








 超级会员免费看
超级会员免费看

导入会用到的库
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
查看数据集构成、标签名称、特征名称
详细情况如下:
- 特征数一共有四个:‘sepal length (cm)’、 ‘sepal width (cm)’、‘petal length (cm)’、‘petal width (cm)’;(分别对应萼片长宽以及花瓣长宽)
- 标签名称即类别数一共三类即花的种类(非二分类问题,决策树的可解释性可能更强):‘setosa’, ‘versicolor’, ‘virginica’
所以对于这样一个简单的三分类问题,我打算直接采用2.5:7.5的划分并用贝叶斯跟决策树分别训练对比分类效果,详细步骤如下:
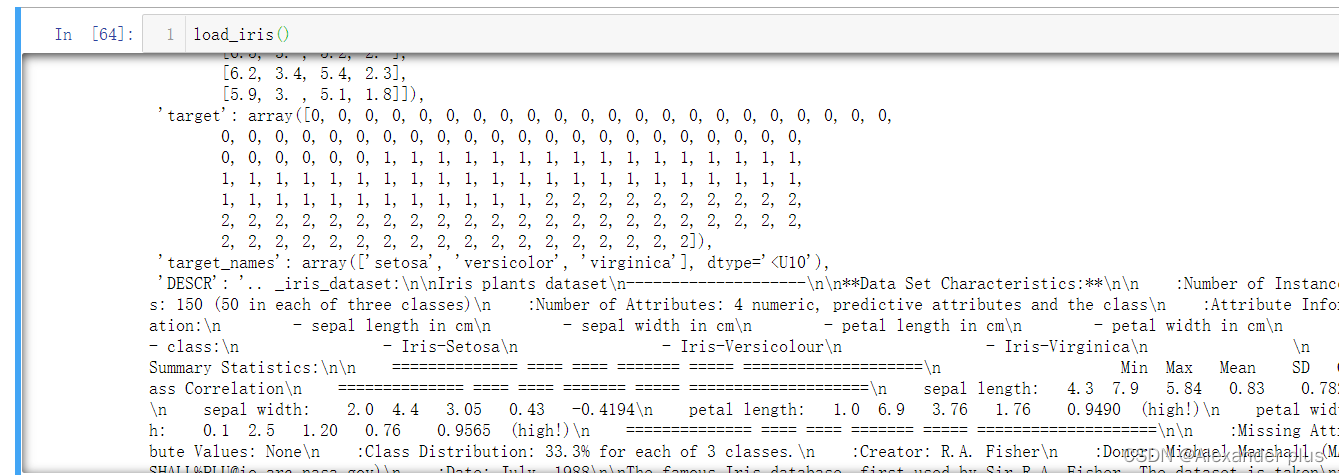
- 获取数据集
data = pd.DataFrame(load_iris().data)
data
- 获取类别标签
labels = load_iris().target
labels

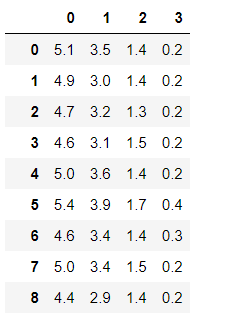
- 可视化显示各条数据集萼片、花瓣长宽之间的变化情况(我觉得并没有什么卵用)
data.hist()
plt.show()
- 获取类别名称:
feature_names = load_iris().feature_names
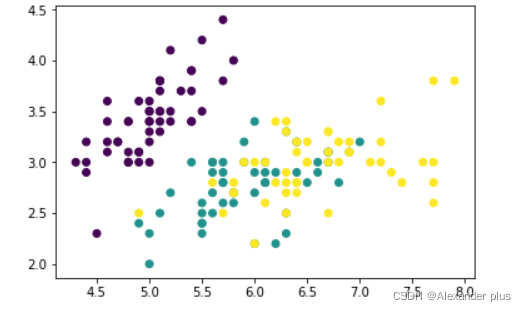
- 萼片长度跟宽度的图形化显示
plt.scatter(x = data[0],y = data[1],c = labels)
plt.show()
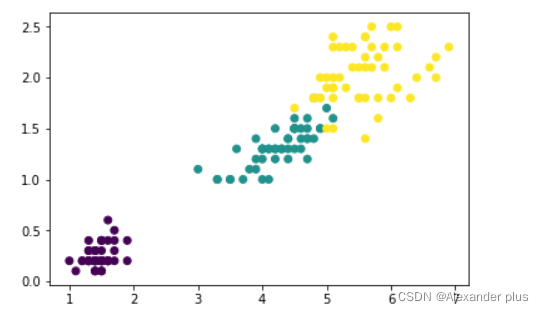
- 花瓣的长度跟宽度的图形化显示
plt.scatter(x = data[2],y = data[3],c = labels)
plt.show()
进行分类器构建、训练以及预测评估
from sklearn.naive_bayes import MultinomialNB,BernoulliNB,GaussianNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
- 划分训练集与测试集
x_train,x_test,y_train,y_test = train_test_split(data,labels,test_size=0.25)
x_train,x_test,y_train,y_test
- 贝叶斯分类器
model_1 = GaussianNB()
model_1.fit(x_train,y_train)
- 决策树分类器
model_2 = DecisionTreeClassifier()
model_2.fit(x_train,y_train)
- 两分类器分别做预测:
y_predict_1 = model_1.predict(x_test)
y_predict_1
array([0, 2, 0, 2, 2, 2, 0, 0, 1, 0, 2, 2, 0, 1, 1, 0, 2, 1, 0, 1, 1, 2,
0, 0, 0, 0, 1, 2, 1, 2, 0, 2, 1, 0, 1, 1, 2, 2])
y_predict_2 = model_2.predict(x_test)
y_predict_2
array([0, 2, 0, 2, 2, 2, 0, 0, 1, 0, 2, 2, 0, 1, 2, 0, 2, 1, 0, 1, 1, 2,
0, 0, 0, 0, 1, 2, 1, 2, 0, 2, 1, 0, 1, 1, 2, 2])
测试集真实值

分别显示两个分类器的分类效果指标评估:
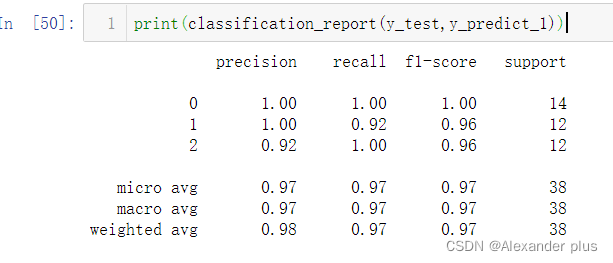
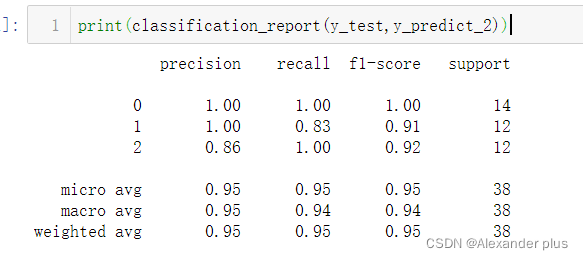
- 结论:个人认为,不论是准确率还是召回率在不同的应用场景下,均存在有失偏颇的情况,F-score作为二者的一个调和平均,可能可靠性更高;当然,此处的高斯贝叶斯完爆我给的决策树,个人认为有以下几点原因,这里的决策树用的指标应该是基尼系数,但是相对于ID3的信息增益或者是或者C4.5信息增益率而言,Cart的基尼系数更偏向于二元划分,但显然,此处的三分类问题其表现欠佳!(另外,此处准确率达到1,一方面是数据集体量小,另外一方面,可能需要考虑决策树是不是过拟合了)















 4518
4518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











