









mapper和reducer输入和输出都是以(key,value)形式的
Group,分组,按照key2来分组,然后将v2放在一个集合中,作为一个value
如果我们想实现mapreduce模型,只需要重写map方法和reduce方法即可,适合各种业务。
mapreduce执行过程:
map任务:
1.读取文件内容,一行内容解析成一个key,value【怎么做的?一会儿介绍】一个(key,value)对执行一次map函数方法
2.在map里实现自己的业务逻辑,转换成新的key,value,然后输出
3.对输入的key,value分区
4.对不同分区的数据,排序分组。
一个inputspilt对应一个mapper【每个mapper只需要计算自己的数据】
reduce任务:
【此时已经完成了分区排序分组】
1.到mapper里面取数据
2.对多个map任务的输出,合并,排序,写reduce函数自己的业务逻辑,对输入的key,value进行处理,转换成新的key,value
3.reduce的输出保存到文献中。
例子:先运行一个mapreduce
【HDFS】启动起来并不能运行mapreduce,还得启动Yarn ./start-yarn.sh 【记得hadoop2.0都保存在sbin里面】
打开centos,打开yarn之后,首先,我创建一个word文件,
1.把文件上传到hdfs里;hadoop fs -put words【这个是相对目录,我本地这个目录下正好有words,我就不同全部都写路径了】 /words.txt【这个是hdfs里的路径】
之后检查一下是否写入 hadoop fs -ls /
成功之后运行mapreduce【找个jar包运行】:hadoop jar 【接下来接jar所在的位置】hadoop-mapreduce-examples-2.2.0.jar wordcount 【然后接输入和输出】/words.txt /wcout
运行时间十分漫长,之后等出现map100% reduce100%的时候,就可以了。
打开ls看一看是否存在

发现wcout里面有一个part-r-00000【貌似是接口文件?不懂。。】,然后cat它看一眼,就能得到我们的Wordcount结果

接下来分析一下Wordcount流程:
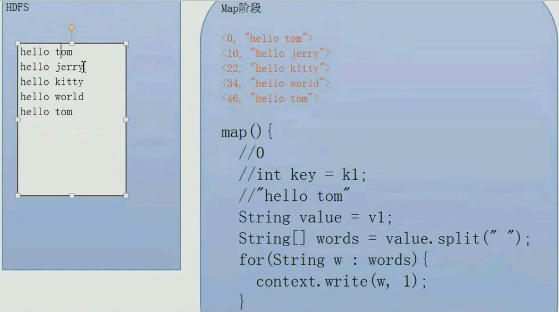
key,value是以字符偏移的
map阶段,一边解析【一个IO流把文件读取到内存】一边运行,一行一个map过程
map过程的伪代码如上。map方法,输入输出都是key,value。我的key是数字类型,但是对计算Wordcount没啥用。

key是k1,value是字符串,然后用split函数以空格作为分割,然后强for循环,每个输出的单词w,作为k2,【也就是输出key】,然后v2设置为1,然后最后可以根据key【k2】相加计算wordcount
reduce阶段
【还记得上次说的,shuffle作用是数据的排序,传递和分组,之后按照k2把value变成一个集合】

按照k2的默认字典顺序,已经排好序了【所以第一个是hello没说的,第二个是jerry而不是tom!】
以上是解析完成状态,接下来执行reduce方法
在reduce方法里,我们这个业务,将对它进行记数【别的可能是求和等等】

此时,v2的集合变成了v2s,最后,把k2当做key,把counter当做value输出















 427
427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









