






1.目录
2.写在前面的话
填坑不容易,入坑需谨慎!!!
流量数据数据是任何一家有志上市的科技公司不可能放弃的一个重点,但是对于好多公司而言,一本好好的经书,偏偏得歪着念,埋下一堆堪比定时炸弹的坑,后来入坑者后知后觉,从奔溃再到一点点的把坑填上,这就是一个程序员的自我修养吧! 怀着治病救人,普度众猿的慈悲之心,我把我的心酸泪贴出来,方便后来者,愿大家都活得更健康和谐.
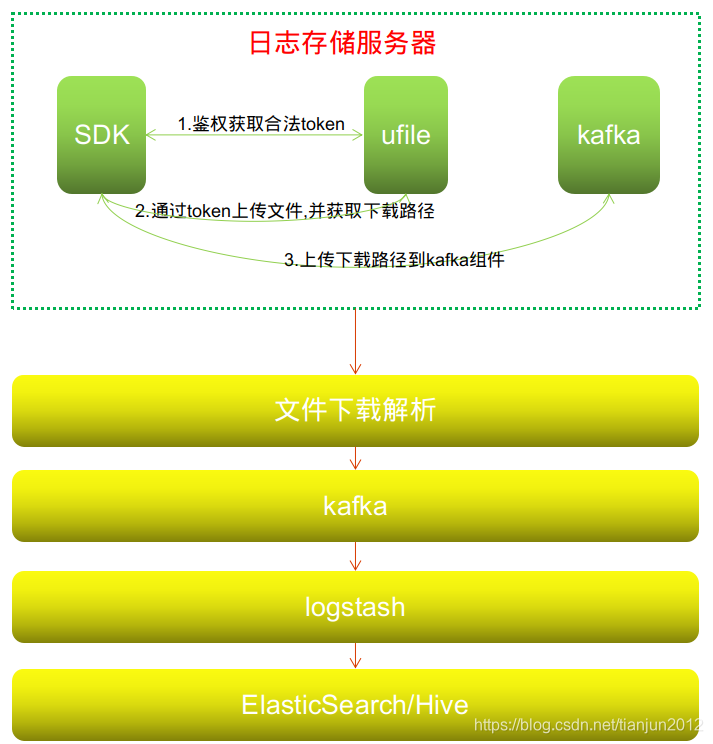

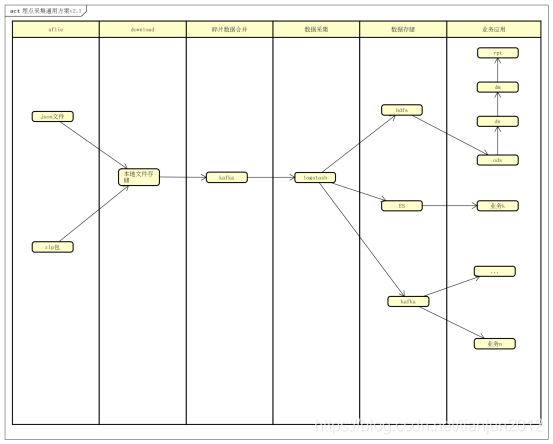
可以看到v2.0与v2.1的架构的差距就在中间碎片文件的合并,无论是logstash,fliebeat,flume或者其他采集工具,对于实时日采集百万级别的碎片文件,几乎没有一个组件能达到这个要求,这个坑涉及整个采集系统的稳定性和可伸缩性.
3.功能简介
3.1模块简介
3.1.1 ufile模块
用于移动端(如sdk等)上传压缩日志文件(如.zip).可以简单理解为云存储介质.
3.1.2 down模块,文件合并模块
本模块消费kafka中url数据,并通过http/https方式从ufile中把埋点文件下载到本地,如果存在.zip文件,需要进行解压,同时把文件内容逐条写入kafka.
3.1.3 数据采集模块
本模块针对本地文件进行实时监控采集,采集组件选用的是logstash(logstashfilter插件比较丰富,能直接解析复杂json格式并上传到hdfs),同时,logstash支持数据下沉到多个下游存储组件,比如kafka,同一份数据还可以进行下一步实时分析
3.1.4 数据存储模块
通过logstash的webhdfs插件上传到hdfs上(支持压缩等),在hdfs通过建表指定路径映射,后续可以通过hive/impala等进行etl操作,对外提供数据服务能力.
通过logstash的kafka等插件等,可以同步把采集到的数据送入流式处理的源头,开始流式处理的过程.
3.1.5 业务应用模块
依托大数据平台组件对外提供离线报表/ad-hoc/大屏等的能力
4.采集模块功能实现
4.1文件下载,解析,写入kafka
此处手动提交offset,十分重要,(自动提交,如果中间步骤过多或者复杂,就有可能报各种错,此时手动提交offset十分必要),依赖包为 kafka-python
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# 作者: tianjun
# 时间: 19-5-28 下午5:24
# 文件: trace_new_kafka.py
# IDE: PyCharm
from kafka import KafkaConsumer, TopicPartition, OffsetAndMetadata, KafkaProducer
import logging as logger
import time
import threading
import uuid
import os
import requests
import json
import zipfile
import shutil
import sys
from requests.adapters import HTTPAdapter
logger.basicConfig(level=logger.INFO,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s')
topic = "trackfileupload"
# topic = "tian02"
# border_server = "197.255.20.213:9092,197.255.20.214:9092,197.255.20.215:9092"
border_server = "localhost:9092"
prefix = "/data/trace/"
# prefix = "/home/tianjun/trace/"
if len(sys.argv) > 2:
border_server = str(sys.argv[1])
topic = str(sys.argv[2])
logger.info(topic + " " + border_server)
# dev
# producer_server = "localhost:9092"
# producer_topic = "trace_producer_01"
# pre-pro
producer_server = "master2:9092,namenode1:9092,namendoe2:9092"
producer_topic = "trace_producer_01"
consumer = KafkaConsumer(topic,
bootstrap_servers=border_server,
group_id="yjp-test-trace-5",
# client_id="dolphin-pipline-google-bookinfo-consumer-foolman",
# Manage kafka offsets manual
enable_auto_commit=False,
consumer_timeout_ms=50000,
# consume from beginning
# auto_offset_reset="earliest",
max_poll_interval_ms=350000,
session_timeout_ms=60000,
)
producer = KafkaProducer(
bootstrap_servers=producer_server
)
def sub_process_handle(value, offset):
threadnum = len(threading.enumerate())
# logger.info("thread number: %s", threadnum)
if threadnum < 100:
t = threading.Thread(target=background_process, name="offset-" + str(offset), args=(value,), kwargs={})
t.start()
else:
# If all threading running
# Using main thread to handle
# Slow down kafka consume speed
logger.info("Reach max handle thread,sleep 2s to wait thread release...")
time.sleep(2)
sub_process_handle(value, offset)
# 单线程
# background_process(value, offset, tp)
# def parse2file(json_path, jsonarry):
# '''
# jsonarr一行一行的追加到文本
# :param json_path: json要保存的路径
# :return:
# '''
# hour = time.strftime('%Y%m%d%H', time.localtime())
# if not os.path.exists(prefix + "json/" + hour):
# os.makedirs(prefix + "json/" + hour)
# with open(json_path, "w", encoding="utf-8") as f1:
# for js in jsonarry:
# f1.writelines(json.dumps(js))
# f1.writelines(str("\n"))
def download(msg):
# hour = time.strftime('%Y%m%d%H', time.localtime())
url = str(json.loads(msg)['filename']).replace("filename:", "")
path = prefix + "zip/" + str(uuid.uuid1()) + ".zip" if url.__contains__(
".zip") else prefix + "log/" + str(
uuid.uuid1()) + ".json"
if not os.path.exists(os.path.split(path)[0]):
os.makedirs(os.path.split(path)[0])
s = requests.session()
s.mount('http://', HTTPAdapter(max_retries=10))
s.mount('https://', HTTPAdapter(max_retries=10))
r = s.get(url, timeout=10)
logger.info(url)
with open(path, "wb") as code:
code.write(r.content)
r.close()
s.close()
if url.__contains__(".zip"):
f = zipfile.ZipFile(path)
# tmp = str(uuid.uuid1()) + 'tmp/'
for file in f.namelist():
# f.extract(file, prefix + "zip/" + tmp)
# if not os.path.exists(prefix + "json"):
# os.makedirs(prefix + "json")
ajson = f.read(file).decode('utf-8')
load_jsons = json.loads(ajson)
for js in load_jsons:
producer.send(producer_topic, json.dumps(js).encode('utf-8'))
producer.flush()
f.close()
os.remove(path)
elif url.__contains__(".json"):
with open(path, 'r') as load_f:
load_jsons = json.load(load_f)
for js in load_jsons:
producer.send(producer_topic, json.dumps(js).encode('utf-8'))
producer.flush()
os.remove(path)
else:
logger.error("this is not zip/json file!")
def background_process(value):
download(value)
# offsets = {tp: (OffsetAndMetadata(offset, None))}
# consumer.commit_async(offsets=offsets)
def consume_tian():
max_records = 500
while True:
# try:
msg_pack = consumer.poll(timeout_ms=5000, max_records=max_records)
for messages in msg_pack.items():
tp = None
for message in messages:
var_type = type(message)
if isinstance(message, TopicPartition):
tp = message
# last_offset = end_offset if consumer.committed(message) is None else consumer.committed(message)
if var_type == list:
# 重置此消费者消费的起始位
# consumer.seek(tp, last_offset)
# min_value = len(message) if len(message) < max_records else max_records
# logger.info(
# "last_offset,end_offset,topicpartitionlen(message),max_records,min_value: %s,%s,%s,%s,%s,%s",
# last_offset, end_offset, tp, len(message), max_records, min_value)
# logger.info("offsets: %s", offsets)
end_offset = consumer.end_offsets([tp])[tp]
logger.info("end_offset,tp: %s,%s", end_offset, tp)
# logger.info("consumer.committed(message): %s", consumer.committed(message))
for consumer_record in message:
tp = TopicPartition(topic=consumer_record.topic, partition=consumer_record.partition)
logger.info("record offset, tp: %s,%s", consumer_record.offset, tp)
sub_process_handle(str(consumer_record.value, encoding="utf8"), consumer_record.offset)
# 同步提交保证offset的一致性
offsets = {tp: (OffsetAndMetadata(end_offset, None))}
consumer.commit(offsets=offsets)
# consumer.commit_async(offsets=offsets)
# consumer.commit_async()
logger.info("Offset committed succeed!")
# except Exception as e:
# logger.error(e)
if __name__ == '__main__':
consume_tian()
本脚本程序,整体业务流程就是通过消费kafka中数据把.json问.zip文件下载到本地,并解压/解析,同时按照json object逐行写入kafka.
4.2 数据采集
logstash配置:
input {
# file {
# file_completed_action => "delete"
# path => "/home/tianjun/trace/log/*.json"
# mode => "read"
# #不处理120天以前的数据,默认为一天
# ignore_older => "10368000"
# codec => "json"
# }
#beats {
# port => 5044
# codec => "json"
#}
kafka {
id => "kafka_logstash_trace_01"
bootstrap_servers => ["master2:9092","namenode1:9092","namenode2:9092"]
topics => ["trace_producer_01"]
auto_offset_reset => "latest"
codec => "json"
}
}
filter {
ruby {
path => "/open/python/tracelog/logstash/test.rb"
}
json {
source => "business"
remove_field => ["@version","path","host","tags","header","body","business"]
}
}
output {
# stdout {}
webhdfs {
host => "master1" # (required)
port => 14000 # (optional, default: 50070)
path => "/user/hive/warehouse/yjp_trace.db/yjp_ods_trace/day=%{op_day}/logstash-%{op_hour}.log" # (required)
user => "hdfs" # (required)
# compression => "snappy"
# snappy_format => "stream"
codec => line {
format => "%{message}"
}
}
elasticsearch {
hosts => ["datanode1:9200","datanode2:9200","datanode3:9200"]
index => "trace_%{op_day}"
#template => "/data1/cloud/logstash-5.5.1/filebeat-template.json"
#template_name => "my_index"
#template_overwrite => true
}
}














 3438
3438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









