







文章目录
- 题目:Layerweaver: Maximizing Resource Utilization of Neural Processing Units via Layer-Wise Scheduling
- 时间:2021
- 会议:HPCA
- 研究机构:首尔大学
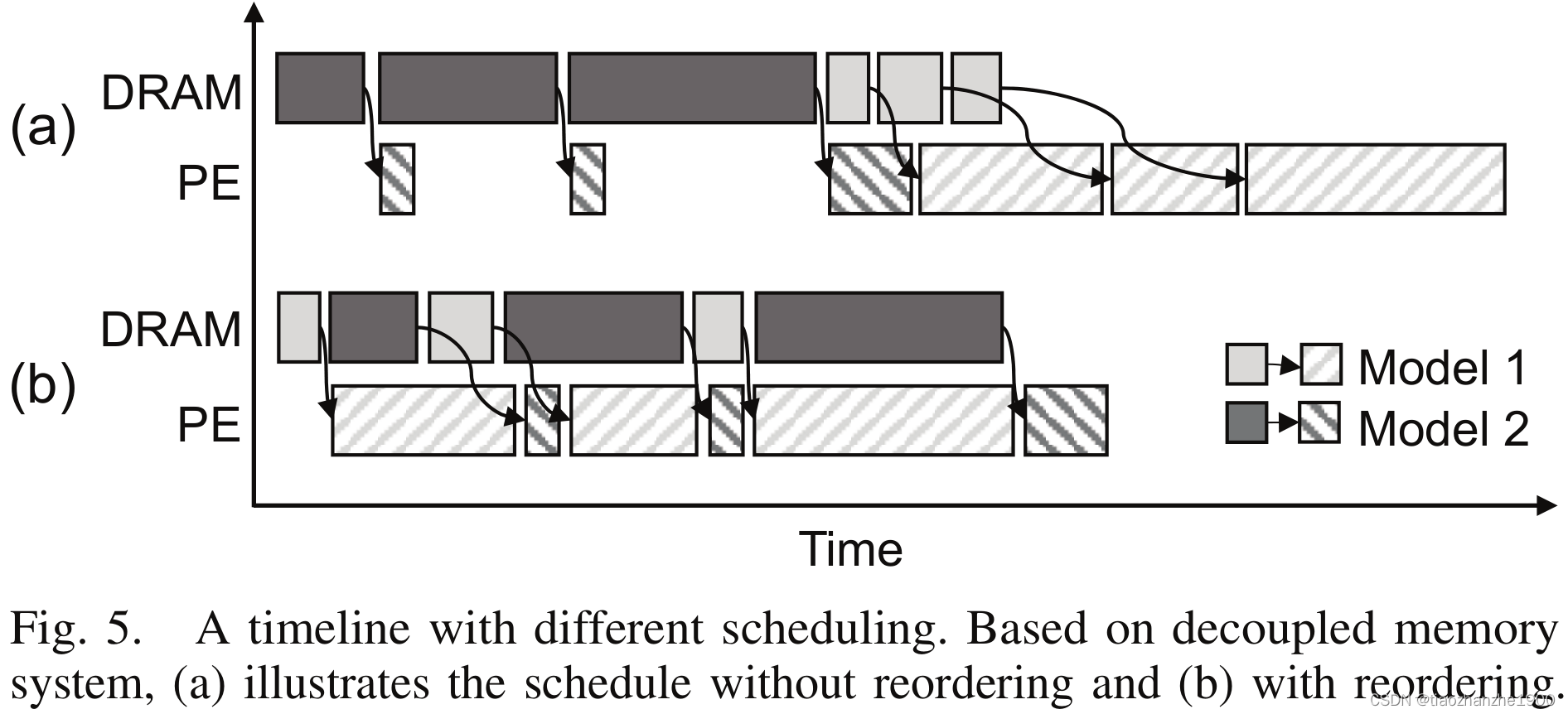
本篇论文的主要贡献: 针对多个DNN模型进行分时复用调度,来尽可能提高硬件计算与带宽的利用率
核心思路还是计算任务和通信任务的切分,以及不同网络之间的调度
- 题目:PREMA: A Predictive Multi-task Scheduling Algorithm For Preemptible Neural Processing Units
- 时间:2020
- 会议:HPCA
- 研究机构:KAIST
Machine Learning-as-a-service (MLaaS)
TensorRT Inference Server or TensorFlow Serving provide runtime features for a single NPU to handle multiple DNN inference queries (i.e., multi-tasking DNNs)
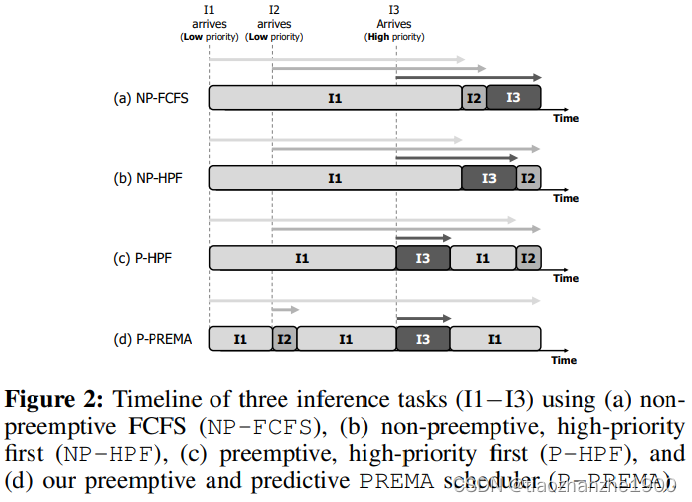
但是不同的DNN可以存在优先级的差别,即部分DNN对推理延时需求更高,这就要在非抢占式的先来先到服务non-preemptive, first-come first-serve (NP-FCFS)上进行优化
本篇论文的主要贡献:
本文提出了一个可抢占的NPU和一个predictive multi-task scheduler来满足高优先级推理的延迟需求,同时保持高吞吐量
硬件配置

Checkpointing Requirements
检查点似乎主要开销来自于输出特征图的搬运
Consequently, upon a preemption request, the context state that is checkpointed is the newly derived output activations potentially stored inside the UBUF and ACCQ.
Overall, the major checkpointing overhead comes from the output activations that have been derived up to the point the preemption request is to be serviced


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









