), random_distribution);
for (int i = 0; i < n; ++i) {
r[i] = variate_generator();
}
}
template
void caffe_rng_bernoulli<double>(const int n, const double p, int* r);
template
void caffe_rng_bernoulli<float>(const int n, const float p, int* r);
template <typename Dtype>
void caffe_rng_bernoulli(const int n, const Dtype p, unsigned int* r) {
CHECK_GE(n, 0);
CHECK(r);
CHECK_GE(p, 0);
CHECK_LE(p, 1);
boost::bernoulli_distribution<Dtype> random_distribution(p);
boost::variate_generator<caffe::rng_t*, boost::bernoulli_distribution<Dtype> >
variate_generator(caffe_rng(), random_distribution);
for (int i = 0; i < n; ++i) {
r[i] = static_cast<unsigned int>(variate_generator());
}
}
template
void caffe_rng_bernoulli<double>(const int n, const double p, unsigned int* r);
template
void caffe_rng_bernoulli<float>(const int n, const float p, unsigned int* r);这里不做详细的说明,也就是建立一个二项分布的随机数触发器。二项分布中的两个参数p, q。属性变量中给定的threashold_就是q。
随机数矩阵rand_vec_产生好了之后,其余的代码很好读,需要注意的是,droping只发生在训练阶段。
反馈函数:
template <typename Dtype>
void DropoutLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
vector<Blob<Dtype>*>* bottom) {
if (propagate_down[0]) {
const Dtype* top_diff = top[0]->cpu_diff();
Dtype* bottom_diff = (*bottom)[0]->mutable_cpu_diff();
if (Caffe::phase() == Caffe::TRAIN) {
const unsigned int* mask = rand_vec_.cpu_data();
const int count = (*bottom)[0]->count();
for (int i = 0; i < count; ++i) {
bottom_diff[i] = top_diff[i] * mask[i] * scale_;
}
} else {
caffe_copy(top[0]->count(), top_diff, bottom_diff);
}
}
}但是从源码来看,前馈是放大了的!但是反馈怎么还是在放大呢?怀疑是源码写错了!感觉反馈中的那句代码应该是写成:
<del>bottom_diff[i] = top_diff[i] * mask[i] / scale_;</del>回答这里的问题:
根据误差传递的链式法则:
假设前馈的时候y = alpha*x,其中alpha>1。
最终产生的误差为E,则反馈的时候,x对这个误差产生的影响为:
可能此时会觉得很奇怪,为什么还是乘以,而不是除呢?如果我们暂时考虑只有一层的网络,这一层的激活函数就是:y = alpha * x;那么最终产生的误差为:E = y - y' (其中y'表示观测的真实值);令E' = x - x',(假象也存在一个x' 表示观测的真实值),那么此时就会有E/E' = alpha,如果直接将E传递回来,就应该除以alpha。
但是根据BP原理,我们反馈传递回来的不是E,而是E对每个参数的偏导,或者说是某参数对最终误差产生了多大影响。
下面的公式可能会对理解起来有些帮助:
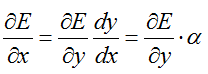

5 PowerLayer:
Computes @f$ y = (\alpha x + \beta) ^ \gamma @f$, as specified by the scale @f$ \alpha @f$, shift @f$ \beta @f$, and power @f$ \gamma @f$.
5.1 原理介绍
前馈:
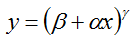
反馈:
其中的 {E对y求偏导} 也就相当于是在介绍第3个类(BNLLLayer)反馈原理中的top_diff

5.2 属性变量
/// @brief @f$ \gamma @f$ from layer_param_.power_param()
Dtype power_;
/// @brief @f$ \alpha @f$ from layer_param_.power_param()
Dtype scale_;
/// @brief @f$ \beta @f$ from layer_param_.power_param()
Dtype shift_;
/// @brief Result of @f$ \alpha \gamma @f$
Dtype diff_scale_;这里前三个变量的注释很清楚,也就是分别对应前馈公式里面的三个参数。
那么diff_scale_是什么呢?注意到在反馈的公式中存在两个参数相乘(alpha * gamma),这两个参数的乘积被定义为diff_scale_。
5.3 前馈反馈函数:
前馈:
// Compute y = (shift + scale * x)^power
template <typename Dtype>
void PowerLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
Dtype* top_data = (*top)[0]->mutable_cpu_data();
const int count = bottom[0]->count();
// Special case where we can ignore the input: scale or power is 0.
if (diff_scale_ == Dtype(0)) {
Dtype value = (power_ == 0) ? Dtype(1) : pow(shift_, power_);
caffe_set(count, value, top_data);
return;
}
const Dtype* bottom_data = bottom[0]->cpu_data();
caffe_copy(count, bottom_data, top_data);
if (scale_ != Dtype(1)) {
caffe_scal(count, scale_, top_data);
}
if (shift_ != Dtype(0)) {
caffe_add_scalar(count, shift_, top_data);
}
if (power_ != Dtype(1)) {
caffe_powx(count, top_data, power_, top_data);
}
}这里很容易理解,其中涉及到的几个math_function.cpp中的函数,自己查一下吧。
反馈:
template <typename Dtype>
void PowerLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
vector<Blob<Dtype>*>* bottom) {
if (propagate_down[0]) {
Dtype* bottom_diff = (*bottom)[0]->mutable_cpu_diff();
const int count = (*bottom)[0]->count();
const Dtype* top_diff = top[0]->cpu_diff();
if (diff_scale_ == Dtype(0) || power_ == Dtype(1)) {
caffe_set(count, diff_scale_, bottom_diff);
} else {
const Dtype* bottom_data = (*bottom)[0]->cpu_data();
// Compute dy/dx = scale * power * (shift + scale * x)^(power - 1)
// = diff_scale * y / (shift + scale * x)
if (power_ == Dtype(2)) {
// Special case for y = (shift + scale * x)^2
// -> dy/dx = 2 * scale * (shift + scale * x)
// = diff_scale * shift + diff_scale * scale * x
caffe_cpu_axpby(count, diff_scale_ * scale_, bottom_data,
Dtype(0), bottom_diff);
if (shift_ != Dtype(0)) {
caffe_add_scalar(count, diff_scale_ * shift_, bottom_diff);
}
} else if (shift_ == Dtype(0)) {
// Special case for y = (scale * x)^power
// -> dy/dx = scale * power * (scale * x)^(power - 1)
// = scale * power * (scale * x)^power * (scale * x)^(-1)
// = power * y / x
const Dtype* top_data = top[0]->cpu_data();
caffe_div(count, top_data, bottom_data, bottom_diff);
caffe_scal(count, power_, bottom_diff);
} else {
caffe_copy(count, bottom_data, bottom_diff);
if (scale_ != Dtype(1)) {
caffe_scal(count, scale_, bottom_diff);
}
if (shift_ != Dtype(0)) {
caffe_add_scalar(count, shift_, bottom_diff);
}
const Dtype* top_data = top[0]->cpu_data();
caffe_div<Dtype>(count, top_data, bottom_diff, bottom_diff);
if (diff_scale_ != Dtype(1)) {
caffe_scal(count, diff_scale_, bottom_diff);
}
}
}
if (diff_scale_ != Dtype(0)) {
caffe_mul(count, top_diff, bottom_diff, bottom_diff);
}
}
}这里读起来也不算难,注意的是这里将前馈的函数分成了三种情况来分别处理的,分别是:
1 当power=1或者diff_scale_=0 (也就是:gamma=1 或者 alpha*gamma=0);
2 当shift=0 (也就是:beta=0);
3 其余情况。
6 ReLULayer:
Rectified Linear Unit non-linearity @f$ y = \max(0, x) @f$. The simple max is fast to compute, and the function does not saturate.
6.1 原理介绍:
前馈:
前馈的时候,有些版本的介绍是简单的max{0,x},但是caffe源码中为了可以更加普遍的调整参数,可以修改临界值,而不是只能够为0。下面用通用一点的,源码中的式子来描述:
其中,nu,为参数,在配置网络模型的时候可以选择设置,默认为0。
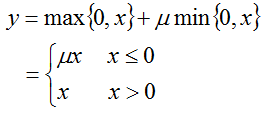
反馈:
同样遵循反馈时误差传递的链式法则:
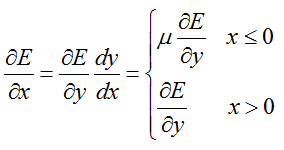
6.2 前馈反馈函数:
有了前面基本原理的介绍,下面的代码读起来就容易得多了。
前馈函数:
template <typename Dtype>
void ReLULayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = (*top)[0]->mutable_cpu_data();
const int count = bottom[0]->count();
Dtype negative_slope = this->layer_param_.relu_param().negative_slope();
for (int i = 0; i < count; ++i) {
top_data[i] = std::max(bottom_data[i], Dtype(0))
+ negative_slope * std::min(bottom_data[i], Dtype(0));
}
}反馈函数:
template <typename Dtype>
void ReLULayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
vector<Blob<Dtype>*>* bottom) {
if (propagate_down[0]) {
const Dtype* bottom_data = (*bottom)[0]->cpu_data();
const Dtype* top_diff = top[0]->cpu_diff();
Dtype* bottom_diff = (*bottom)[0]->mutable_cpu_diff();
const int count = (*bottom)[0]->count();
Dtype negative_slope = this->layer_param_.relu_param().negative_slope();
for (int i = 0; i < count; ++i) {
bottom_diff[i] = top_diff[i] * ((bottom_data[i] > 0)
+ negative_slope * (bottom_data[i] <= 0));
}
}
}反馈函数中稍微有点小意思:注意看代码,将大于0和小于0都写在了一个括号里面体现了,而不是所谓的if...else...
7 SigmoidLayer:
Sigmoid function non-linearity @f$ y = (1 + \exp(-x))^{-1} @f$, a classic choice in neural networks.
Note that the gradient vanishes as the values move away from 0.
The ReLULayer is often a better choice for this reason.
7.1 原理介绍:
前馈:
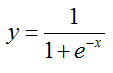
反馈:
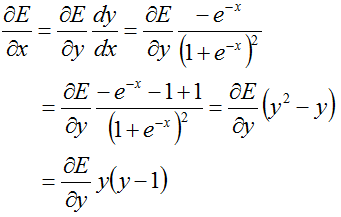
7.2 前馈反馈函数:
sigmoid函数:
template <typename Dtype>
inline Dtype sigmoid(Dtype x) {
return 1. / (1. + exp(-x));
}前馈函数:
template <typename Dtype>
void SigmoidLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = (*top)[0]->mutable_cpu_data();
const int count = bottom[0]->count();
for (int i = 0; i < count; ++i) {
top_data[i] = sigmoid(bottom_data[i]);
}
}反馈函数:
template <typename Dtype>
void SigmoidLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
vector<Blob<Dtype>*>* bottom) {
if (propagate_down[0]) {
const Dtype* top_data = top[0]->cpu_data();
const Dtype* top_diff = top[0]->cpu_diff();
Dtype* bottom_diff = (*bottom)[0]->mutable_cpu_diff();
const int count = (*bottom)[0]->count();
for (int i = 0; i < count; ++i) {
const Dtype sigmoid_x = top_data[i];
bottom_diff[i] = top_diff[i] * sigmoid_x * (1. - sigmoid_x);
}
}
}反馈中的代码,不知道为啥要设置一个中间变量sigmoid_x,为了方便理解吗?感觉这个变量名字还容易引起歧义,不便于理解。根据反馈原理,直接使用top_data就好了嘛。
8 TanHLayer:
TanH hyperbolic tangent non-linearity @f$ y = \frac{\exp(2x) - 1}{\exp(2x) + 1} @f$, popular in auto-encoders.
Note that the gradient vanishes as the values move away from 0.
The ReLULayer is often a better choice for this reason.
8.1 原理介绍:
前馈:
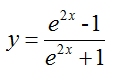
反馈:
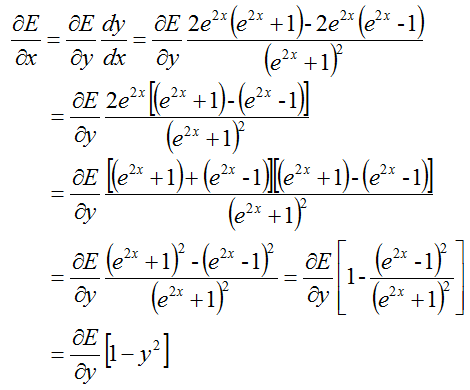
8.2 前馈反馈函数:
前馈:
template <typename Dtype>
void TanHLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = (*top)[0]->mutable_cpu_data();
Dtype exp2x;
const int count = bottom[0]->count();
for (int i = 0; i < count; ++i) {
exp2x = exp(2 * bottom_data[i]);
top_data[i] = (exp2x - Dtype(1)) / (exp2x + Dtype(1));
}
}反馈:
template <typename Dtype>
void TanHLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
vector<Blob<Dtype>*>* bottom) {
if (propagate_down[0]) {
const Dtype* top_data = top[0]->cpu_data();
const Dtype* top_diff = top[0]->cpu_diff();
Dtype* bottom_diff = (*bottom)[0]->mutable_cpu_diff();
const int count = (*bottom)[0]->count();
Dtype tanhx;
for (int i = 0; i < count; ++i) {
tanhx = top_data[i];
bottom_diff[i] = top_diff[i] * (1 - tanhx * tanhx);
}
}
}这里的前馈反馈计算模式跟sigmoid一模一样的。
9 ThresholdLayer:
Tests whether the input exceeds a threshold: outputs 1 for inputs above threshold; 0 otherwise.
9.1 原理介绍:
顾名思义,对于给定的一个阈值:超过阈值了输出某个值;没有超过输出另外一个值。
所以就产生了下面的传递方式:
前馈:
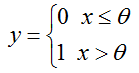
这种层只进行前馈?在源码中没有反馈函数!!好吧,具体什么网络里面会用这种层呢?不反馈的话,用它有什么意思啊?
难道说是用在最后分类的时候?例如概率大于0.5的值变成1,小于0.5的变成0,最后就转换成0-1向量了,进行分类?
9.2 属性变量:
也就是一个对于这个层而已比较独特的属性变量,阈值变量:
Dtype threshold_;9.3 前馈函数:
template <typename Dtype>
void ThresholdLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = (*top)[0]->mutable_cpu_data();
const int count = bottom[0]->count();
for (int i = 0; i < count; ++i) {
top_data[i] = (bottom_data[i] > threshold_) ? Dtype(1) : Dtype(0);
}
}















 1399
1399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









