







文章目录
- 题目:Roller: Fast and Efficient Tensor Compilation for Deep Learning
- 时间:2022
- 会议:OSDI
- 研究机构:微软
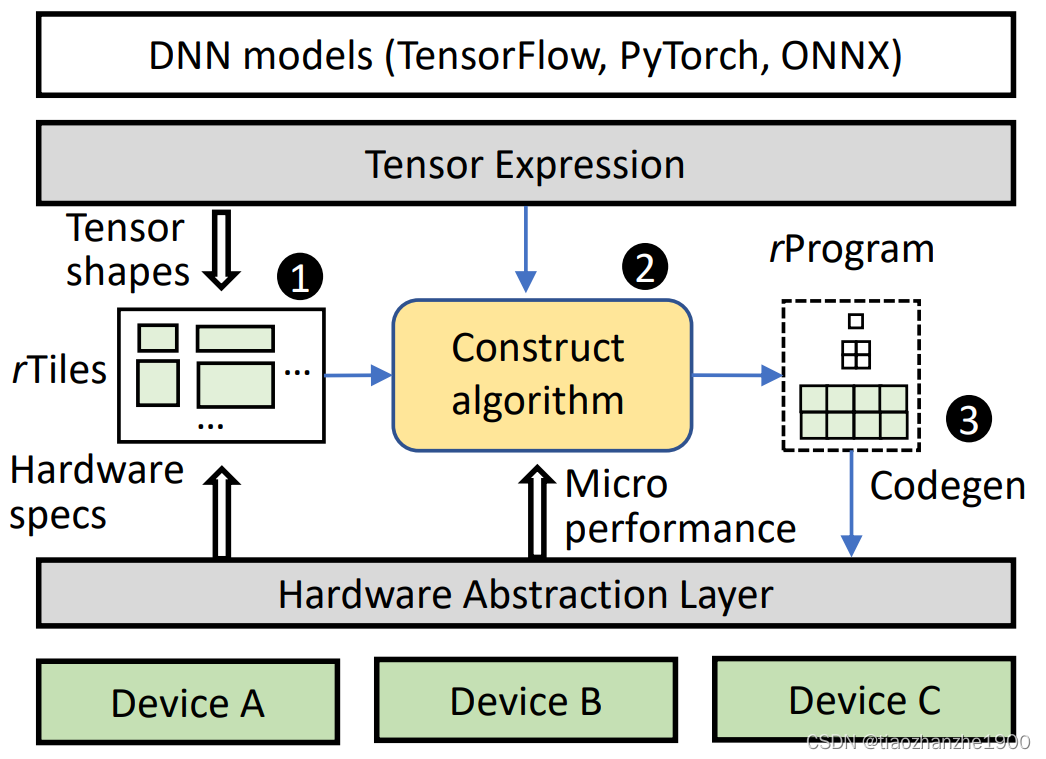
本篇论文的主要的motivation在于现在DNN的编译探索工作的时间比较长,特别是针对Nivida以外的硬件平台如AMD GPU和Graphcore IPU,所以这篇论文换了一个思路,采用构造的方式生成kernel,首先介绍基本概念:
- rTile:最基础的抽象层级,就是一个data tile,不过与计算和访存的基础尺寸对应
- rProgram:包括了load、store、compute的基于rTile的程序,可以满足GPU中的SM执行
- kernel:利用rProgram构造kernel
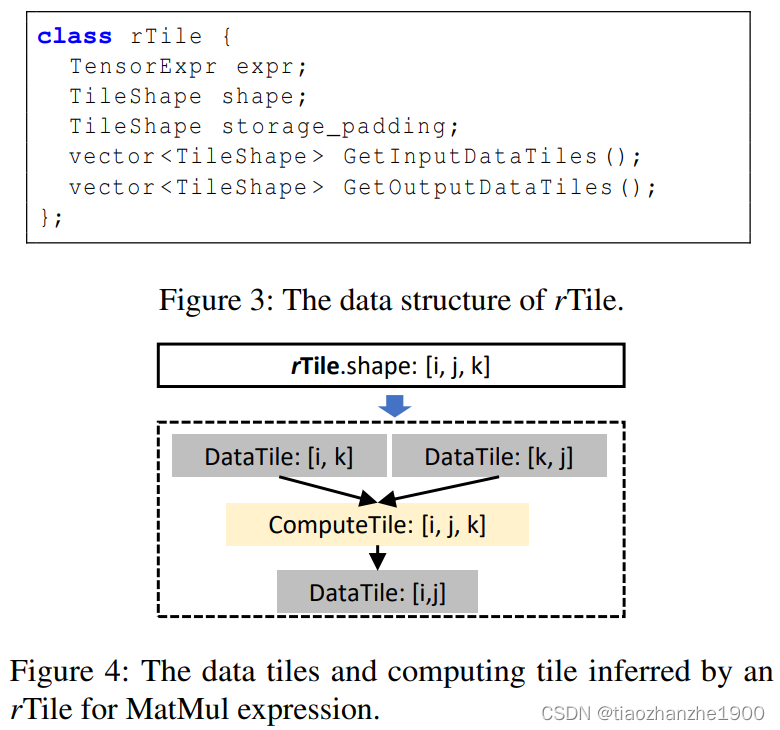
- rTile is a new tile abstraction that encapsulates tensor shapes that align with the key features of the underlying accelerator, thus achieving efficient execution by limiting the shape choices.
- rProgram: adopts a recursive rTile-based construction algorithm to gradually increase the size of the rTile shape to construct an rProgram that saturates a single execution unit of the accelerator (e.g., an SM, a streaming multi-processor in a NVIDIA GPU)
- kernel: performs the scale-out process, which simply replicates the resulting rProgram to other parallel execution units


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









