







Hadoop streaming里的key和value格式不一样,实际上虽然也是以K1,V1输入输出的,但是是以line的格式输出的。因此中间经过partition过后的K2,V2S的那个iterable的函数格式貌似是没有的!
比如,我想写一个wordcount
在Python中,标准输入输出格式是:
import sys
for line in sys.stdin:每一行是一个输入,然后进入之后的K1,V1你自己切分,自己搞成想要的K2,V2之后,print出来!!
print的格式是print K2+”\t”+V2
这样print出来的格式实际上是print了一行【一个line】,系统会自动默认识别第一个\t 把前面作为key自动给partition了
然后reducer的时候,你同样要
for line in sys.stdin:
然后把partition过后的每一个line收进来。自己处理。
附上一段转自别人博客的话:
Hadoop Streaming编程
一、概述
Hadoop Streaming是Hadoop提供的一个编程工具,它允许用户使用任何可执行文件或者脚本作为Mapper和Reducer,例如:
采用shell脚本语言中的一些命令作为mapper和reducer(cat作为mapper,wc作为reduce)
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/contrib/streaming/hadoop-*-streaming.jar\
-input myInputDir\
-output myOutputDir\
-mapper cat\
-reducer wc
本文安排如下,第二节介绍Hadoop Streaming的原理,第三节介绍Hadoop Streaming的使用方法,第四节介绍Hadoop Streaming的程序编写方法,在这一节中,使用C++、C、Shell脚本和python实现了WordCount作业,第五节总结了常见的问题。
二、Hadoop Streaming原理
mapper和reducer会从标准输入中读取用户数据,一行一行处理后发送给标准输出。Streaming工具会创建MapReduce作业,发送给各个tasktracker,同时监控整个作业的执行过程。
如果一个文件(可执行或者脚本)作为mapper,mapper初始化时,每一个mapper任务会把该文件作为一个单独进程启动,mapper任务运行时,它把输入切分成行,并把每一行提供给可执行文件进程的标准输入。同时,mapper收集可执行文件进程标准输出的内容,并把收到的每一行内容转化为key/value对,作为mapper的输出。默认情况下,一行中第一个tab之前的部分作为key,之后的(不包括tab)作为value。如果没有tab,整行作为key值,value值为null。
对于reducer,类似。
以上是Map/Reduce框架和Streaming Mapper/Reduce之间的基本通信协议。
三、Hadoop Streaming用法
四、Mapper和Reducer实现
本节试图用尽可能多的语言编写Mapper和Reducer,包括java、C、C++、shell脚本、python等。
由于hadoop会自动解析数据文件到Mapper或者Reducer的标准输入中,以供它们读取使用,所以应先了解各个语言获取标准输入的方法。
现在写一个wordcount:目的是要统计adult=1的文件里,各自文字出现的频率。
输入line格式如下所示:
u’20111725 13,模特表演,专业课 独家,青春,模特,时尚,舞台 1’
最前面是ID,后面接一个tab键,然后是标签,然后再接一个tab键;然后是标题名称的切分,最后是输出判定:为1。
因为要做文本分类词向量模型,所以掐头去尾,只留中间标签。
mapper:
#!/usr/bin/python
#-*-coding:utf-8-*-
#!Author:tianbowen@letv.com
# Modified: 20160615
import sys
# a=[u'20111725 13,模特表演,专业课 独家,青春,模特,时尚,舞台 1']
for line in sys.stdin:
line=line.strip().split()
# for w in sp:
# print w
# key=sp[0]
value=line[1:-1]
value_str=",".join(value)
value_list=value_str.split(",")
for key1 in value_list:
print key1+"\t"+str(1)
打印出的类似于

接下来用 key + \t + 1的每一个line当做输出,print之后,经过partition之后,把key相同的自动被放到同一个reducer上
reducer代码:
test_list=[u'男人 1',u'男人 1',u'泼水节 1',u'泼水节 1',u'泼水节 1',u'泼水节 1',u'泼水节 1',u'猥亵 1']
# import os
# import sys
# sys.path.append("./")
# sys.path.append("/data/programs/common/python/")
# reload(sys)
word2count_dict={}
for line in test_list:
line=line.strip()
word,count=line.split()
try:
count=int(count)
word2count_dict[word]=word2count_dict.get(word,0)+count
except ValueError:
pass
sorted_word2count_list=sorted(word2count_dict.iteritems(),key=lambda d:d[1],reverse=True)
for word_count_tuple in sorted_word2count_list:
print word_count_tuple[0]+"\t"+str(word_count_tuple[1])这里有两个注意点:1.关于字典word2count_dict的值提取过程。经常情况下,当没有该key的时候,用这种方式总会报错。现在,用.get函数,并设置一个default值,问题得到了解决
get函数的定义如下:
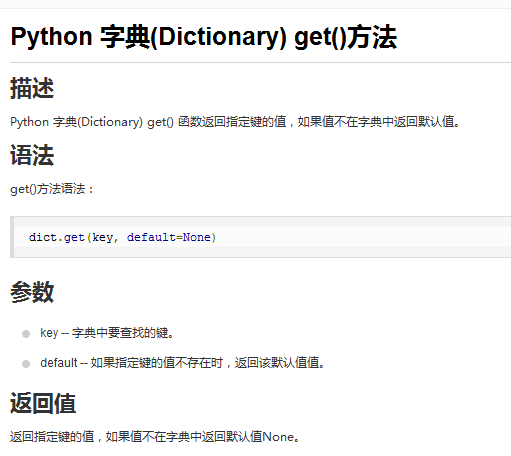
第二,得到之后要对dict里根据值来进行排序。
字典排序
方式有两种,第一种是用operation类,第二种是不用import,直接做,但是这种方式是根据tuple来进行排序的
sorted(word2count_dict.iteritems(),key=lambda d:d[1],reverse=True)
.iteritems()得到一个(key,value)的tuple,key=d[0]说明是key,d[1]说明是value。默认从小到大,因此用reverse
写完了mapper和reducer,接下来开始写主要的那个.sh文件。
.sh 顾名思义是shell文件。
最后reducer里得到的是这样的文件值:

之后,写完mapper和reducer,需要写sh文件。
在sh文件中,需要设置basedir,input_dir, output_dir















 284
284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









