







高性能IO模型
为什么单线程Redis能那么快
- 一方面,Redis 的大部分操作在内存上完成,再加上它采用了高效的数据结构,例如哈希表和跳表,这是它实现高性能的一个重要原因。
- 另一方面,就是 Redis 采用了多路复用机制,使其在网络 IO 操作中能并发处理大量的客户端请求,实现高吞吐率。
6.0 为啥采用多线程
Redis基本IO模型
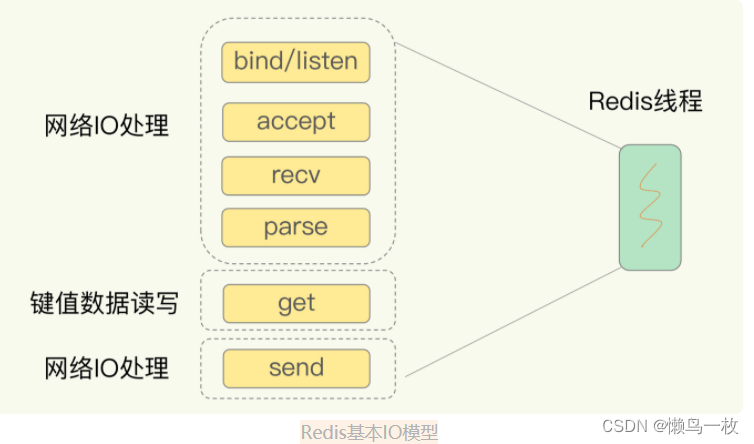
在 socket 模型中,不同操作调用后会返回不同的套接字类型。socket() 方法会返回主动套接字,然后调用 listen() 方法,将主动套接字转化为监听套接字,此时,可以监听来自客户端的连接请求。最后,调用 accept() 方法接收到达的客户端连接,并返回已连接套接字。
针对监听套接字,我们可以设置非阻塞模式:当 Redis 调用 accept() 但一直未有连接请求到达时,Redis 线程可以返回处理其他操作,而不用一直等待。但是,你要注意的是,调用 accept() 时,已经存在监听套接字了。
虽然 Redis 线程可以不用继续等待,但是总得有机制继续在监听套接字上等待后续连接请求,并在有请求时通知 Redis;类似的,我们也可以针对已连接套接字设置非阻塞模式:Redis 调用 recv() 后,如果已连接套接字上一直没有数据到达,Redis 线程同样可以返回处理其他操作。我们也需要有机制继续监听该已连接套接字,并在有数据达到时通知 Redis;
这样才能保证 Redis 线程,既不会像基本 IO 模型中一直在阻塞点等待,也不会导致 Redis 无法处理实际到达的连接请求或数据
Linux 中的 IO 多路复用机制就要登场了。基于多路复用的高性能 I/O 模型
redis中日志
Redis 的持久化主要有两大机制,即 AOF(Append Only File)日志和 RDB 快照
AOF日志
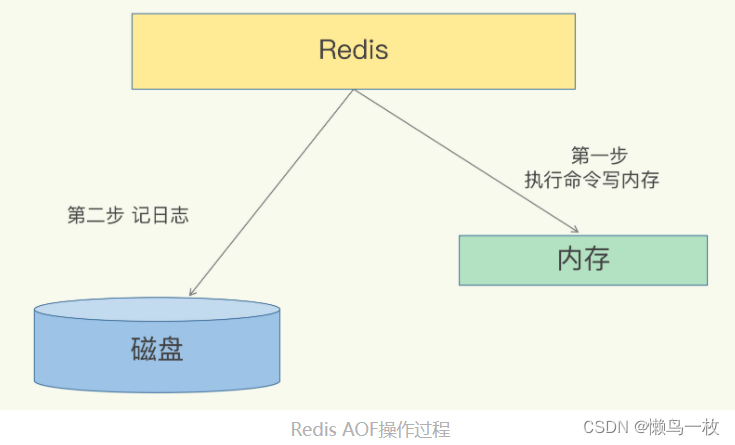
较熟悉的是数据库的写前日志(Write Ahead Log, WAL),也就是说,在实际写数据前,先把修改的数据记到日志文件中,以便故障时进行恢复。不过,AOF 日志正好相反,它是写后日志,“写后”的意思是 Redis 是先执行命令,把数据写入内存,然后才记录日志,Redis 使用写后日志这一方式的一大好处是,可以避免出现记录错误命令的情况。除此之外,AOF 还有一个好处:它是在命令执行后才记录日志,所以不会阻塞当前的写操作。
AOF 也有两个潜在的风险。
- 首先,如果刚执行完一个命令,还没有来得及记日志就宕机了,那么这个命令和相应的数据就有丢失的风险。
- 其次,AOF 虽然避免了对当前命令的阻塞,但可能会给下一个操作带来阻塞风险。这是因为,AOF 日志也是在主线程中执行的,如果在把日志文件写入磁盘时,磁盘写压力大,就会导致写盘很慢,进而导致后续的操作也无法执行了。
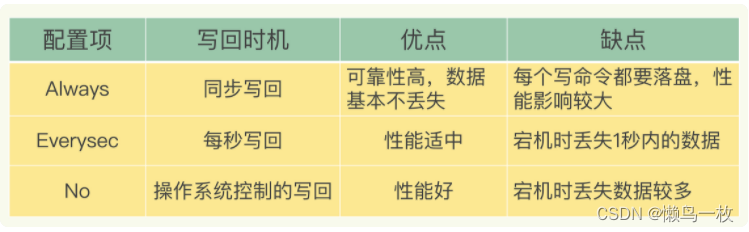
三种写回策略
AOF 重写机制
AOF 是以文件的形式在记录接收到的所有写命令。随着接收的写命令越来越多,AOF 文件会越来越大。这也就意味着,我们一定要小心 AOF 文件过大带来的性能问题;
这里的“性能问题”,主要在于以下三个方面:一是,文件系统本身对文件大小有限制,无法保存过大的文件;二是,如果文件太大,之后再往里面追加命令记录的话,效率也会变低;三是,如果发生宕机,AOF 中记录的命令要一个个被重新执行,用于故障恢复,如果日志文件太大,整个恢复过程就会非常缓慢,这就会影响到 Redis 的正常使用。
AOF 重写机制就是在重写时,Redis 根据数据库的现状创建一个新的 AOF 文件,也就是说,读取数据库中的所有键值对,然后对每一个键值对用一条命令记录它的写入。比如说,当读取了键值对“testkey”: “testvalue”之后,重写机制会记录 set testkey testvalue 这条命令。这样,当需要恢复时,可以重新执行该命令,实现“testkey”: “testvalue”的写入。
AOF 重写会阻塞吗
和 AOF 日志由主线程写回不同,重写过程是由后台子进程 bgrewriteaof 来完成的,这也是为了避免阻塞主线程,导致数据库性能下降。
一个拷贝”就是指,每次执行重写时,主线程 fork 出后台的 bgrewriteaof 子进程。此时,fork 会把主线程的内存拷贝一份给 bgrewriteaof 子进程,这里面就包含了数据库的最新数据。然后,bgrewriteaof 子进程就可以在不影响主线程的情况下,逐一把拷贝的数据写成操作,记入重写日志。
这样,重写日志也不会丢失最新的操作。等到拷贝数据的所有操作记录重写完成后,重写日志记录的这些最新操作也会写入新的 AOF 文件,以保证数据库最新状态的记录。此时,我们就可以用新的 AOF 文件替代旧文件了。
但是,在“用日志”的过程中,也就是使用 AOF 进行故障恢复时,我们仍然需要把所有的操作记录都运行一遍。再加上 Redis 的单线程设计,这些命令操作只能一条一条按顺序执行,这个“重放”的过程就会很慢了。
那么,有没有既能避免数据丢失,又能更快地恢复的方法呢?当然有,那就是 RDB 快照了。下节课,我们就一起学习一下,敬请期待。
内存快照RDB:宕机后,Redis如何实现快速恢复
内存快照。所谓内存快照,就是指内存中的数据在某一个时刻的状态记录。这就类似于照片,当你给朋友拍照时,一张照片就能把朋友一瞬间的形象完全记下来。
和 AOF 相比,RDB 记录的是某一时刻的数据,并不是操作,所以,在做数据恢复时,我们可以直接把 RDB 文件读入内存,很快地完成恢复。听起来好像很不错,但内存快照也并不是最优选项
给哪些内存数据做快照
针对任何操作,我们都会提一个灵魂之问:“它会阻塞主线程吗?”RDB 文件的生成是否会阻塞主线程,这就关系到是否会降低 Redis 的性能
save:在主线程中执行,会导致阻塞;bgsave:创建一个子进程,专门用于写入 RDB 文件,避免了主线程的阻塞,这也是 Redis RDB 文件生成的默认配置。我们就可以通过 bgsave 命令来执行全量快照,这既提供了数据的可靠性保证,也避免了对 Redis 的性能影响。
这个问题非常重要,这是因为,如果数据能被修改,那就意味着 Redis 还能正常处理写操作。否则,所有写操作都得等到快照完了才能执行,性能一下子就降低了
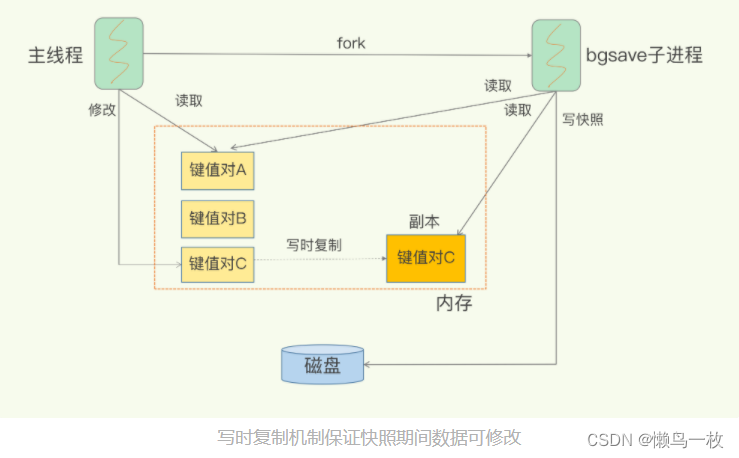
写时复制技术(Copy-On-Write, COW)
避免阻塞和正常处理写操作并不是一回事。此时,主线程的确没有阻塞,可以正常接收请求,但是,为了保证快照完整性,它只能处理读操作,因为不能修改正在执行快照的数据。为了快照而暂停写操作,肯定是不能接受的。所以这个时候,Redis 就会借助操作系统提供的写时复制技术(Copy-On-Write, COW),在执行快照的同时,正常处理写操作。简单来说,bgsave 子进程是由主线程 fork 生成的,可以共享主线程的所有内存数据。bgsave 子进程运行后,开始读取主线程的内存数据,并把它们写入 RDB 文件。此时,如果主线程对这些数据也都是读操作(例如图中的键值对 A),那么,主线程和 bgsave 子进程相互不影响。但是,如果主线程要修改一块数据(例如图中的键值对 C),那么,这块数据就会被复制一份,生成该数据的副本。然后,bgsave 子进程会把这个副本数据写入 RDB 文件,而在这个过程中,主线程仍然可以直接修改原来的数据。
可以每秒做一次快照吗
增量快照
我们可以做增量快照,所谓增量快照,就是指,做了一次全量快照后,后续的快照只对修改的数据进行快照记录,这样可以避免每次全量快照的开销。
在第一次做完全量快照后,T1 和 T2 时刻如果再做快照,我们只需要将被修改的数据写入快照文件就行。但是,这么做的前提是,我们需要记住哪些数据被修改了。你可不要小瞧这个“记住”功能,它需要我们使用额外的元数据信息去记录哪些数据被修改了,这会带来额外的空间开销问题。
Redis 4.0 中提出了一个混合使用 AOF 日志和内存快照的方法。简单来说,内存快照以一定的频率执行,在两次快照之间,使用 AOF 日志记录这期间的所有命令操作。这样一来,快照不用很频繁地执行,这就避免了频繁 fork 对主线程的影响。而且,AOF 日志也只用记录两次快照间的操作,也就是说,不需要记录所有操作了,因此,就不会出现文件过大的情况了,也可以避免重写开销。
关于 AOF 和 RDB 的选择问三点建议:
- 数据不能丢失时,内存快照和 AOF 的混合使用是一个很好的选择;
- 如果允许分钟级别的数据丢失,可以只使用 RDB;
- 如果只用 AOF,优先使用 everysec 的配置选项,因为它在可靠性和性能之间取了一个平衡。















 1203
1203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









