







- 题目:A Multi-Neural Network Acceleration Architecture
- 时间:2020
- 会议:ISCA
- 研究机构:首尔大学
1 introduction
实际执行时很容易出现单硬件跑多个神经网络的情况,为此需要实现:
- 硬件支持跑多个不同的神经网络
- 任务切分和调度
本篇论文的主要贡献:
- 对于不同DNN,切分出计算密集型任务(CB)和存储密集型任务(MB)
- 执行时间相近的任务并行处理,提高资源的利用率
- 最小化片上SRAM的要求
2 方法
2.1 硬件架构
硬件架构是基于TPUv2或v3,只不过是面向推理端,有16个PE array,HBM带宽达到了450GB/s,PE阵列采用了脉动阵列
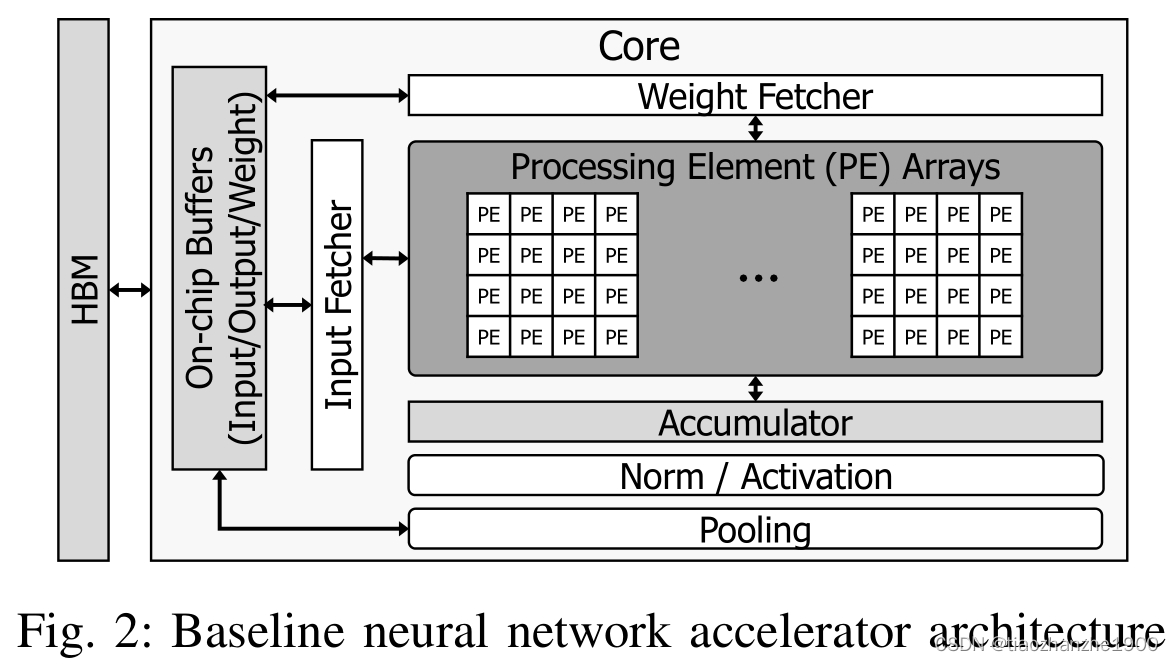
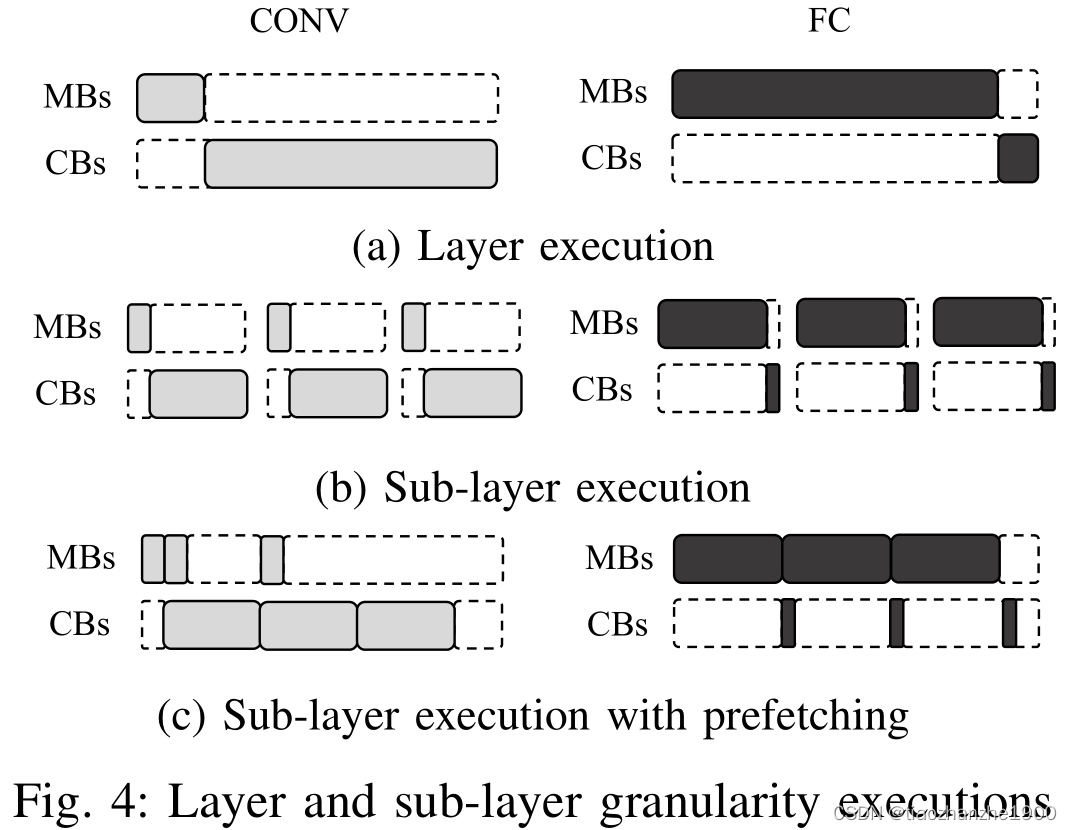
2.2 AI-MultiTasking
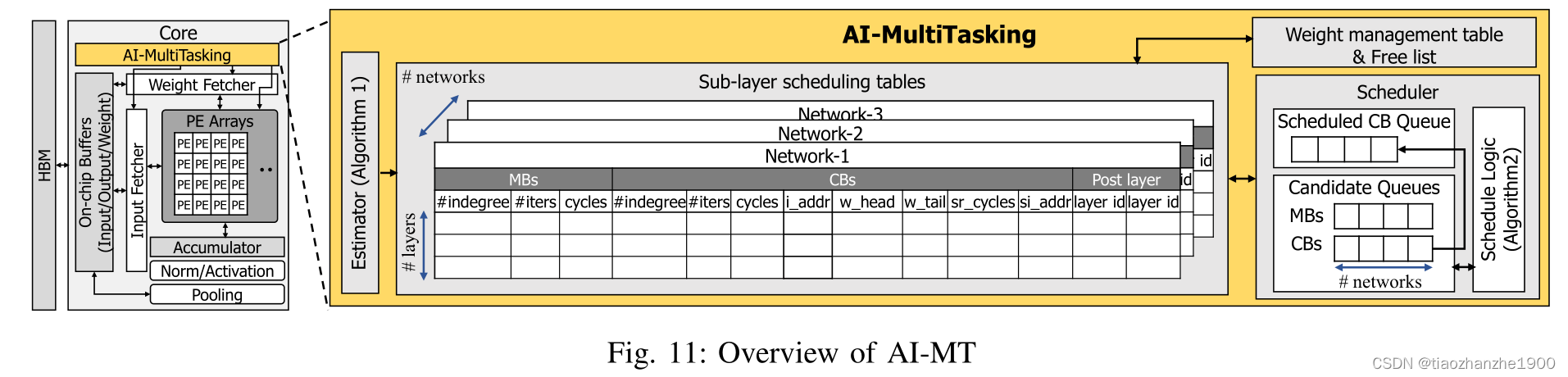
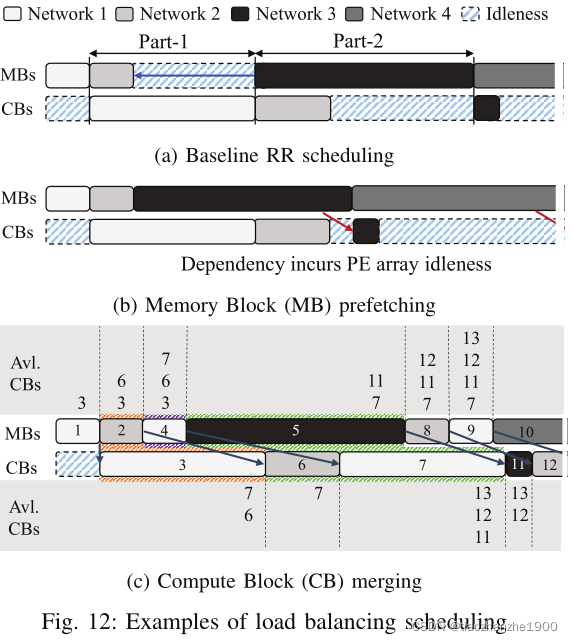
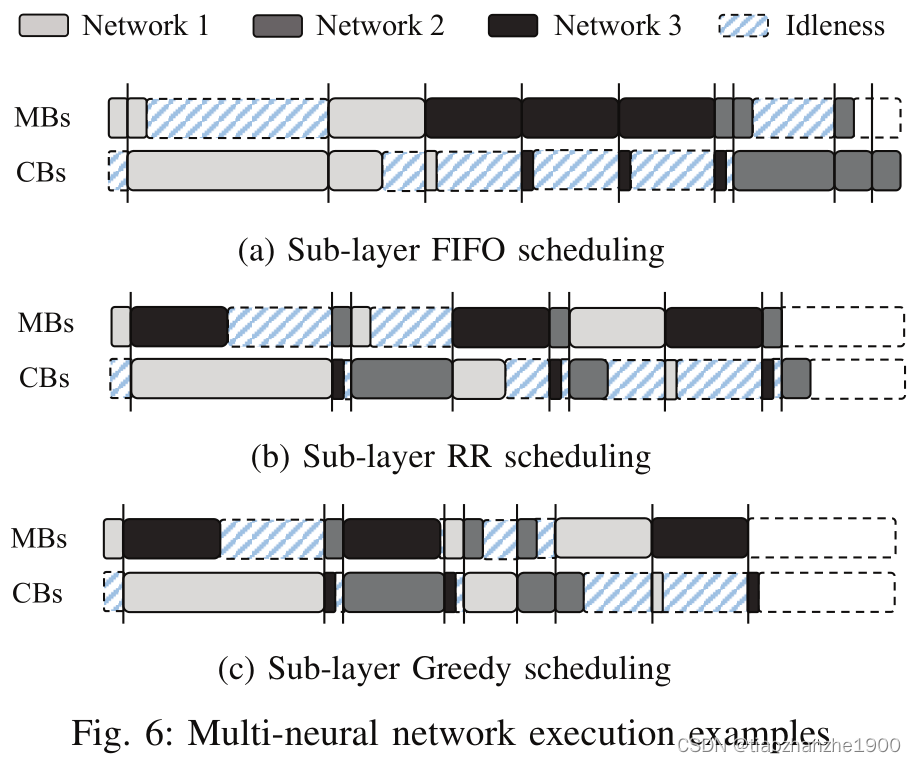
Load Balancing Scheduling主要包含两个方法
- Memory Block Prefetching,提前加载数据,实现类似乒乓的运算
- Compute Block Merging,如果MB周期大于CB周期怎么办?调整MB的顺序,如上图c的block-4和block-5,保证MB周期永远小于CB的周期,这需要一个变量AVL_CB来记录available CB所需要的周期。
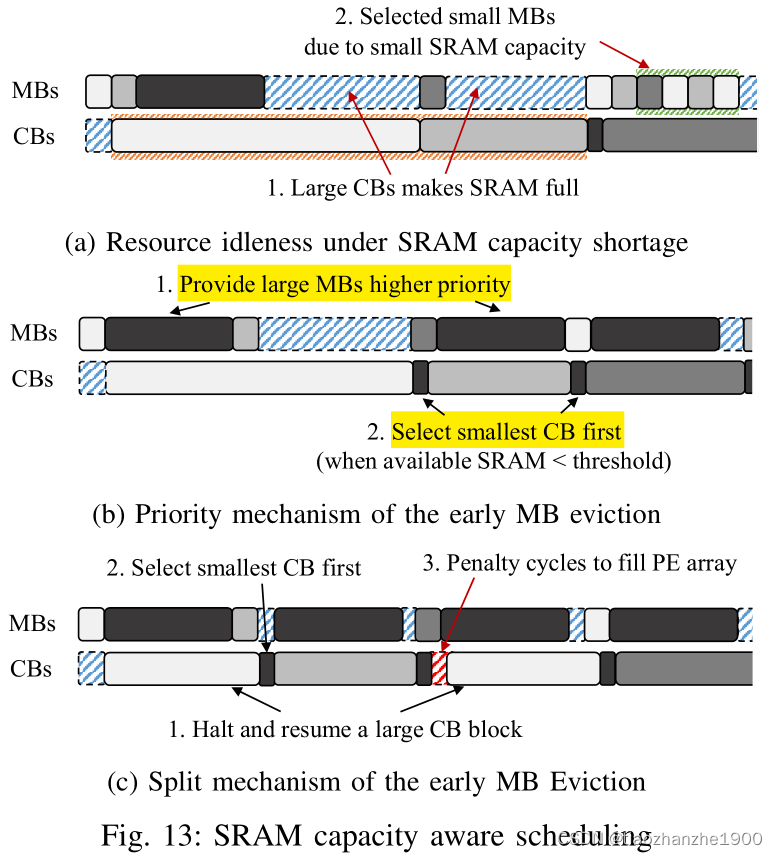
2.3 SRAM Capacity Aware Scheduling
如果SRAM容量不够,那么MB的进程会停止,直到SRAM被释放出来,如何解决?
- 选择MB周期数大于相应CB的的进程,如全连接层的MB,因为虽然进程会占用了很多SRAM的容量,但因为CB小,能比较快的释放出来,那么MB idle的周期相对就缩短了
- 同样的道理,当SRAM紧张时,选择CB周期小的进程,以此快速的释放SRAM
- 题目:Heterogeneous Dataflow Accelerators for Multi-DNN Workloads
- 时间:2021
- 会议:HPCA
- 研究机构:GIT/Nvidia
1 introduction
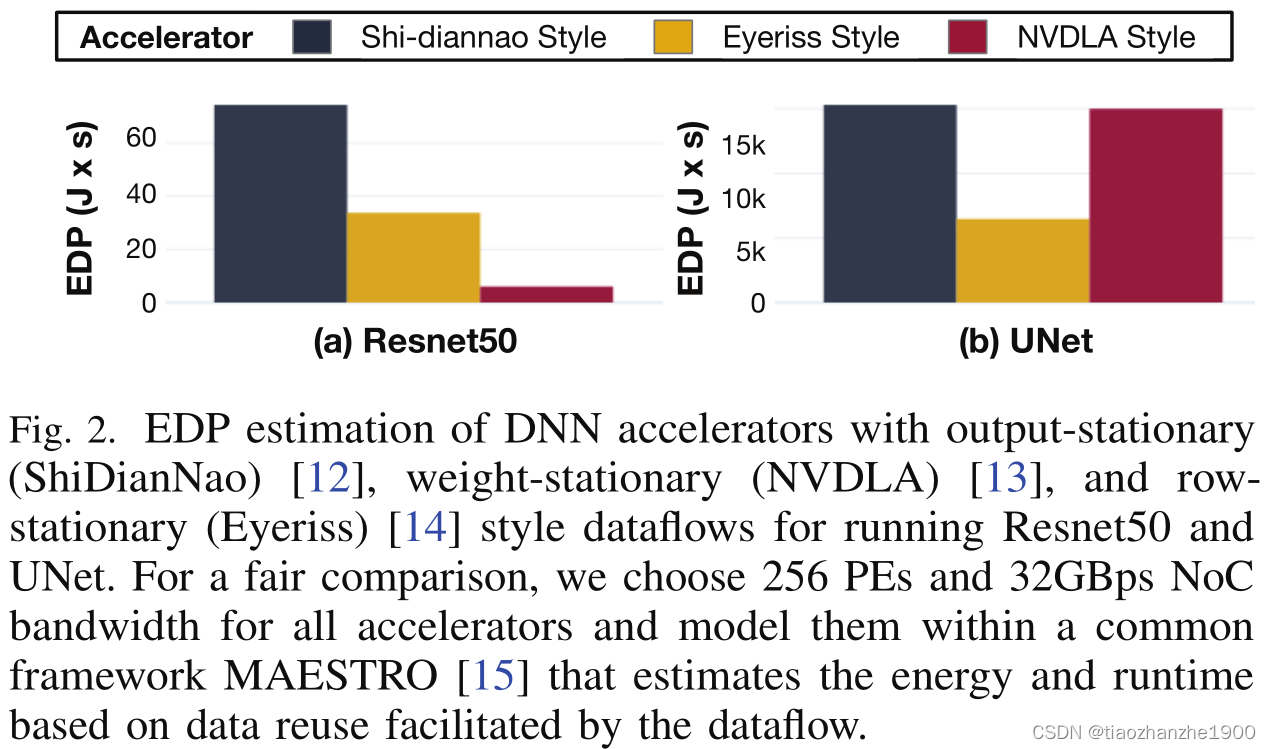
比较Shi-diannao、Eyeriss和NVDLA加速器,对于resnet和UNet的加速效果差距较大,如NVDLA利用了输入通道与输出通道的并行度,但UNet中有的CONV2D层通道数较少,NVDLA的PE利用率有可能不足
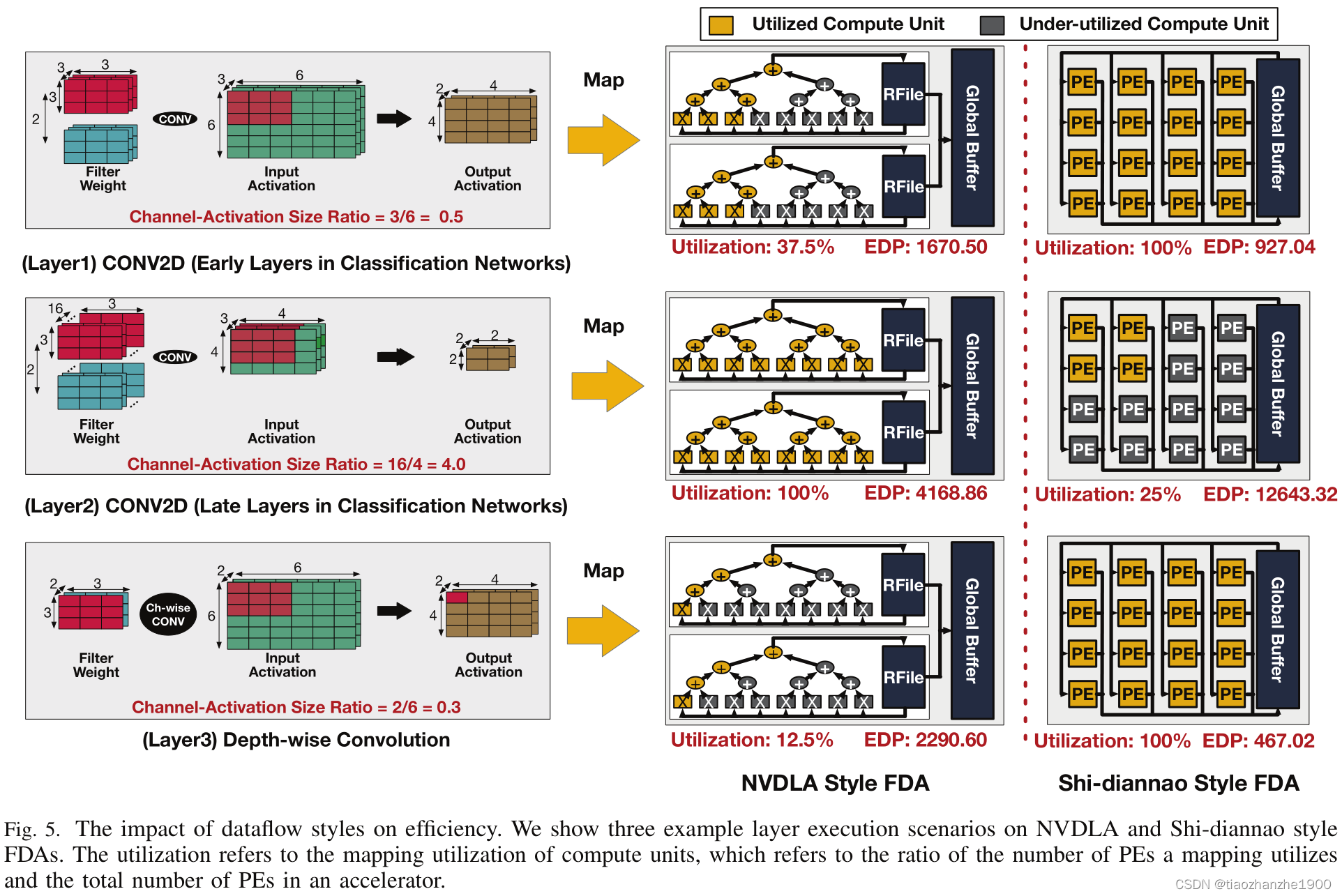
In this work, we propose a new class of DNN accelerators called heterogeneous dataflow accelerators (HDAs). HDAs provide flexibility by employing multiple sub-accelerators, each tuned for a different dataflow, within an accelerator chip
本篇论文的主要贡献:
- 提出的HDA包括了多个不同数据流的子加速单元
- 配套的设计空间探索算法以及mapping优化
调度算法:
- 贪婪法:首先为子加速器上的每一层分配最合适的加速器
- 当检测到子加速器的不平衡负载时,调度器探索降低总成本的替代层分配。用户可以指定最大允许负载不平衡系数,即子加速器之间的最大延迟除以最小延迟
- 深度优先层排序算法:首先调度DNN模型中的所有层,然后移动到另一个层
- 广度优先层排序算法:交错每个DNN模型的层执行
- 后处理消除初始调度中的冗余空闲时间:对于每个调度的层X,该算法搜索调度在层X之后的层Y,Y可以在X的结束时间执行。如果找到层Y,该算法重新排序这些层,使层Y紧接在层X之后
- 题目:Design Space Exploration of FPGA Based System with Multiple DNN Accelerators
- 时间:2021
- 期刊:IEEE Embedded Systems Letters
- 研究机构:印度理工学院
本篇论文的主要贡献: 针对FPGA上要跑多个神经网络,对于DNN 加速器DPU的设计空间探索
问题定义:
- 有 A = { A 1 , A 2 , . . . , A n } A = \{A_1, A_2, ..., A_n\} A={A1,A2,...,An}个任务,每个任务都可以用不同的网络实现,相应的网络精度不同
- 对于DPU,有 D = { D 1 , D 2 , . . . , D m } D = \{ D_1, D_2, ..., D_m\} D={D1,D2,...,Dm}m个不同的硬件配置,相应的面积与吞吐率不同
- 对于 N = { N 1 , N 2 , . . . , N s } N = \{N_1, N_2, ..., N_s\} N={N1,N2,...,Ns}个网络,在不同硬件下计算延时为t
- 假设有r个FPGA, F = { F 1 , F 2 , . . . , F r } F = \{F_1, F_2, ..., F_r\} F={F1,F2,...,Fr},面积和成本都不同
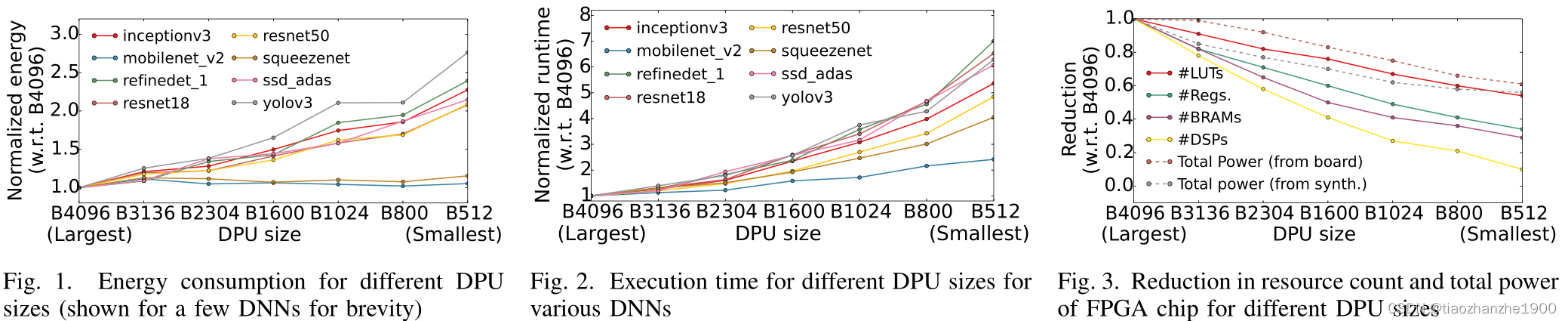
结论:
- 随着DPU规格的减少,LUT和寄存器开销不会成比例的降低
- 对于多个网络,多个DPU并行运行,资源不会成比例的增加,因为clock、bus、memory controller、Processing System不会成比例增加开销


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









