






因为任务的分配是以Task为粒度执行的,每一个Task同时只会执行在一个Executor上,是用一个vCore资源,因此如果要充分利用上CPU,就需要干预Task数量。
以如下SQL为例:
select
l_orderkey,
sum(l_extendedprice * (1 - l_discount)) as revenue,
o_orderdate,
o_shippriority
from
customer, orders, lineitem
where
c_mktsegment = 'BUILDING'
and c_custkey = o_custkey
and l_orderkey = o_orderkey
and o_orderdate < date '1995-03-15'
and l_shipdate > date '1995-03-15'
and o_orderdate > date '1994-11-13'
and l_commitdate < date '1995-06-14'
group by
l_orderkey,
o_orderdate,
o_shippriority
order by
revenue desc,
o_orderdate
limit 10;DAG图
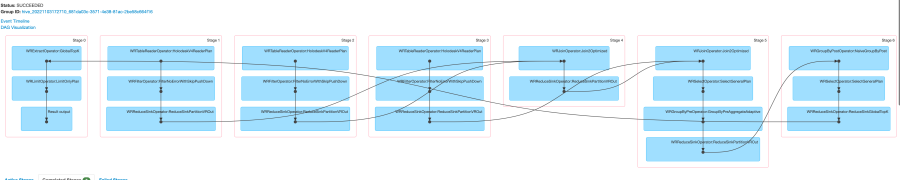
stage的task情况
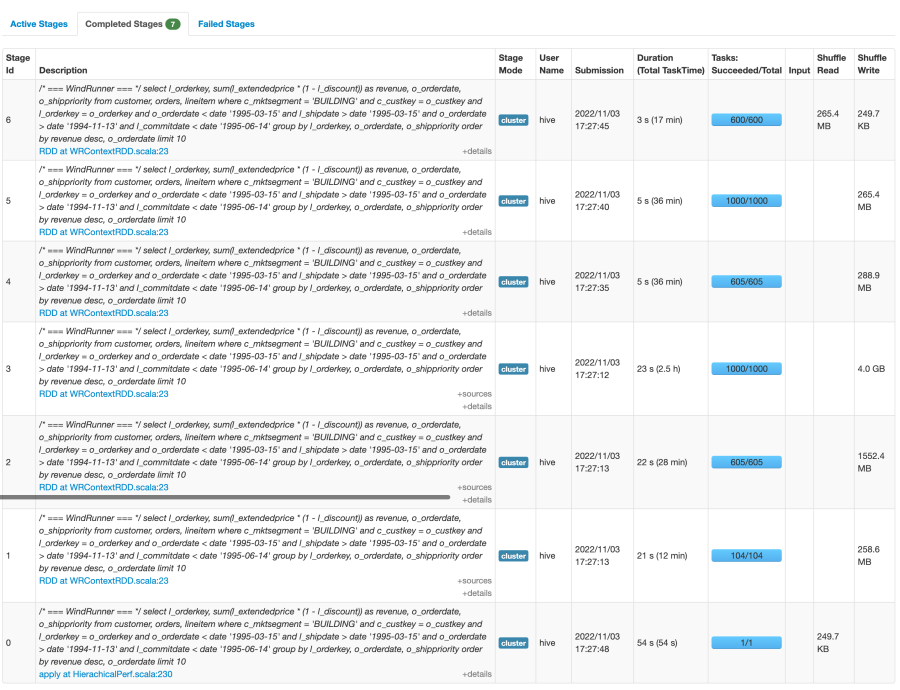
任务一共分成7个stage(此处以星环WR计算引擎情况为例)
stage1: table read (customer) [104 tasks]
stage2: table read (orders) [605 tasks]
stage3: table read (lineitem) [1000 tasks]
stage4: 1&2 join → tmp1 [605 tasks]
stage5: tmp1 & 3 join → tmp2 [1000 task]
stage6: tmp2 group by order by [600 task]
stage0: limit & sink result [1 task]
大家有没有考虑过是什么影响了task数量呢
读表:
Holodesk表,读表的task数量,仅和经过元数据过滤后要读取的block数量有关。如分区过滤,分桶过滤,数据文件minmax Filter过滤等,会在读表时进行裁剪。
但是task数本身和分桶数量并没有直接的关系


1. Join & group by:
因为是以Shuffle来切分Stage的,因此只有两个算子之间需要进行数据的重分布(使用Hash Shuffle)时,会需要重新计算下一个Stage的task数,而计算的方式为:
group by 的task为:上一个stage task数 * hive.groupby.aggregateratio(default:0.6)
join 的task为:一般是task更多的stage task数 * hive.join.aggregateratio(default:1.0)
因此可以看到,示例的任务中,stage4的task数位605,stage5的task数是1000,而stage6的task数就是600了
2. limit:
limit时会进行预估,裁剪掉不必要的task。示例中就是裁剪后只剩1个task
默认会先2个Task执行(参数 ngmr.num.parts.try.limit 决定,limit不够再起新的task),因此不要进行大数据量的limit,性能非常差
3. insert:
那么如果我们不是select任务,而是向目标表中插入数据呢?
数据插入时,Stage的task数取决于是否向分桶表插入数据。因为分桶的逻辑是根据数据的Hash值进行数据的分布计算,将数据写到不同的Tablet中,因此入库时的task数量一般是:
- 分桶表:无论是否分区,入库的task数均为分桶数
- 非分桶表:入库的task数位上一个stage的task数
4. 全局参数控制:
读表stage的task数参数:
通过开启AutoMerge,让一个Task读取多个Small Block,来实现减少Task数的效果
holodesk.automerge.enabled开启AutoMerge
holodesk.automerge.mergesize设置AutoMerge的数据合并大小阈值
holodesk.automerge.filesize设置AutoMerge的数据合并数量阈值
其他stage的task数参数:
手动设置以下参数,会影响读表stage以外的stage的task数,可以增大或减少task数
mapred.reduce.tasks 设置reduce 个数
mapred.minreduce.tasks 设置最小reduce个数















 111
111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









