









本文包括三点:1.配置hadoop的伪分布式 2.将hadoop添加到环境变量 3.格式化HDFS
1.由于我们是在单机上面建立的“伪”分布式 我们要修改4个文件,大多数是xml文件
配置hadoop伪分布式(要修改4个文件)
第一个:hadoop-env.sh
vim hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.6.0_45
第二个:core-site.xml
vim core-site.xml
<configuration>
<!-- 指定HDFS的namenode的通信地址 -->
<property>
<name>fs.default.name</name>
<value>hdfs://itcast:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存放目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/cloud/hadoop-1.1.2/tmp</value>
</property>
</configuration>
注意!!这里在最后格式化的时候【hdfs namenode -format】会报错,报错说
ERROR - Fatal Error : The processing instruction target matching "[xX][mM][lL]" is not allowed. Nested exception: The processing instruction target matching "[xX][mM][lL]" is not allowed.

异常解释:
xml文件不能被解析,一般出现这样的问题在于xml格式上,并且问题多出现在xml文件的头部。
原因:
一般多是因为xml文件头部有了空格或回车导致的
总结:
<?xml version="1.0" encoding="UTF-8"?>前面不要有任何其他字符,如空格、回车、换行这些否则就会出现上面的异常。
第三个:hdfs-site.xml
vim hdfs-site.xml
<configuration>
<!-- 配置HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
第四个:mapred-site.xml
vim mapred-site.xml
<configuration>
<!-- 指定jobtracker地址 -->
<property>
<name>mapred.job.tracker</name>
<value>itcast:9001</value>
</property>
</configuration>
2.将hadoop添加到环境变量
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.6.0_45
export HADOOP_HOME=/cloud/hadoop-1.1.2
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
source /etc/profile
3.格式化HDFS
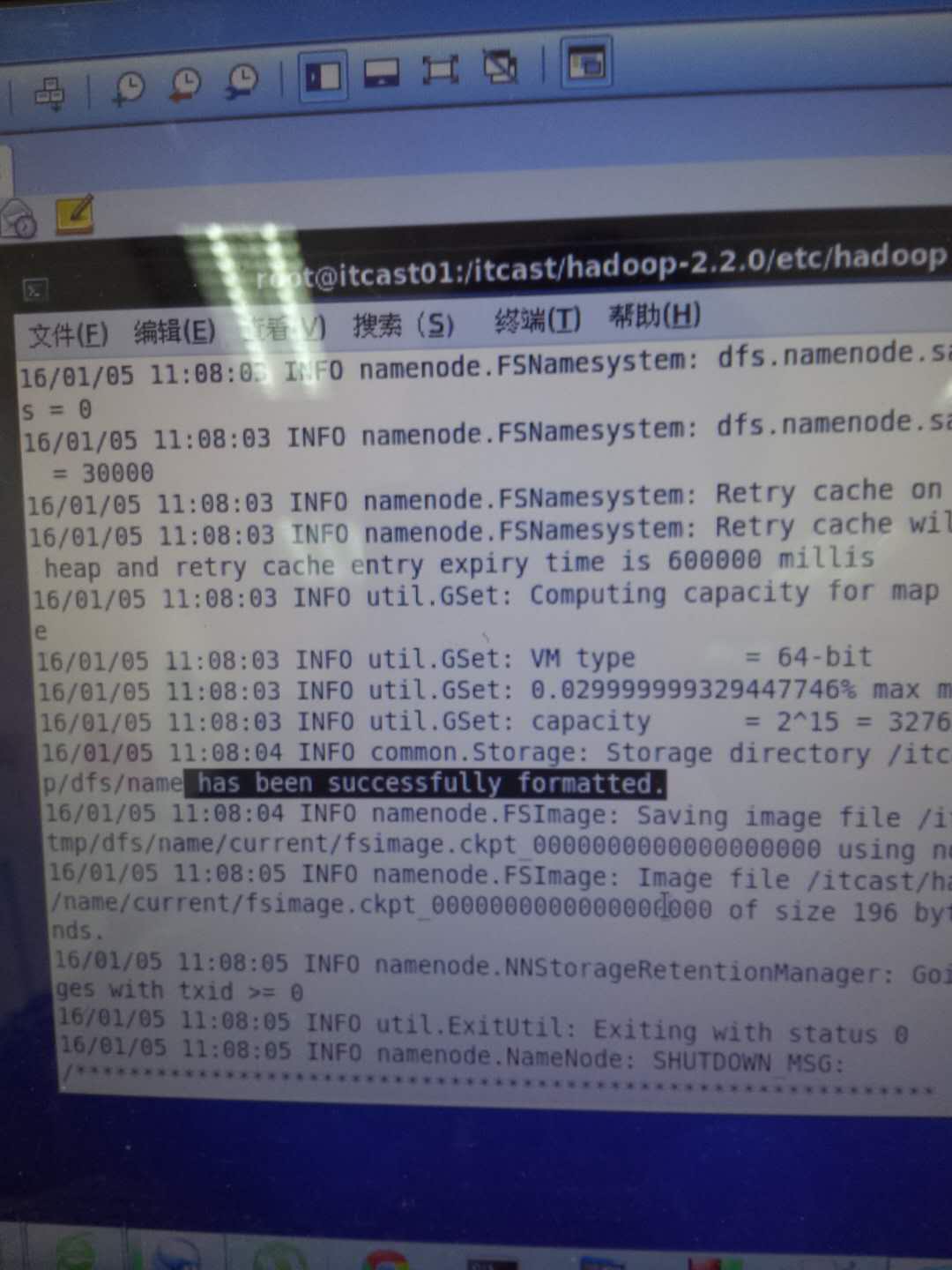
hadoop namenode -format
之前如果不成功,会出现类似之前照片里出现的东西,ERROR等等之类的,需要根据提示出现的error来确认到底哪里出了问题
如果出现“successfully formatted 就说明格式化成功了

















 2520
2520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









