






FLoRA: 基于异构低秩适应的联邦微调大语言模型
Ziyao Wang 1 ^{1} 1, Zheyu Shen 1 ^{1} 1, Yexiao He 1 ^{1} 1, Guoheng Sun 1 ^{1} 1, Hongyi Wang 2 , 3 ^{2,3} 2,3, Lingjuan Lyu 4 ^{4} 4, Ang Li 1 ^{1} 1
- 马里兰大学帕克分校
- 罗格斯大学
- GenBio.ai
- 索尼研究院
摘要
大语言模型(LLMs)的快速发展推动了人工智能的进步,预训练的LLMs可以通过微调适应各种下游任务。联邦学习(FL)通过利用客户端的本地数据进行原位计算,进一步增强了隐私保护的微调,消除了数据移动的需求。然而,考虑到LLMs的巨大参数量,微调LLMs对于资源受限且异构的FL客户端来说是一个挑战。之前的方法采用了低秩适应(LoRA)进行高效的联邦微调,但在LoRA适配器上使用了传统的FL聚合策略。这些方法导致了数学上不准确的聚合噪声,降低了微调效果,并且未能解决异构LoRA的问题。在这项工作中,我们首先指出了现有联邦微调方法中LoRA聚合的数学错误。我们引入了一种名为FLoRA的新方法,通过一种新颖的基于堆叠的聚合方法,实现了跨客户端的异构LoRA适配器的联邦微调。我们的方法是无噪声的,并且无缝支持异构LoRA适配器。大量实验表明,FLoRA在同构和异构设置下均表现出色,超越了现有技术。我们设想这项工作将成为高效、隐私保护和准确的LLMs联邦微调的一个里程碑。我们的代码可在 https://github.com/ATP-1010/FederatedLLM 获取。
1 引言
大语言模型(LLMs)在各种任务中表现出色,例如聊天机器人 [1]、虚拟助手 [4]、搜索引擎 [10] 和医疗保健 [18; 16]。然而,将预训练的LLMs(例如Llama 2 [20])适应下游任务需要大量的计算资源来微调所有模型参数。为了缓解这个问题,提出了多种参数高效微调(PEFT)方法。其中最广泛使用的PEFT方法之一是低秩适应(LoRA)[9]。如图1顶部所示,LoRA添加了一个可训练的适配器分支 A \mathbf{A} A 和 B \mathbf{B} B 来计算模型更新 Δ W \boldsymbol{\Delta}\mathbf{W} ΔW,其中 A \mathbf{A} A 和 B \mathbf{B} B 的秩远小于预训练模型参数 W \mathbf{W} W。在应用LoRA进行微调时,仅更新 A \mathbf{A} A 和 B \mathbf{B} B,而整个 W \mathbf{W} W 被冻结,从而显著减少了GPU内存消耗。
微调LLMs需要大量数据以适应特定的下游任务。通常,这些数据分散在多个设备上,引发了隐私问题。例如,从医院集中聚合医疗数据以进行集中式LLM微调存在重大挑战。因此,为了在不泄露隐私数据的情况下促进微调,联邦学习(FL)变得至关重要,它能够在分布式客户端上进行LLM微调,同时保护数据隐私 [14; 24]。在这项工作中,我们专注于联邦微调,使分布式客户端能够协作微调LLMs以适应下游任务,同时保护数据隐私。
之前的工作FedIT提出了一种联邦微调方法 [25],将LoRA与FedAvg [14] 结合。在FedIT的每一轮FL中,客户端使用本地数据微调LoRA模块,然后将微调后的模块发送到服务器。服务器对所有本地LoRA模块进行平均,得到全局LoRA。由于仅微调和通信LoRA模块的权重,FedIT有效地减少了计算和通信成本。
然而,FedIT面临两个关键问题。首先,FedIT中对本地LoRA模块的简单平均引入了全局模型更新的噪声。具体来说,FedIT独立地对本地 A \mathbf{A} A和 B \mathbf{B} B进行平均,这给全局LoRA引入了数学错误。简而言之,
聚合噪声的原因:
∑ A × ∑ B ⏟ FedIT ≠ ∑ A × B ⏟ 数学上正确 。 \underbrace{\sum\mathbf{A}\times\sum\mathbf{B}}_{\text{FedIT}}\neq\underbrace{\sum\mathbf{A}\times\mathbf{B}}_{\text{数学上正确}}。 FedIT ∑A×∑B=数学上正确 ∑A×B。
我们将在第2节中通过理论分析详细阐述这个问题。这种不准确的聚合会阻碍收敛,导致更高的微调成本。其次,由于数据分布的异构性 [28; 11] 和硬件资源的异构性,客户端需要根据系统和数据的异构性调整LoRA的秩 [27]。然而,FedIT无法聚合具有异构秩的本地LoRA。
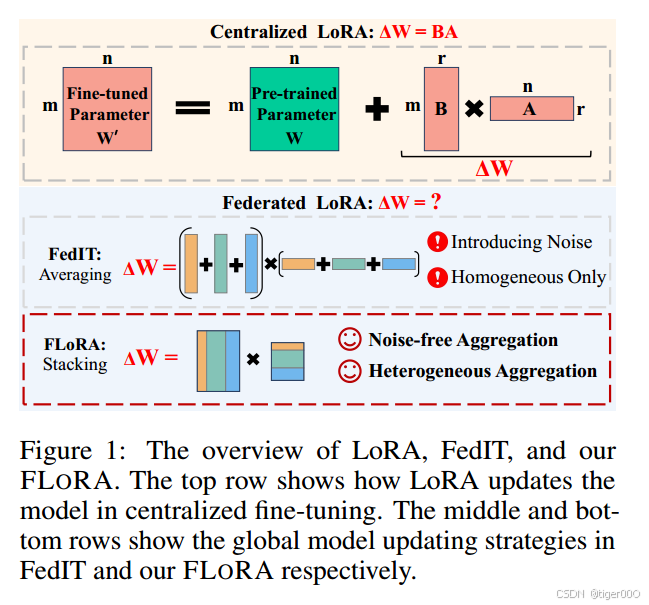
在这项工作中,我们提出了FLoRA,一种无聚合噪声的联邦微调方法,支持异构LoRA。具体来说,如图2所示,我们提出堆叠本地LoRA模块 A k \mathbf{A}_{k} Ak和 B k \mathbf{B}_{k} Bk,分别构建全局LoRA模块 A \mathbf{A} A和 B \mathbf{B} B,其中 A k \mathbf{A}_{k} Ak和 B k \mathbf{B}_{k} Bk表示第 k k k个客户端上的相应LoRA模块。这种堆叠方法在理论上被证明是准确的(第3.1节)。此外,它自然支持异构LoRA设置(第3.2节),因为堆叠不要求本地LoRA模块在客户端之间具有相同的秩。FLoRA的无噪声聚合加速了收敛,从而提高了联邦微调的整体计算和通信效率。此外,FLoRA可以有效地适应客户端之间的异构数据和计算资源,其中应用了异构秩。我们的主要贡献总结如下:
- 我们提出了FLoRA,一种基于LoRA的联邦微调算法,能够对本地LoRA模块进行无噪声聚合。理论分析表明,FLoRA消除了全局模型更新中的无意义中间项,从而加快了收敛速度并提高了性能。
- 所提出的堆叠机制支持跨客户端的异构LoRA秩,适应现实场景中的数据和系统异构性。这鼓励了具有异构数据和资源的客户端更广泛地参与联邦微调。
- 我们使用FLoRA对LLaMA、Llama2 [19] 和TinyLlama [26] 进行了微调,并在四个基准测试中评估了两个下游任务。结果表明,FLoRA在同构和异构设置下均优于现有技术。
2 预备知识
使用LoRA微调LLMs
LoRA [9] 使用两个分解的低秩矩阵来表示目标模块的更新:
W
′
=
W
+
Δ
W
=
W
+
B
A
,
\mathbf{W}^{\prime}=\mathbf{W}+\mathbf{\Delta W}=\mathbf{W}+\mathbf{B}\mathbf{A},
W′=W+ΔW=W+BA,
其中 W ∈ R m × n \mathbf{W}\in\mathbb{R}^{m\times n} W∈Rm×n和 W ′ ∈ R m × n \mathbf{W}^{\prime}\in\mathbb{R}^{m\times n} W′∈Rm×n分别表示目标模块(例如注意力模块)的预训练和微调参数。 A \mathbf{A} A和 B \mathbf{B} B是 Δ W \mathbf{\Delta W} ΔW的低秩分解,其中 A ∈ R r × n , B ∈ R m × r \mathbf{A}\in\mathbb{R}^{r\times n},\mathbf{B}\in\mathbb{R}^{m\times r} A∈Rr×n,B∈Rm×r,使得 Δ W = B A \mathbf{\Delta W}=\mathbf{B}\mathbf{A} ΔW=BA与 W \mathbf{W} W和 W ′ \mathbf{W}^{\prime} W′具有相同的维度。LoRA的秩记为 r r r,通常远小于 m m m和 n n n,从而显著减少了 Δ W \mathbf{\Delta W} ΔW的参数数量。在微调阶段,LoRA优化矩阵 A \mathbf{A} A和 B \mathbf{B} B,而不是直接更新 W \mathbf{W} W,从而大大减少了GPU内存的使用。例如,在LLaMA-7B [19] 的上下文中,注意力模块的原始维度为 W ∈ R 4096 × 4096 \mathbf{W}\in\mathbb{R}^{4096\times 4096} W∈R4096×4096,将LoRA的秩设置为16,分解后的矩阵为 A ∈ R 16 × 4096 \mathbf{A}\in\mathbb{R}^{16\times 4096} A∈R16×4096和 B ∈ R 4096 × 16 \mathbf{B}\in\mathbb{R}^{4096\times 16} B∈R4096×16。这种方法将可训练参数的数量减少到预训练模型总参数的0.78%,显著减少了GPU内存占用。
FedIT:平均同构LoRA
最广泛使用的FL算法,即FedAvg [14],通过加权平均聚合所有本地模型更新,以在每一轮通信中更新全局模型:
W ′ = W + ∑ k = 1 K p k Δ W k = W + Δ W , \mathbf{W}^{\prime}=\mathbf{W}+\sum_{k=1}^{K}p_{k}\mathbf{\Delta W}_{k}=\mathbf{W}+\mathbf{\Delta W}, W′=W+k=1∑KpkΔWk=W+ΔW,
其中 W ′ \mathbf{W}^{\prime} W′和 W \mathbf{W} W分别表示通信轮次前后的全局模型参数。 Δ W k \mathbf{\Delta W}_{k} ΔWk表示第 k k k个客户端的本地模型更新, p k p_{k} pk是对应的缩放因子,通常由本地数据大小加权, Δ W \mathbf{\Delta W} ΔW表示全局模型更新。
FedIT [25] 直接将FedAvg与LoRA结合,以实现联邦微调,其中每个客户端使用同构的秩微调LoRA模块。具体来说,客户端从服务器下载预训练的LLM,本地初始化并微调LoRA模块,然后将更新后的LoRA模块发送到服务器。服务器通过独立地对所有本地模块 A k \mathbf{A}_{k} Ak和 B k \mathbf{B}_{k} Bk进行加权平均来更新全局LoRA模块 A \mathbf{A} A和 B \mathbf{B} B:
A = ∑ k = 1 K p k A k , B = ∑ i = 0 K p k B k . \mathbf{A}=\sum_{k=1}^{K}p_{k}\mathbf{A}_{k},\quad\mathbf{B}=\sum_{i=0}^{K}p_{k}\mathbf{B}_{k}. A=k=1∑KpkAk,B=i=0∑KpkBk.
这种聚合方式与FedAvg几乎相同,只是仅训练和通信LoRA模块。然而,这种简单的聚合为联邦微调引入了额外的问题。首先,单个模块 A \mathbf{A} A或 B \mathbf{B} B并不是模型更新,只有 B A \mathbf{B}\mathbf{A} BA表示模型更新。因此,独立地对 A k \mathbf{A}_{k} Ak和 B k \mathbf{B}_{k} Bk进行平均以计算聚合梯度会为全局模型更新引入噪声。我们通过一个简单的例子来解释噪声是如何产生的,假设两个客户端使用FedIT进行联邦微调。在一轮通信中,两个客户端分别训练 A 0 \mathbf{A}_{0} A0、 B 0 \mathbf{B}_{0} B0和 A 1 \mathbf{A}_{1} A1、 B 1 \mathbf{B}_{1} B1。本地模型更新 Δ W 0 \mathbf{\Delta W}_{0} ΔW0和 Δ W 1 \mathbf{\Delta W}_{1} ΔW1是相应LoRA模块的乘积:
Δ W k = B k A k , k ∈ { 0 , 1 } . \mathbf{\Delta W}_{k}=\mathbf{B}_{k}\mathbf{A}_{k},k\in\{0,1\}. ΔWk=BkAk,k∈{0,1}.
根据公式2,预期的全局模型更新 Δ W \mathbf{\Delta W} ΔW可以通过加权平均 Δ W 0 \mathbf{\Delta W}_{0} ΔW0和 Δ W 1 \mathbf{\Delta W}_{1} ΔW1得到:
Δ W = p 0 Δ W 0 + p 1 Δ W 1 = p 0 B 0 A 0 + p 1 B 1 A 1 . \mathbf{\Delta W}=p_{0}\mathbf{\Delta W}_{0}+p_{1}\mathbf{\Delta W}_{1}=p_{0}\mathbf{B}_{0}\mathbf{A}_{0}+p_{1}\mathbf{B}_{1}\mathbf{A}_{1}. ΔW=p0ΔW0+p1ΔW1=p0B0A0+p1B1A1.
然而,根据公式3,FedIT独立地聚合 A \mathbf{A} A和 B \mathbf{B} B:
Δ W = B A = ( p 0 B 0 + p 1 B 1 ) ( p 0 A 0 + p 1 A 1 ) = p 0 2 B 0 A 0 + p 1 2 B 1 A 1 + p 0 p 1 ( B 0 A 1 + B 1 A 0 ) . \mathbf{\Delta W} =\mathbf{B}\mathbf{A}=(p_{0}\mathbf{B}_{0}+p_{1}\mathbf{B}_{1})(p_{0}\mathbf{A}_{0}+p_{1}\mathbf{A}_{1}) =p_{0}^{2}\mathbf{B}_{0}\mathbf{A}_{0}+p_{1}^{2}\mathbf{B}_{1}\mathbf{A}_{1}+p_{0}p_{1}(\mathbf{B}_{0}\mathbf{A}_{1}+\mathbf{B}_{1}\mathbf{A}_{0}). ΔW=BA=(p0B0+p1B1)(p0A0+p1A1)=p02B0A0+p12B1A1+p0p1(B0A1+B1A0).
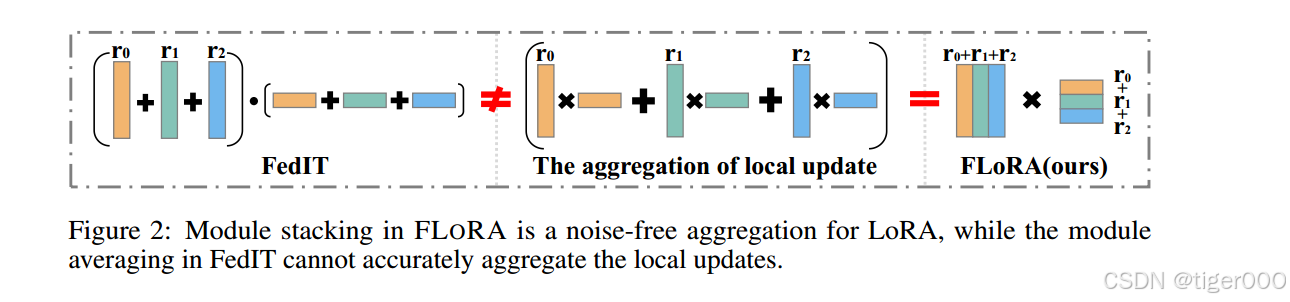
公式6中的全局模型更新与公式2中的预期更新不同,主要是由于下划线的中间项,该中间项是通过来自不同客户端的LoRA模块的交叉乘积获得的。这个中间项在模型聚合中引入了意外的噪声。随着客户端数量的增加,这个噪声项变得比真实的全局更新大得多,显著减缓了微调进度。此外,FedIT将缩放因子 p k p_{k} pk应用于 A k \mathbf{A}_{k} Ak和 B k \mathbf{B}_{k} Bk,导致本地模型更新 Δ W k \boldsymbol{\Delta}\mathbf{W}_{k} ΔWk的系数为 p k 2 p_{k}^{2} pk2,加剧了LoRA聚合中的误差。如图2所示,FedIT中的平均算法是一种不准确的聚合方法,导致收敛速度变慢和计算成本增加。
FedIT的另一个缺陷是它不支持异构LoRA模块的聚合。FL中的本地数据可能在客户端之间表现出显著的异构性 [28; 11]。如果客户端配置的秩高于本地数据复杂性所需的实际秩,可能会导致过拟合。相反,如果秩太小,可能缺乏必要的泛化能力,无法有效地从本地数据集中学习(图4)。此外,客户端之间的异构计算资源也需要异构秩的部署,例如,内存较小的客户端只能训练秩较小的LoRA模块。AdaLoRA [27] 提出根据可用计算资源自适应调整LoRA的秩。因此,跨客户端部署异构秩是适应数据和系统异构性的迫切需求。然而,根据公式3,FedIT只能聚合具有同构秩的LoRA模块。
3 提出的方法:FLoRA
基于堆叠的无噪声聚合
受上述问题的启发,我们提出了一种新颖的聚合机制,通过聚合本地LoRA模块准确计算全局模型更新 Δ W \boldsymbol{\Delta}\mathbf{W} ΔW,并有效支持异构LoRA。根据矩阵乘法原理和LoRA中的模型更新规则(即公式1),模型更新 Δ W \boldsymbol{\Delta}\mathbf{W} ΔW中位置 ( x , y ) (x,y) (x,y)处的元素计算为 B \mathbf{B} B的第 x x x列和 A \mathbf{A} A的第 y y y行对应元素的乘积之和:
δ x y = ∑ i = 0 r a y i b x i , \delta_{xy}=\sum_{i=0}^{r}a_{yi}b_{xi}, δxy=i=0∑rayibxi,
其中 δ x y \delta_{xy} δxy表示 Δ W \boldsymbol{\Delta}\mathbf{W} ΔW中位置 ( x , y ) (x,y) (x,y)处的元素。 a y i , b x i a_{yi},b_{xi} ayi,bxi分别是 A \mathbf{A} A和 B \mathbf{B} B中位置 ( y , i ) (y,i) (y,i)和 ( x , i ) (x,i) (x,i)处的元素。根据公式3.1,LoRA中的模型更新可以表示为 A \mathbf{A} A的相应行与 B \mathbf{B} B的列的乘积之和。
为了进一步说明这一概念,我们考虑一个简化示例,其中LoRA模块的维度为 A ∈ R 2 × 3 \mathbf{A}\in\mathbb{R}^{2\times 3} A∈R2×3和 B ∈ R 3 × 2 \mathbf{B}\in\mathbb{R}^{3\times 2} B∈R3×2。如公式8所述, A \mathbf{A} A和 B \mathbf{B} B可以分解为两个秩为 r = 1 r=1 r=1的子矩阵, A \mathbf{A} A和 B \mathbf{B} B的乘积则计算为两个相应子矩阵的乘积之和:
B A = [ b 00 , b 01 b 10 , b 11 b 20 , b 21 ] ⋅ [ a 00 , a 10 , a 20 a 01 , a 11 , a 21 ] = [ b 00 b 10 b 20 ] ⋅ [ a 00 , a 10 , a 20 ] + [ b 01 b 11 b 21 ] ⋅ [ a 01 , a 11 , a 21 ] \mathbf{B}\mathbf{A}=\begin{bmatrix}b_{00},b_{01}\\ b_{10},b_{11}\\ b_{20},b_{21}\end{bmatrix}\cdot\begin{bmatrix}a_{00},a_{10},a_{20}\\ a_{01},a_{11},a_{21}\end{bmatrix}=\begin{bmatrix}b_{00}\\ b_{10}\\ b_{20}\end{bmatrix}\cdot\left[a_{00},a_{10},a_{20}\right]+\begin{bmatrix}b_{01}\\ b_{11}\\ b_{21}\end{bmatrix}\cdot\left[a_{01},a_{11},a_{21}\right] BA= b00,b01b10,b11b20,b21 ⋅[a00,a10,a20a01,a11,a21]= b00b10b20 ⋅[a00,a10,a20]+ b01b11b21 ⋅[a01,a11,a21]
为了从另一个角度解决聚合挑战,让我们考虑这样一种情况:我们有多个LoRA模块对 A k \mathbf{A}_{k} Ak、 B k \mathbf{B}_{k} Bk,由客户端优化。每对满足维度 A k ∈ R r h × n \mathbf{A}_{k}\in\mathbb{R}^{r_{h}\times n} Ak∈Rrh×n和 B k ∈ R m × r k \mathbf{B}_{k}\in\mathbb{R}^{m\times r_{k}} Bk∈Rm×rk。与公式8类似,这些模块对的乘积之和是堆叠模块的乘积,即 ∑ k = 1 K B k A k = B A \sum_{k=1}^{K}\mathbf{B}_{k}\mathbf{A}_{k}=\mathbf{B}\mathbf{A} ∑k=1KBkAk=BA,其中 B \mathbf{B} B表示所有 B k \mathbf{B}_{k} Bk模块在维度 m m m上的堆叠, A \mathbf{A} A是所有 A k \mathbf{A}_{k} Ak在维度 n n n上的堆叠。图2直观地展示了这一概念,其中橙色、绿色和蓝色矩形分别表示 A k \mathbf{A}_{k} Ak、 B k \mathbf{B}_{k} Bk及其相应的乘积。三个乘积的聚合反映了所有客户端训练的 B k \mathbf{B}_{k} Bk和 A k \mathbf{A}_{k} Ak对的堆叠 B \mathbf{B} B和 A \mathbf{A} A的乘积。这一机制表明,在联邦微调的背景下,我们可以通过简单地堆叠本地LoRA模块来实现本地更新的无噪声聚合。此过程还避免了传输完整的模型参数,从而降低了通信成本。
为了便于讨论,我们引入了由“ ⊕ \oplus ⊕”表示的堆叠操作,以表示图2中描述的模块聚合。该操作在数学上定义为:
A = A 0 ⊕ A 1 ⊕ A 2 , B = B 0 ⊕ B 1 ⊕ B 2 , \mathbf{A}=\mathbf{A}_{0}\oplus\mathbf{A}_{1}\oplus\mathbf{A}_{2},\;\mathbf{B}=\mathbf{B}_{0}\oplus\mathbf{B}_{1}\oplus\mathbf{B}_{2}, A=A0⊕A1⊕A2,B=B0⊕B1⊕B2,
其中 A k ∈ R r h × n , A ∈ R ( r 0 + r 1 + r 2 ) × n , B k ∈ R m × r k , B ∈ R m × ( r 0 + r 1 + r 2 ) \mathbf{A}_{k}\in\mathbb{R}^{r_{h}\times n},\mathbf{A}\in\mathbb{R}^{(r_{0}+r_{1}+r_{2})\times n},\mathbf{B}_{k}\in\mathbb{R}^{m\times r_{k}},\mathbf{B}\in\mathbb{R}^{m\times(r_{0}+r_{1}+r_{2})} Ak∈Rrh×n,A∈R(r0+r1+r2)×n,Bk∈Rm×rk,B∈Rm×(r0+r1+r2)。
在公式9中,“ ⊕ \oplus ⊕”表示对于 A \mathbf{A} A,每个后续模块垂直堆叠在前一个模块下方,而对于 B \mathbf{B} B,每个模块水平堆叠在前一个模块的右侧。
我们现在可以形式化关于LoRA模块聚合的结论。 K K K个LoRA模块对的乘积之和等于其堆叠矩阵的乘积:
∑ k = 0 K B k A k = ( B 0 ⊕ . . . ⊕ B K ) ( A 0 ⊕ . . . ⊕ A K ) \sum_{k=0}^{K}\mathbf{B}_{k}\mathbf{A}_{k}=(\mathbf{B}_{0}\oplus...\oplus\mathbf{B}_{K})(\mathbf{A}_{0}\oplus...\oplus\mathbf{A}_{K}) k=0∑KBkAk=(B0⊕...⊕BK)(A0⊕...⊕AK)
这一基本原则将指导FLoRA的设计,因为它允许在不传输整个模型参数的情况下高效且有效地聚合本地更新。
FLoRA:基于堆叠的异构LoRA联邦微调
基于堆叠的聚合不仅促进了LoRA模块的准确聚合,还固有地支持异构LoRA秩。只要每个客户端微调相同的预训练模型,即它们共享相同的维度 m m m和 n n n,这种方法对每个本地LoRA模块的秩没有限制。
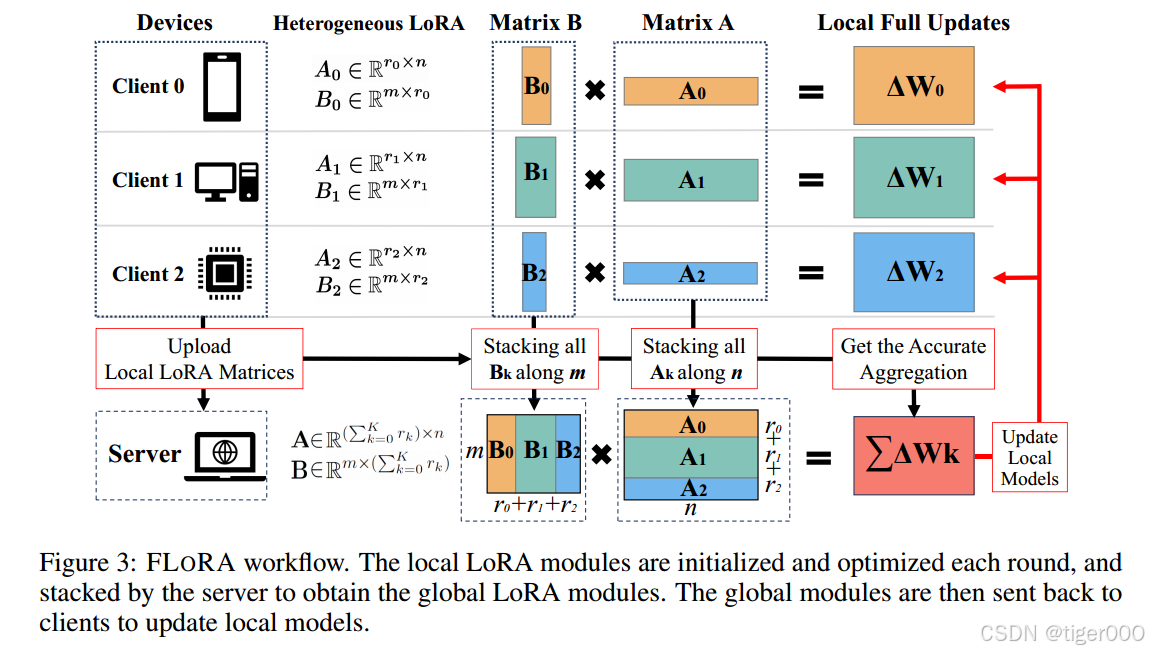
通过采用基于堆叠的聚合机制,我们引入了FLoRA,旨在促进具有异构LoRA的LLMs的联邦微调。让我们用一个具体示例来说明应用FLoRA的关键步骤,其中 K K K个异构客户端参与微调LLM,预训练参数记为 W \mathbf{W} W。
初始化。服务器首先将预训练模型参数 W \mathbf{W} W分发给所有 K K K个客户端。然后,客户端根据本地数据的复杂性和可用本地资源初始化其本地LoRA模块。LoRA秩的调整超出了本文的范围,但现有工作如AdaLoRA [27] 可以促进秩的调整。
本地微调。初始化后,客户端使用本地数据对其本地LoRA模块进行多次迭代训练。然后,客户端将本地LoRA模块发送回服务器。请注意,客户端在每轮本地微调之前初始化本地LoRA模块。
基于堆叠的LoRA聚合。在收到参与客户端的异构LoRA模块后,服务器根据公式10堆叠所有 B k \mathbf{B}_{k} Bk和 A k \mathbf{A}_{k} Ak,得到全局 A ∈ R ( ∑ k = 0 K r k ) × n \mathbf{A}\in\mathbb{R}^{(\sum_{k=0}^{K}r_{k})\times n} A∈R(∑k=0Krk)×n和 B ∈ R m × ( ∑ k = 0 K r k ) \mathbf{B}\in\mathbb{R}^{m\times(\sum_{k=0}^{K}r_{k})} B∈Rm×(∑k=0Krk)。FLoRA的聚合过程可描述如下:
A = p 0 A 0 ⊕ p 1 A 1 ⊕ . . . ⊕ p K A K , B = B 0 ⊕ B 1 ⊕ B 2 ⊕ . . . ⊕ B K \mathbf{A} =p_{0}\mathbf{A}_{0}\oplus p_{1}\mathbf{A}_{1}\oplus...\oplus p_{K}\mathbf{A}_{K},\quad\mathbf{B}=\mathbf{B}_{0}\oplus\mathbf{B}_{1}\oplus\mathbf{B}_{2}\oplus...\oplus\mathbf{B}_{K} A=p0A0⊕p1A1⊕...⊕pKAK,B=B0⊕B1⊕B2⊕...⊕BK
其中 p k p_{k} pk表示每个本地更新的缩放因子,由本地数据大小与全局数据的相对大小决定:
p k = l e n ( D k ) l e n ( ∑ k = 0 K D k ) . p_{k}=\frac{len(D_{k})}{len(\sum_{k=0}^{K}D_{k})}. pk=len(∑k=0KDk)len(Dk).
请注意,缩放因子 p k p_{k} pk应仅应用于 A k \mathbf{A}_{k} Ak和 B k \mathbf{B}_{k} Bk中的一个,以避免在最终模型更新 B A \mathbf{B}\mathbf{A} BA中对因子进行平方。此方法确保了如公式10所述的无噪声聚合机制。
更新本地模型。在每轮无噪声聚合后,服务器将更新后的全局LoRA模块 A \mathbf{A} A和 B \mathbf{B} B重新分发给客户端。客户端然后使用 B A \mathbf{B}\mathbf{A} BA更新本地模型并继续微调。使用堆叠方法,更新后的全局LoRA模块 A \mathbf{A} A和 B \mathbf{B} B的维度比FedIT大,可能导致每轮通信开销增加。然而,经验观察表明,联邦微调通常只需要有限的通信轮次即可获得令人满意的结果,如第4节所述。此外,值得注意的是,LoRA模块 A \mathbf{A} A和 B \mathbf{B} B仅占预训练模型总大小的一小部分,该模型在初始化阶段分发给客户端。因此,堆叠方法的额外通信开销可以忽略不计,不会显著影响联邦微调的效率。
4 实验
FLoRA的关键特性是(i)无噪声聚合和(ii)支持异构LoRA模块。在本节中,我们验证了这些关键特性在各种LLM微调任务中的表现。我们首先研究了FLoRA的性能,并将其与FedIT在同构设置下进行比较,以展示无噪声聚合的优势 [25]。然后,我们在合成异构设置中检查性能,并将FLoRA与一种简单的零填充方法进行比较。最后,我们对缩放因子、LoRA秩的异构性以及FLoRA的额外通信开销进行了消融研究。
实验设置
模型、数据集和实验设置。我们在实验中使用三种不同规模的Llama模型:TinyLlama(11亿参数)[26],以及Llama [19] 和Llama2 [20] 的70亿参数版本,以评估FLoRA在不同模型容量下的表现。根据原始LoRA论文 [9] 的配置,LoRA模块仅应用于自注意力层。
我们使用Databricks-dolly-15k [25] 指令数据集、Alpaca数据集 [17] 和Wizard数据集 [12] 进行问答(QA)任务,并使用Wizard和ShareGPT进行聊天助手任务。我们分别在MMLU [7] 上评估联邦微调模型的QA任务,在MT-bench [29] 上评估聊天助手任务。我们按照FedIT [25] 中的非IID设置随机抽取10个客户端。其他实验配置详见附录A。
基线。我们将FLoRA与四种基线进行比较。(1)FedIT:这是最先进的联邦微调方法 [25],它将LoRA与FedAvg结合。我们仅在同构LoRA实验中应用FedIT,因为它不支持异构LoRA。(2)零填充:这是一种使FedIT支持异构LoRA的方法 [3]。它将所有异构本地秩扩展到客户端中的最大秩,并用 0 0 0填充其余部分。(3)集中式微调:我们将FLoRA与具有相同超参数和配置的集中式LoRA进行比较。(4)独立:客户端在本地微调预训练模型,不进行联邦。

实验结果
同构LoRA。我们首先评估FLoRA在同构LoRA下的性能。具体来说,所有客户端共享相同的LoRA秩16。如表1所示,FLoRA在所有评估的模型和任务中始终优于FedIT。这在TinyLlama和Llama模型的MT-bench分数中尤为明显,FLoRA的性能至少比FedIT高出0.2。一个显著的例子是使用Wizard数据集微调的Llama模型的MT-bench分数,FLoRA得分为4.21,超过了FedIT的3.07。在MMLU测试集上,FLoRA在所有设置中均优于FedIT。例如,考虑使用Dolly微调的TinyLlama模型,FLoRA的准确率几乎是FedIT的两倍。虽然FedIT在某些情况下与FLoRA的表现相当,如在MMLU上使用Alpaca数据集时,但性能差距很小。有趣的是,在某些情况下,FLoRA的表现不仅超过了FedIT,还超过了集中式微调的表现。这种现象在使用Alpaca和Wizard数据集微调的TinyLlama模型中观察到,表明联邦微调中客户端上的较小数据量可能有助于减轻过拟合,从而增强模型的泛化能力。Llama2模型的实验结果见附录A,其趋势与TinyLlama和Llama相同。这三个模型的一致观察结果表明,FLoRA在同构LoRA设置下始终优于FedIT。

异构LoRA。与FedIT相比,FLoRA的一个显著优势在于其固有地支持异构LoRA配置。在异构LoRA设置中,我们对10个客户端应用了不同的本地LoRA秩,即[64, 32, 16, 16, 8, 8, 4, 4, 4, 4],模拟了客户端具有异构计算资源的现实场景。如表1和表4所示,FLoRA不仅适应了异构秩而没有性能下降,而且在大多数同构设置中保持了结果的一致性。这与FedIT的表现形成鲜明对比,零填充的应用显著降低了其在MMLU和MT-bench上的表现。这表明零填充加剧了FedIT在聚合过程中的固有噪声问题,对微调性能的管理提出了重大挑战。例如,通过应用零填充方法,使用Alpaca数据集微调的Llama模型的MMLU准确率急剧下降至7.97%。结果表明,FLoRA不仅有效地适应了异构LoRA秩,而且与基线方法相比保持了强大的训练性能。它有效地促进了具有不同计算能力的设备参与异构联邦微调任务。此外,FLoRA可以与AdaLoRA [27] 无缝集成,后者动态调整客户端的LoRA秩,结果见附录A。
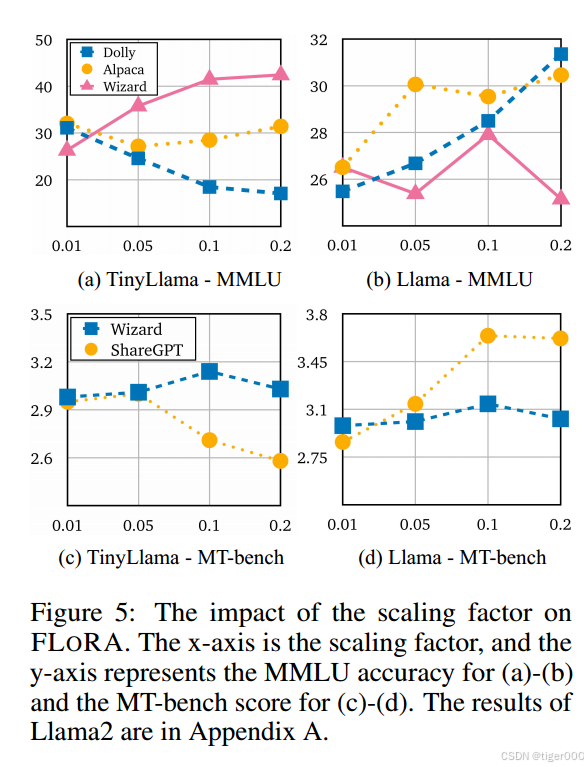
缩放因子的影响。缩放因子,即公式12中的 p k p_{k} pk,在FL的有效性中起着关键作用 [21]。我们进行了实验,研究不同缩放因子如何影响FLoRA的性能。鉴于默认缩放因子设置为0.1,假设10个客户端的本地数据集大小相等,我们探索了其他缩放因子的影响,即0.01、0.05和0.2。结果总结在图5中。结果并未揭示联邦微调在不同设置下的明确模式或最佳缩放因子。特定缩放因子的有效性似乎取决于所使用的数据集、任务和模型。例如,当使用Dolly数据集微调TinyLlama时,较低的缩放因子0.01产生了最高的准确率,显著优于0.1和0.2的缩放因子。相反,使用Wizard数据集微调的模型表现出对较高缩放因子0.2的偏好,实现了最佳性能,而最低缩放因子0.01效果最差。在Llama模型的情况下,较大的缩放因子始终促进了更好的微调性能。将FLoRA应用于Dolly和Alpaca时,缩放因子为0.2时表现最佳。这些观察结果表明,选择适当的缩放因子高度依赖于特定的数据集和模型特征,强调了在联邦微调中需要量身定制的方法。
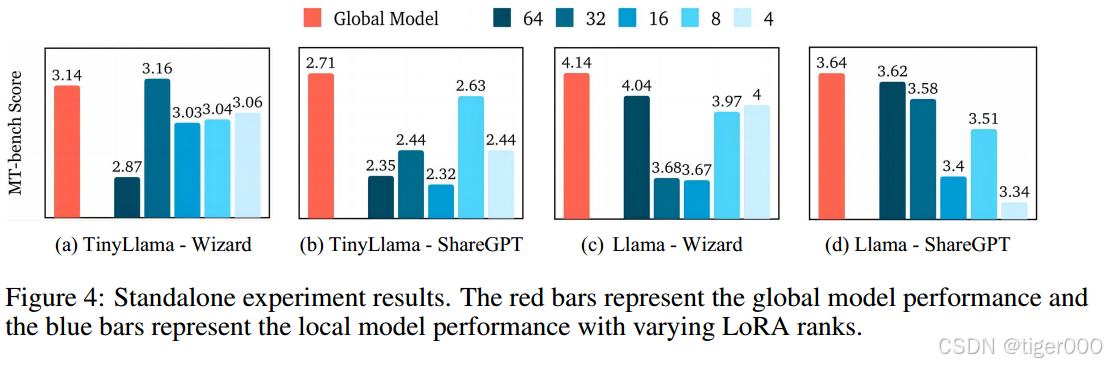
异构LoRA秩的影响。尽管上述结果表明FLoRA有效地支持了异构LoRA的联邦微调,但值得进一步研究联邦微调如何改进具有不同秩的本地模型。受此启发,我们评估了具有LoRA秩64、32、16、8和4的本地模型的MT-bench分数,结果如图4所示。全局模型分数以红色条显示,而本地模型以蓝色条显示,颜色越深表示秩越高。结果表明,全局模型优于所有本地模型,除了使用Wizard数据集微调的TinyLlama模型的一个案例,其中秩为32的客户端略微超过了全局模型。这证明了FLoRA能够有效地综合来自不同客户端的知识。
关于LoRA秩的影响,秩为8在各种模型和数据集中始终表现出色。然而,在极端秩下,性能出现分歧;例如,使用Wizard数据集微调的TinyLlama模型在LoRA秩为64时表现不如较小秩的模型,但Llama模型在秩为64时优于较小秩的模型。这也表明跨客户端的异构秩部署是一个现实设置。这些观察结果表明,最佳LoRA秩与模型容量之间可能存在正相关关系,这激励了未来研究的进一步探索。
5 讨论
FLoRA的通信开销。如第3节所述,服务器需要向客户端发送全局LoRA模块,这可能会引起对通信开销增加的担忧。为了量化这一点,我们比较了全微调、FedIT和FLoRA在三轮通信中的通信参数。
如图6所示,尽管FLoRA传输的参数略多于FedIT,但与全微调相比,它仍然显著减少了开销。这是因为在联邦微调中,尤其是在大型模型中,主要的通信负载是初始全模型参数的传输。随后的轮次主要涉及较小的更新(例如LoRA矩阵)。因此,尽管FLoRA引入了这些更新的额外通信,但对总通信成本的整体影响仍然可以忽略不计,使其与FedIT的成本相当。尽管与FedIT相比,FLoRA的通信略有增加,但它提高了微调效果并支持异构LoRA秩,使其成为联邦微调中的优选解决方案。
FLoRA的隐私保护。FLoRA要求堆叠所有客户端上传的LoRA模块,这引入了潜在的隐私问题,因为恶意客户端可能通过服务器发送的全局LoRA模块推断其他客户端的LoRA矩阵。为了解决这个问题,我们将所有本地LoRA模块拆分为秩为1的子模块,然后以随机顺序堆叠这些子模块。这种方法防止了恶意客户端从其他客户端恢复本地LoRA模块。此外,FLoRA还与标准隐私机制(如加密 [2] 和差分隐私(DP)[22])兼容,使其与FL的隐私保护性质保持一致。
6 相关工作
LLMs的参数高效微调。参数高效微调(PEFT)旨在减少可训练参数的数量。BitFit [23] 仅微调偏置,同时实现了与全微调相似的准确率。其他工作如 [8] 和 [15] 应用了在Transformer块之间添加预训练适配器层的迁移学习。LoRA [9] 采用两个低秩矩阵的乘积来表示全微调中的梯度,从而实现了内存高效的微调。AdaLoRA [27] 通过自适应分配参数预算来优化LoRA,从而增强了LoRA的灵活性。还有许多关于在各种方面优化LoRA的工作 [5; 6; 13]。
LLMs的联邦微调。联邦微调旨在从多个设备上的数据集中提取知识,同时保护数据隐私。FedIT [25] 利用FL框架进行LLMs的微调。它使用LoRA作为本地微调策略。然而,由于不支持异构LoRA的问题,限制了其使用。[3] 试图通过零填充本地LoRA模块来解决这个问题。然而,这种填充过程导致了额外的计算开销。此外,它分别对 A \mathbf{A} A和 B \mathbf{B} B模块进行平均,为全局模型引入了噪声。
7 结论
在这项工作中,我们指出了当前联邦微调方法(例如FedIT)的局限性,以及在现实场景中应用联邦微调的挑战,即跨客户端的异构LoRA秩。为了克服这些实际挑战并扩大联邦微调的适用性,我们引入了FLoRA,通过提出的基于堆叠的LoRA聚合机制,实现了对异构LoRA模块的准确聚合。我们的大量实验表明,FLoRA在同构和异构LoRA设置下均优于现有技术。此外,我们的启发式结果为未来在轻量级和准确的LLMs联邦微调研究提供了宝贵的见解。
图6:通信参数数量与全微调的比率。
参考文献
-
[1] Desiree Bill and Theodor Eriksson. Fine-tuning a llm using reinforcement learning from human feedback for a therapy chatbot application, 2023.
-
[2] Yansong Chang, Kai Zhang, Junqing Gong, and Haifeng Qian. Privacy-preserving federated learning via functional encryption, revisited. IEEE Transactions on Information Forensics and Security, 18:1855-1869, 2023.
-
[3] Yae Jee Cho, Luyang Liu, Zheng Xu, Aldi Fahrezi, Matt Barnes, and Gauri Joshi. Heterogeneous lora for federated fine-tuning of on-device foundation models. In International Workshop on Federated Learning in the Age of Foundation Models in Conjunction with NeurIPS 2023, 2023.
-
[4] Xin Luna Dong, Seungwhan Moon, Yifan Ethan Xu, Kshitiz Malik, and Zhou Yu. Towards next-generation intelligent assistants leveraging llm techniques. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 5792-5793, 2023.
-
[5] Shwai He, Liang Ding, Daize Dong, Miao Zhang, and Dacheng Tao. Sparseadapter: An easy approach for improving the parameter-efficiency of adapters. arXiv preprint arXiv:2210.04284, 2022.
-
[6] Shwai He, Run-Ze Fan, Liang Ding, Li Shen, Tianyi Zhou, and Dacheng Tao. Mera: Merging pretrained adapters for few-shot learning. arXiv preprint arXiv:2308.15982, 2023.
-
[7] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In International Conference on Learning Representations, 2020.
-
[8] Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. In International Conference on Machine Learning, pages 2790-2799. PMLR, 2019.
-
[9] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
-
[10] Dominique Kelly, Yimin Chen, Sarah E Cornwell, Nicole S Delellis, Alex Mayhew, Sodiq Onaolapo, and Victoria L Rubin. Bing chat: The future of search engines? Proceedings of the Association for Information Science and Technology, 60(1):1007-1009, 2023.
-
[11] Xiang Li, Kaixuan Huang, Wenhao Yang, Shusen Wang, and Zhihua Zhang. On the convergence of fedavg on non-iid data. arXiv preprint arXiv:1907.02189, 2019.
-
[12] Haipeng Luo, Qingfeng Sun, Can Xu, Pu Zhao, Jianguang Lou, Chongyang Tao, Xiubo Geng, Qingwei Lin, Shifeng Chen, and Dongmei Zhang. Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct. arXiv preprint arXiv:2308.09583, 2023.
-
[13] Yuren Mao, Yuhang Ge, Yijiang Fan, Wenyi Xu, Yu Mi, Zhonghao Hu, and Yunjun Gao. A survey on lora of large language models. arXiv preprint arXiv:2407.11046, 2024.
-
[14] Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics, pages 1273-1282. PMLR, 2017.
-
[15] Jonas Pfeiffer, Aishwarya Kamath, Andreas Ruckle, Kyunghyun Cho, and Iryna Gurevych. Adapterfusion: Non-destructive task composition for transfer learning. arXiv preprint arXiv:2005.00247, 2020.
-
[16] Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. Large language models encode clinical knowledge. Nature, 620(7972):172-180, 2023.
-
[17] Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023.
-
[18] Arun James Thirunavukarasu, Darren Shu Jeng Ting, Kabilan Elangovan, Laura Gutierrez, Ting Fang Tan, and Daniel Shu Wei Ting. Large language models in medicine. Nature medicine, 29(8):1930-1940, 2023.
-
[19] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothee Lacroix, Baptiste Roziere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
-
[20] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
-
[21] Ziyao Wang, Jianyu Wang, and Ang Li. Fedhyper: A universal and robust learning rate scheduler for federated learning with hypergradient descent. arXiv preprint arXiv:2310.03156, 2023.
-
[22] Da Yu, Saurabh Naik, Arturs Backurs, Sivakanth Gopi, Huseyin A Inan, Gautam Kamath, Janardhan Kulkarni, Yin Tat Lee, Andre Manoel, Lukas Wutschitz, et al. Differentially private fine-tuning of language models. arXiv preprint arXiv:2110.06500, 2021.
-
[23] Elad Ben Zaken, Shauli Ravfogel, and Yoav Goldberg. Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models. arXiv preprint arXiv:2106.10199, 2021.
-
[24] Chen Zhang, Yu Xie, Hang Bai, Bin Yu, Weihong Li, and Yuan Gao. A survey on federated learning. Knowledge-Based Systems, 216:106775, 2021.
-
[25] Jianyi Zhang, Saeed Vahidian, Martin Kuo, Chunyuan Li, Ruiyi Zhang, Guoyin Wang, and Yiran Chen. Towards building the federated gpt: Federated instruction tuning. arXiv preprint arXiv:2305.05644, 2023.
-
[26] Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, and Wei Lu. Tinyllama: An open-source small language model, 2024.
-
[27] Qingru Zhang, Minshuo Chen, Alexander Bukharin, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. Adaptive budget allocation for parameter-efficient fine-tuning. In The Eleventh International Conference on Learning Representations, 2023.
-
[28] Yue Zhao, Meng Li, Liangzhen Lai, Naveen Suda, Damon Civin, and Vikas Chandra. Federated learning with non-iid data. arXiv preprint arXiv:1806.00582, 2018.
-
[29] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric. P Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023.
A 额外实验和设置细节
环境、数据集和指标
计算资源。我们使用256GB AMD EPYC 7763 64核处理器在Linux v4.18.0上运行实验。对于所有模型的LoRA微调,我们使用4个NVIDIA RTX A6000 GPU。
Dolly数据集。Dolly数据集是一个包含15k文本样本的开源数据集,由Databricks员工生成。主题包括头脑风暴、分类、封闭式问答、生成、信息提取、开放式问答和摘要 [25]。
Alpaca数据集。Alpaca数据集包含52K指令跟随数据,用于微调Alpaca模型 [17]。该数据集被认为足够多样化,可用于微调LLMs。
Wizard数据集。我们使用的Wizard数据集是WizardLM模型的训练数据。它包括70k对指令和输出。Wizard数据集通常比其他数据集包含更复杂的指令。其微调结果通常更好,这已通过我们的实验得到证实,特别是通过MT-bench分数评估的实验。
ShareGPT数据集。ShareGPT数据集是通过ShareGPT API抓取的大约52,000个对话的集合。ShareGPT中的对话包括用户提示和ChatGPT的响应。在我们的实验中,我们将对话数据集拆分为问答对。
MMLU测试集。MMLU数据集是LLM微调中广泛使用的问答数据集。它包含57个不同主题的14,024个问题,可以评估LLMs的逻辑推理能力。我们从数据集中选择了1444个样本进行快速而全面的评估。
MT-bench评估。MT-bench是一组具有挑战性的多轮开放式问题,用于评估聊天助手 [29]。它通过使用GPT-4 API对LLM生成的对话进行评分来评估LLMs的性能。行为更像GPT-4的LLMs将获得更高的分数。
超参数细节
在我们所有的实验中,微调的学习率设置为0.0003;批量大小为128,微批量大小为16。由于选择了大数据集和模型大小,联邦微调消耗了大量的计算资源和时间。因此,我们选择了较少的微调轮次(甚至只有一轮),以确保我们能够观察到足够的数据。此外,MMLU数据集在这些大数据集上容易过拟合,导致准确率下降。因此,较少的训练轮次确保了观察到的现象的有效性。表2显示了我们选择的微调轮次和本地轮次。
\begin{table}
\begin{tabular}{c|c|c c}
\hline
\hline
Foundation & Datasets & Rounds & Epochs
\hline
\multirow{4}{}{TinyLlama} & Dolly & 3 & 1
& Alpaca & 3 & 1
& Wizard & 3 & 1
& ShareGPT & 1 & 1
\hline
\multirow{4}{}{Llama} & Dolly & 3 & 3
& Alpaca & 3 & 3
& Wizard & 1 & 1
& ShareGPT & 1 & 1
\hline
\multirow{2}{*}{Llama2} & Wizard & 1 & 1
& ShareGPT & 1 & 1
\hline
\hline
\end{tabular}
\end{table}
表2:每个实验设置中的通信轮次和本地轮次。Rounds列表示通信轮次的数量,Epochs列表示每轮中的本地微调轮次。
===== Page 13 =====
补充实验结果
将FLoRA与AdaLoRA集成 尽管数据异构性影响了秩对模型性能的影响,但所有观察结果仍然揭示了为特定任务选择适当LoRA秩的重要性。因此,一些算法如AdaLoRA [27] 被设计为自适应调整LoRA秩,以优化模型性能并节省计算资源。由于我们支持异构LoRA,我们可以灵活地利用AdaLoRA与自适应LoRA秩。我们进行了相应的实验,以证明我们可以使用AdaLoRA进一步提高联邦微调的效率。我们在每个客户端上实现AdaLoRA,以在本地微调期间调整LoRA模块。结果如表3所示。“本地秩的总和”列表示微调后所有本地LoRA秩值的总和。由于我们的FLoRA不调整秩,其值为160,与初始值相同。另一方面,AdaLoRA动态调整秩以最大化训练效果并最小化秩值以节省资源。从表3中可以看出,AdaLoRA在TinyLlama和Llama上将本地秩的总和分别从160减少到120和131。我们进一步得出结论,FLoRA+AdaLoRA可以进一步减少可训练参数的数量,同时确保与仅在客户端上使用LoRA相比具有可比甚至更好的性能。我们对这种秩调整的支持进一步证明了FLoRA方法的有效性和适用性。
Llama2的实验结果。由于Llama2固有的强大性能,QA数据集的改进并不显著。因此,我们使用Wizard和ShareGPT数据集对Llama2进行了微调。总体而言,Llama2表现出与Tinyllama和Llama相似的实验结果。表4显示了FLoRA与我们的基线之间的比较。在同构和异构设置中,Wizard和ShareGPT的MT-bench分数均超过了FedIT和零填充。至于图7中缩放因子的影响,Llama2与Llama-7b模型有相似的趋势,其中较高的缩放因子表现出更好的微调性能。
附录B 收敛性分析
在本节中,我们按照 [11] 中的标准收敛性分析展示了FLoRA的收敛性。FedAvg算法在非IID(独立同分布)数据下以 O ( 1 / T ) O(1/T) O(1/T)的速率收敛到全局最优。这种收敛基于 [11] 中提到的四个假设:
\begin{table}
\begin{tabular}{c|c|c c}
\hline
\hline
Strategy & Fine-tuning & Wizard & ShareGPT
\hline
Centralized & LoRA & 4.24 & 3.99
\hline
Homo & FedIT & 4.03 & 3.87
& FLORA & 4.22 & 3.96
\hline
Heter & Zero-padding & 4.01 & 3.70
& FLORA & 4.17 & 3.91
\hline
\hline
\end{tabular}
\end{table}
表4:在Llama2中比较FLoRA与基线。
\begin{table}
\begin{tabular}{c|c|c c}
\hline
\hline
Foundation & Fine-tuning & Sum of & MT-bench
model & algorithm & local ranks & score
\hline
\multirow{2}{}{TinyLlama} & FLORA & 160 & 3.13
& FLORA+AdaLoRA & 120 & 3.14
\hline
\multirow{2}{}{Llama} & FLORA & 160 & 4.21
& FLORA+AdaLoRA & 131 & 4.10
\hline
\multirow{2}{*}{Llama2} & FLORA & 160 & 4.17
& FLORA+AdaLoRA & 140 & 4.25
\hline
\hline
\end{tabular}
\end{table}
表3:FLoRA + AdaLoRA的性能。AdaLoRA可以减少秩,同时保持微调效果。
===== Page 14 =====
假设1。每个本地目标函数是L-平滑的,即对于所有 x x x和 y y y, F k ( x ) ≤ F k ( y ) + ( x − y ) T ∇ F k ( y ) + L 2 ∥ x − y ∥ 2 2 F_{k}(x)\leq F_{k}(y)+(x-y)^{T}\nabla F_{k}(y)+\frac{L}{2}\|x-y\|^{2}_{2} Fk(x)≤Fk(y)+(x−y)T∇Fk(y)+2L∥x−y∥22
假设2。每个本地目标函数是 μ \mu μ-强凸的,即对于所有 x x x和 y y y, F k ( x ) ≥ F k ( y ) + ( x − y ) T ∇ F k ( y ) + L 2 ∥ x − y ∥ 2 2 F_{k}(x)\geq F_{k}(y)+(x-y)^{T}\nabla F_{k}(y)+\frac{L}{2}\|x-y\|^{2}_{2} Fk(x)≥Fk(y)+(x−y)T∇Fk(y)+2L∥x−y∥22
假设3。每个客户端中随机梯度的方差是有界的: E ∥ ∇ F k ( W k ( t ) , ξ k ( t ) ) − Δ W k ( t ) ∥ 2 ≤ σ k 2 \mathbb{E}\|\nabla F_{k}(W^{(t)}_{k},\xi^{(t)}_{k})-\Delta W^{(t)}_{k}\|^{2} \leq\sigma_{k}^{2} E∥∇Fk(Wk(t),ξk(t))−ΔWk(t)∥2≤σk2 对于 k = 1 , . . . , K k=1,...,K k=1,...,K,其中 ξ k ( t ) \xi^{(t)}_{k} ξk(t)是从第 k k k个客户端随机抽样的训练数据子集。
假设4。随机梯度的期望平方范数是均匀有界的: E ∥ ∇ F k ( W k ( t ) , ξ k ( t ) ) ∥ 2 ≤ G 2 \mathbb{E}\|\nabla F_{k}(W^{(t)}_{k},\xi^{(t)}_{k})\|^{2}\leq G^{2} E∥∇Fk(Wk(t),ξk(t))∥2≤G2 对于所有 k = 1 , . . . , K k=1,...,K k=1,...,K和 t = 1 , . . . , T t=1,...,T t=1,...,T,其中 ξ k ( t ) \xi^{(t)}_{k} ξk(t)是从第 k k k个客户端随机抽样的训练数据子集。
对于FLoRA的收敛性分析,我们引入了一个额外的假设5,专门针对LoRA微调的特定动态及其与传统基于SGD的全微调的关系:
假设5。(无偏LoRA梯度)。每个客户端应用于LoRA模块的更新作为通过SGD直接在基础模型上计算的梯度的无偏估计: B k ( t + 1 ) A k ( t + 1 ) − B k ( t ) A k ( t ) = η ( t ) ∇ F k ( W k ( t ) ∣ ξ k ( t ) ) \mathbf{B}^{(t+1)}_{k}\mathbf{A}^{(t+1)}_{k}-\mathbf{B}^{(t)}_{k}\mathbf{A}^{(t)}_{k}=\eta^{(t)}\nabla F_{k}(\mathbf{W}^{(t)}_{k}|\xi^{(t)}_{k}) Bk(t+1)Ak(t+1)−Bk(t)Ak(t)=η(t)∇Fk(Wk(t)∣ξk(t))。请注意,我们定义了第 t t t轮中的模型参数为 W ( t ) \mathbf{W}^{(t)} W(t)。
定理1。基于假设1-5,我们选择 k = L μ k=\frac{L}{\mu} k=μL, γ = max { 8 k , E } \gamma=\max\{8k,E\} γ=max{8k,E}。本地学习率 α k r k = 2 μ ( γ + i ) \frac{\alpha_{k}}{r_{k}}=\frac{2}{\mu(\gamma+i)} rkαk=μ(γ+i)2。然后,我们可以推导出FLoRA中的微调误差的期望可以界定为:
δ ( T ) ≤ 2 k γ + T ( M μ + 2 L ∥ W ( 1 ) − W ∗ ∥ 2 ) , \delta^{(T)}\leq\frac{2k}{\gamma+T}(\frac{M}{\mu}+2L\|\mathbf{W}^{(1)}-\mathbf{W}^{*}\|^{2}), δ(T)≤γ+T2k(μM+2L∥W(1)−W∗∥2),
其中 δ ( T ) \delta^{(T)} δ(T)是第 T T T轮中的微调误差。 δ ( T ) \delta^{(T)} δ(T)和 M M M定义如下:
δ ( T ) = E [ F ( w ( T − 1 ) + B ( T ) A ( T ) ) ] − F ∗ , M = ∑ k = 1 K p k γ σ k 2 + 6 L I + 8 ( E − 1 ) 2 G 2 . \begin{split} \delta^{(T)}&=\mathbb{E}[F(\mathbf{w}^{(T-1)}+\mathbf{B}^{(T)}\mathbf{A}^{(T)})]-F^{*},\\ M&=\sum_{k=1}^{K}p_{k}^{\gamma}\sigma_{k}^{2}+6LI +8(E-1)^{2}G^{2}. \end{split} δ(T)M=E[F(w(T−1)+B(T)A(T))]−F∗,=k=1∑Kpkγσk2+6LI+8(E−1)2G2.
其中 L , μ , σ k , L,\mu,\sigma_{k}, L,μ,σk,和 G G G由假设1-4定义。 Γ \Gamma Γ定义为 Γ = F ∗ − ∑ k = 1 K p k F k ∗ \Gamma=F*-\sum_{k=1}^{K}p_{k}F_{k}^{*} Γ=F∗−∑k=1KpkFk∗,用于量化非iid的程度。该定理认为,随着轮次 T T T趋近于无穷大,微调误差 δ ( T ) \delta^{(T)} δ(T)的期望收敛到零。相比之下,FedIT偏离了FedAvg模型更新规则,如公式2所示,通过其平均过程引入了非梯度噪声。因此,它未能以 O ( 1 / T ) O(1/T) O(1/T)的速率实现收敛。虽然这种偏离并不否定FedIT在联邦微调中的实用性,但它显著损害了其收敛速度和整体有效性。
附录C 局限性
我们的方法有一个局限性,即服务器向客户端发送堆叠的LoRA模块,从而增加了通信成本。我们在第3节和第4节中分别从理论上和实验上讨论了这一局限性。我们相信,在提高微调效果和加速收敛的前提下,通信开销的增加是可以接受的。此外,由于计算资源和时间的限制,我们仅在实验部分使用了Llama模型。我们希望在未来的研究中观察不同类型LLM联邦微调的实验现象,并得出更普遍的规律。
[文件内容结束]

















 1109
1109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









