









Python爬取影评并进行情感分析和数据可视化
文章目录
一、引言
前几天出了《航海王:红发歌姬》等电影,我就立马看了,正好做一个爬取影评,想看看影评的好坏。这就离不开python爬虫和自然语言处理技术了。
这是一个小案例:包含python爬虫、数据预处理、自然语言处理、数据可视化等内容。下面我将详细这个小案例。
二、使用requests+BeautifulSoup进行影评的爬取
1、分析界面元素
我这里使用简单的bs4进行爬取。
找到影评所在的标签位置
<div>的类名为 comment 标签为 <span>类名为 short。
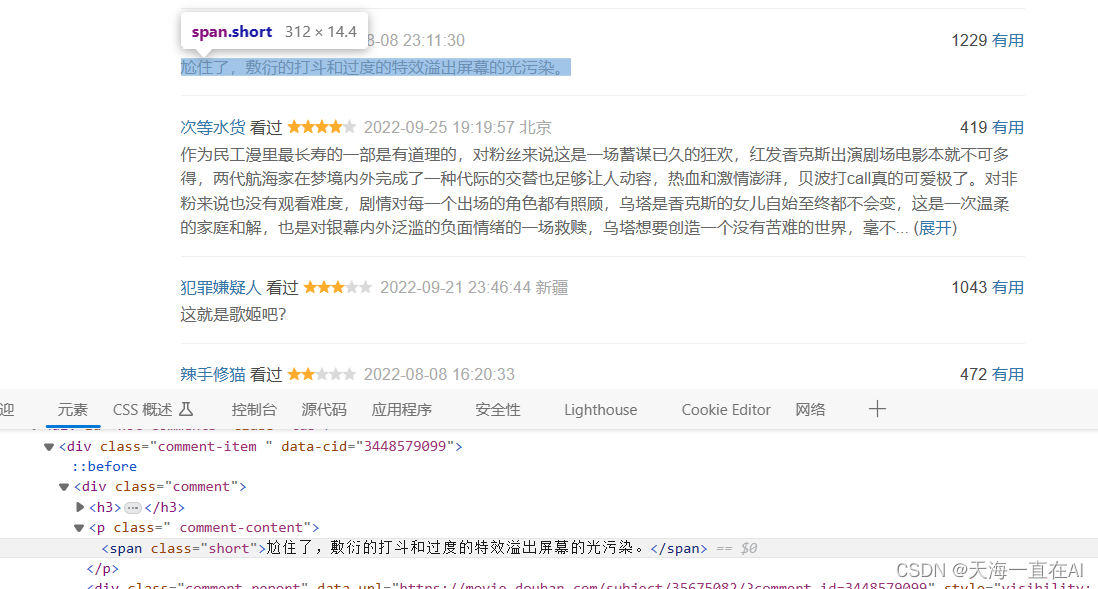
2、编写代码
代码如下,在User-Agent中设置自己的请求头信息,并将某个电影url填入。
请求头信息获取:点击网络,再刷新一下页面,点击名称为comments?status=P,点击标头,在请求标头的最下方就能看到user-agent了。
获取影评评论内容的函数
def get_comment_content(comment):
span = comment.find('span', class_='short')
return span.get_text()
定义将评论内容保存到csv文件中
def save_to_csv(comments):
with open('comments.csv', 'a', newline='', encoding='utf-8-sig') as csvfile:
writer = csv.writer(csvfile)
for comment in comments:
content = get_comment_content(comment)
writer.writerow([content])
主方法中调用上述函数并实现爬取与写入
url = '影评url地址'
#你的请求头信息
headers = {
'User-Agent': 'Mozilla/5.0xxxxxxxxxxxxxxxxxxxx'}
while url:
print('正在爬取:', url)
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
comments = soup.find_all('div', class_='comment-item')
save_to_csv(comments)
time.sleep(1)
实现页面自动跳转的功能,这里加入了try来观察爬取不到的情况,并在结束时将url置空防止进入死循环。
try:
pagination = soup.find('div', class_='center').find('a', class_='next')
print(pagination)
if pagination:
next_page = pagination['href']
url = '影评url地址' + next_page
print('跳转到下一页:', url)
print('找到标签跳转')
else:
url = None
print('无跳转')
except:
url = None
print('没有找到,结束')
print('爬取完成!')
完整代码:
import requests
from bs4 import BeautifulSoup
import csv
import time
def get_comment_content(comment):
span = comment.find('span', class_='short')
return span.get_text()
def save_to_csv(comments):
with open('comments.csv', 'a', newline='', encoding='utf-8-sig') as csvfile:
writer = csv.writer(csvfile)
for comment in comments:
content = get_comment_content(comment)
writer.writerow([content])
url = '影评url地址'
headers = {
'User-Agent': 'Mozilla/5.0xxxxxxxxxxxxxxxxxxxx'}
while url:
print('正在爬取:', url)
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
comments = soup.find_all('div', class_='comment-item')
save_to_csv(comments)
time.sleep(1)
try:
#页面跳转的点击在div的id为paginator ,class为center中的a标签class为next
pagination = soup.find('div', class_='center').find('a', class_='next')
print(pagination)
if pagination:
next_page = pagination['href']
url = '影评url地址' + next_page
print('跳转到下一页:', url)
print('找到标签跳转')
else:
url = None
print('无跳转')
except:
url = None
print('没有找到,结束')
print('爬取完成!')
最后将爬取到的评论信息进行保存。
| 尬住了,敷衍的打斗和过度的特效溢出屏幕的光污染。 |
|---|
| 这就是歌姬吧? |
| 作为民工漫里最长寿的一部是有道理的,对粉丝来说这是一场蓄谋已久的狂欢,红发香克斯出演剧场电影本就不可多得,两代航海家在梦境内外完成了一种代际的交替也足够让人动容,热血和激情澎湃,贝波打call真的可爱极了。对非粉来说也没有观看难度,剧情对每一个出场的角色都有照顾,乌塔是香克斯的女儿自始至终都不会变,这是一次温柔的家庭和解,也是对银幕内外泛滥的负面情绪的一场救赎,乌塔想要创造一个没有苦难的世界,毫不意外最终是梦境一场,但一次完整的、有起有兴的ADO演唱会也能让人心头一软。 |
| 尾田这两年没少看女团吧 |
| 日本宅男文化還有救嗎 ファザコン蘿莉被ナルシスト裝帥大叔精神打擊變病嬌女idol 开场就说拯救世界的歌聲這個standard高的 結果一開嗓就想逃出影院 视觉听觉大脑受损本人 可以给你拔高一下说是讲娱乐至死 楚门的世界 然后 没了 这俩词就可以end of story 想煽情煽泪的地方皱眉+汗毛直竖save it plz!!! |
| ado个人演唱会 |
| 买red电影票送uta演唱会门票 |
| 缤纷的色彩,华丽的音符,仿佛在电影院听了一场Live演唱会,让人梦回大和歌姬时代,可如此美妙的歌声真的是无罪的吗?当音乐的魔法消失,有罪的歌姬和无辜的小女孩不过是阴谋的一体两面。你是愿意沉迷在甜美的歌声中死去,还是宁愿辛苦努力踏实过每一天?魔法音乐的这个哲思,要怎么回答才能安全地活下去 |
| 这是开了一场个人演唱会啊,我觉得这个很适合小朋友看,大人的话闭上眼睛听听音乐还是可以的,剧情几乎是为零。 |
| 好漫长又随意的一部剧场版,槽点真的有比隔壁柯南少吗……加各种强行的设定也一定要促成全员乱打的局面就真的跟柯南一定要爆炸很像了。当成精良的周年纪念音乐会来看,给一个三星吧。 对池田秀一的声音都要有阴影了,又是这种被过度神话的装逼人物。另外,中文字幕强行翻译成航海王就很真的很能让人意识到,到底为什么这些不偷不杀不作恶的人要自称“海贼”。每次看乌塔和路飞就“为什么要当海贼”鸡同鸭讲地吵起来时,都很想打断他们,“其实他只是想当巡游世界的夺宝奇兵啦”。 |
由于一些原因,我们只能爬取220条评论。这里我尝试过在220条之前更换请求头继续爬取,结果还是到220就停了。通过打印第220条下面的网页,也发现网址和网站内元素没有改动。
同样的,将电影更换也是这种情况,但也验证了将url更换为其他电影,我们的代码依旧能正常爬取。
电影《保你平安》影评
| 看这个电影最大的疑问,如果韩露真的是坐台女,她死后就可以被挖坟墓吗? |
|---|
| 关于韩露如果真的是坐台小姐应不应该被挖出来这件事,开篇魏平安和墓地经理吵架已经给了创作者的表态。魏平安质问祁经理:坐台小姐怎么了,埋咱这的人不让有道德瑕疵?别老模糊重点了吧?真不知道是看不懂还是看不见。 |
| 之前在muji打工,遇到一个爸爸,一口气买了47支笔,开了发票,问我能不能在发票后面给他写这些笔购买于哪里。他说,他女儿班上同学丢了一支笔,号称家里人从日本买的,国内买不到,刚好他女儿之前在muji买了支一样的,班上同学都说是她偷的,爸爸想给女儿挣个公道!抹黑一个人很简单,一张模糊的图、一条朋友圈、一句话就够了,但是要证明一个人,真的太难了!善良的人,祝你平安! |
| 立意很好,但只是浅浅摸到了边缘。一个女人要足够清白足够高尚才会被允许葬在男友旁边,本身这件事就很荒谬,通篇主角也只是为了帮她澄清谣言而奔走,从未想过女性是否可以挣脱这层枷锁。 |
| 腿上的胎记是女孩的软肋,乌有的传言是掘墓的铁铲。裤脚向下一寸遮不住审美的霸凌,棺椁移走一格破不掉信息的茧房。这时代多得是为流量胡说的嘴,因谣言蒙蔽的眼,却鲜有不凉的血和求真的心。冰可乐不凉热血,总抱怨直播间没人送出烟花。前方拦路的白马为不舍的爱牵线,江面盛放的烟花祝侠义的人平安。 |
三、情感分析
1、数据预处理
我们需要将我们所爬取的文件加一个简单的表头,方便我们接下来的操作
由于我们的文件只有一列数据,所以直接手动添加即可(使用记事本或者Excel)。
若需要批量添加表头,下面是代码.
with open('保你平安.csv', 'r',encoding='utf-8-sig') as f:
reader = csv.reader(f)
data = list(reader)
# 修改第一列
data[0][0] = 'comment'
data[1][0] = 'xxxx'
# 将其他数据向下移一个位置
for i in range(len(data)-1, 0, -1):
data[i], data[i-1][1:] = [data[i-1][0]] + data[i][1:], data[i][1:]
# 写回文件
with open('保你平安.csv', 'w', newline='') as f:
writer = csv.writer(f)
writer.writerows(data)
我们选择保你平安做情感分析,因为航海王的评论中有很多是日语的,不方便进行分析。
2、情感分析
添加表头之后,我们使用 jieba对句子进行分词处理,并调用停用词来去除一些干扰词
import pandas as pd
import jieba
from textblob import TextBlob
import matplotlib.pyplot as plt
# 设置文件名
input_file = "保你平安.csv"
stopwords_file = "stopwords.txt"
output_file = "保你平安processed.csv"
# 读取停用词
with open(stopwords_file, 'r', encoding='utf-8') as f:
stopwords = [line.strip() for line in f.readlines()]
# 定义分词函数
def cut(text):
words = jieba.cut(text)
return " ".join([word for word in words if word not in stopwords])
# 读取数据文件
data = pd.read_csv(input_file)
# 分词并写入新列
data['process'] = data['comment'].apply(lambda x: cut(str(x)))
并将处理好的句子写入第二列,表头为process。
使用textblob进行简单的情感分析,将情感分为正向和负向(好评与差评),分析出的结果中华,好评用1表示,差评用-1表示,将分析结果写入第三列sentiment中。
# 情感分析并写入新列
data['sentiment'] = data['process'].apply(lambda x: TextBlob(str(x)).sentiment.polarity)
# 写入新文件
data.to_csv(output_file, index=False)
3、数据可视化
最后我们将结果进行可视化,通过绘制饼图,来观察好评和差评所占的比例。
sentiment_counts = data['sentiment'].value_counts()
labels = ['Positive', 'Negative']
colors = ['#66c2a5', '#fc8d62']
explode = (.1, )
fig, ax = plt.subplots()
wedges, texts, autotexts = ax.pie(sentiment_counts, colors=colors, autopct='%1.1f%%', startangle=90, pctdistance=1.1,textprops=dict(color="b"))
ax.legend(wedges, labels, loc="center left", bbox_to_anchor=(1, 0, 0.5, 1))
ax.axis('equal')
plt.title("Sentiment Distribution")
plt.setp(autotexts, size=10, weight="bold")
plt.show()
如图发现这220条评论中,好评占比接近98%
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fg76ZR3q-1686367774469)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230610095322989.png)]](https://i-blog.csdnimg.cn/blog_migrate/96e2b3cb7eeef5c687e8039489bf23f3.png)
完整代码:
import pandas as pd
import jieba
from textblob import TextBlob
import matplotlib.pyplot as plt
# 设置文件名
input_file = "保你平安.csv"
stopwords_file = "stopwords.txt"
output_file = "保你平安processed.csv"
# 读取停用词
with open(stopwords_file, 'r', encoding='utf-8') as f:
stopwords = [line.strip() for line in f.readlines()]
# 定义分词函数
def cut(text):
words = jieba.cut(text)
return " ".join([word for word in words if word not in stopwords])
# 读取数据文件
data = pd.read_csv(input_file)
# 分词并写入新列
data['process'] = data['comment'].apply(lambda x: cut(str(x)))
# 情感分析并写入新列
data['sentiment'] = data['process'].apply(lambda x: TextBlob(str(x)).sentiment.polarity)
# 写入新文件
data.to_csv(output_file, index=False)
sentiment_counts = data['sentiment'].value_counts()
labels = ['Positive', 'Negative']
colors = ['#66c2a5', '#fc8d62']
explode = (.1, )
fig, ax = plt.subplots()
wedges, texts, autotexts = ax.pie(sentiment_counts, colors=colors, autopct='%1.1f%%', startangle=90, pctdistance=1.1,textprops=dict(color="b"))
ax.legend(wedges, labels, loc="center left", bbox_to_anchor=(1, 0, 0.5, 1))
ax.axis('equal')
plt.title("Sentiment Distribution")
plt.setp(autotexts, size=10, weight="bold")
plt.show()




















 774
774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











