







OpenMP是多线程优化库,可以对for循环有很好的加速作用。该库在VS里面是自带的,不需要自己配置。
开发环境:
首先在项目属性里设置支持OpenMP:
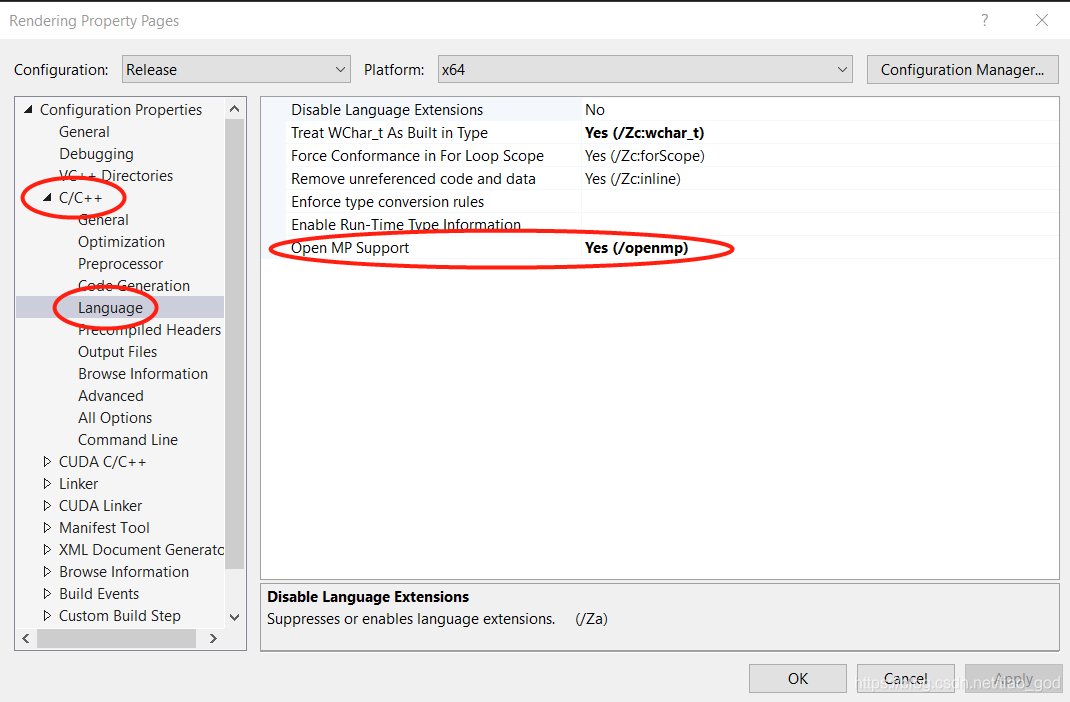
然后程序中加入头文件:
#include <omp.h>并在需要使用的地方写入:
float renderFrame() {
omp_set_num_threads(20); //设置线程的个数
double start = omp_get_wtime();//获取起始时间
#pragma omp parallel for
for (int i = 0; i < ThreadNum; i++) {
for (int j = 0; j < ThreadNum; j++) {
//写入你要执行的内容
}
}
double end = omp_get_wtime();
return end - start; //返回程序运行时间
}速度加快了好几倍!















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











