






最近公司做一个目标检测相关的项目,对目标检测以及相关的深度学习知识有一些了解。这里整理一下。
一、目标检测定义
什么是目标检测?最近还碰到一个朋友做的项目,是无人机目标检测的,很有意思(据说还是军事用途),主要是协助雷达能快速的识别出无人机,无人机在可见视野中其实是比较小的,而且数据源是多桢实时信号,要很快的准确的识别出来,实际上有一定难度的。我问了对方,对方使用的方案是YoLoV8,硬件有用到RK的芯片,也有GPU的NVIDA的芯片。
然后公司接了一个工业相机的目标识别项目,涉及到二维码检测的,需要部署到FPGA上,但是,一切还是从应用层的AI模型开始。所以,详细了解了一些知识。具体我们还是从头说起:
1.1:需要解决的问题
就如下图,目标检测一般解决几个问题:图像分类(需要检测哪些图像),目标定位(图像在哪里?),目标检测(确认是什么?)

1.2:涉及的众多应用
目标检测的项目还是挺多的,罗列一些我了解到的项目:
1:输油管道防挖机的检测,如果有挖掘机靠近,会报警/警示 。(这是一个真实的项目,好像还是针对俄罗斯到中国的输油管道的工程)。
2:智能牧场检测是否有牛靠近,如果靠近到一定位置,喷水为牛降温。这也是真实项目,我一个同学正在做的项目,他们提供完整解决方案和产品定制。
3:物流货品智能录入,传送带上的货品检测二维码,识别后入库。这是工业相机的应用,我司正在做的。
4:仓库流水审计。银行需要监管仓库货物检测,明确仓库内的价值。
5:无人售货(货柜检测),新零售。
6:仓库盘点(立体仓库),可以无人盘点。摄像头移动拍摄。识别标签和内容。
7:安全防护检测,安全检测(有没有合规操作)(发短信通知)。
8:内容审核(暴恐)
9:车流统计。驶入,驶出,当前画面的车辆统计。
10:无人车场景
应该还有很大,大类都属于机器视觉领域。
二、目标检测的评估
目标检测如何评估质量,有一些重要的指标,特别是 mAP,很多人并没有搞得很清楚,这里重点说明一下:
2.1: 先了解什么是 IOU

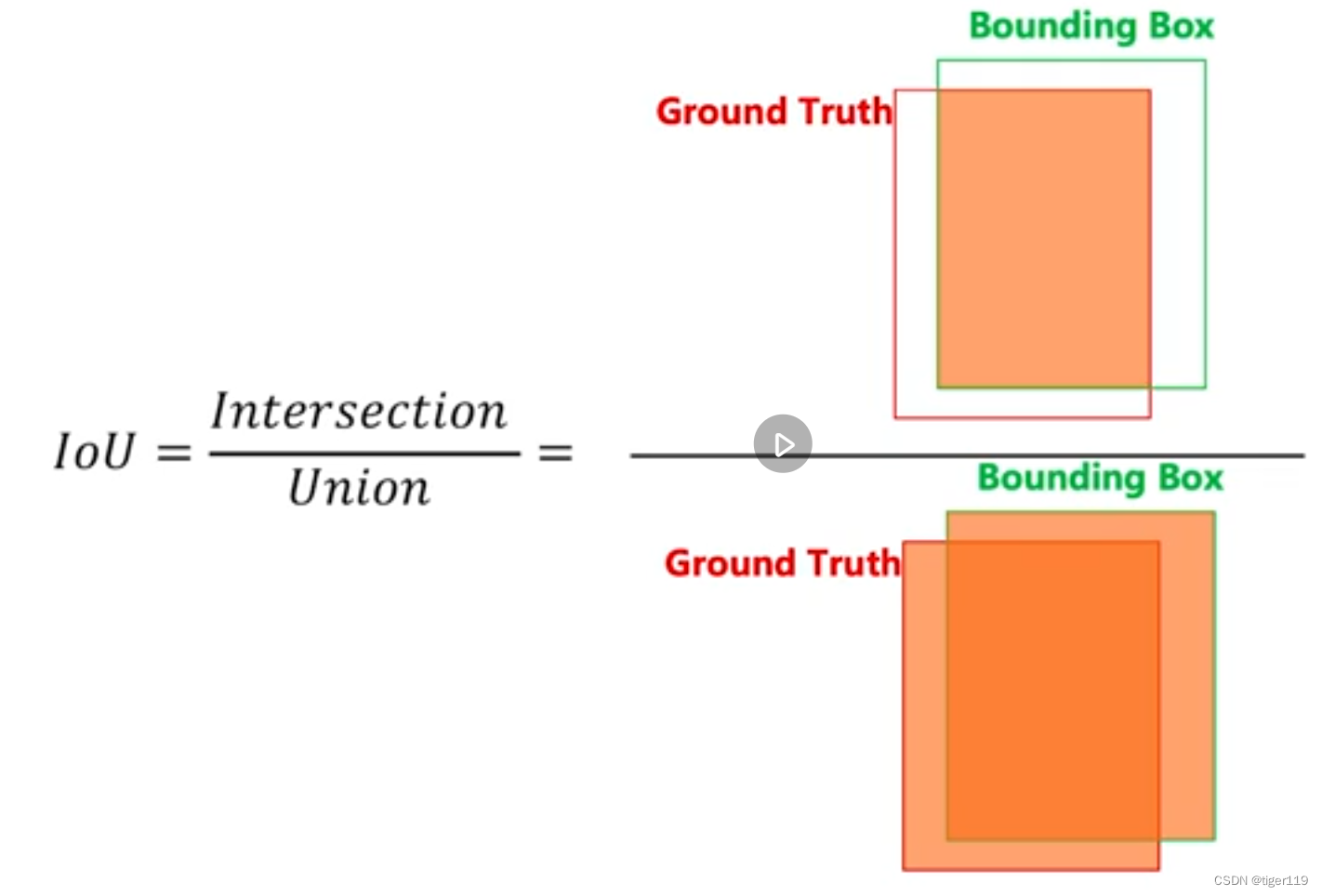
IoU:实际上就是交并比,目标就是IoU最好接近于1。
如果 IoU接近 1,是最好的效果。如果只是为了把物品框住,可以把框框搞得很大,但仍然不会是很好的数据(因为交并集的值不高)。如果是0,那就是完全没有预测正确。
2.2:相关指标
另外一些重要的衡量指标:首先确定IoU的阀值,比如:我们认为大于0.9是正确。基于这个0.9 我们再来谈下面的指标。
TP:预测正确的物品数(True positive)
预测是狗,确实是狗。
TN:True negative
预测是狗,其实不是。
这个值很奇怪,一般是不用的。意思是固定位置不是目标,我们确实也没把它当成目标,这个不是很好理解,也没啥用处。
FP:错误测试的数量(False positive)
预测是狗,但实际上并不是狗。
FN:被漏检测的物品数量(False negative)
有N只狗,没有被检测出来。
Precision(准确率)
TP / (TP + FP)—— 所有检测的物品的正确率
Recall(召回率)
TP / TP + FN —— 有多少被正常检测出来了(漏掉了多少)
很显然,准确率和召回率是很重要的两个指标,但两者是不同的(两者会有矛盾),很多情况下是两个需要均衡的值,你可以使得召回率很高,但代价可能是准确率下降。同理,你可以把准确率做得很高,但召回率可能很低(有一丝错的可能都不检测)。所以,我们需要找到两者的一均衡点,这就要提到AP值 。
AP(均衡精度)(如下图)
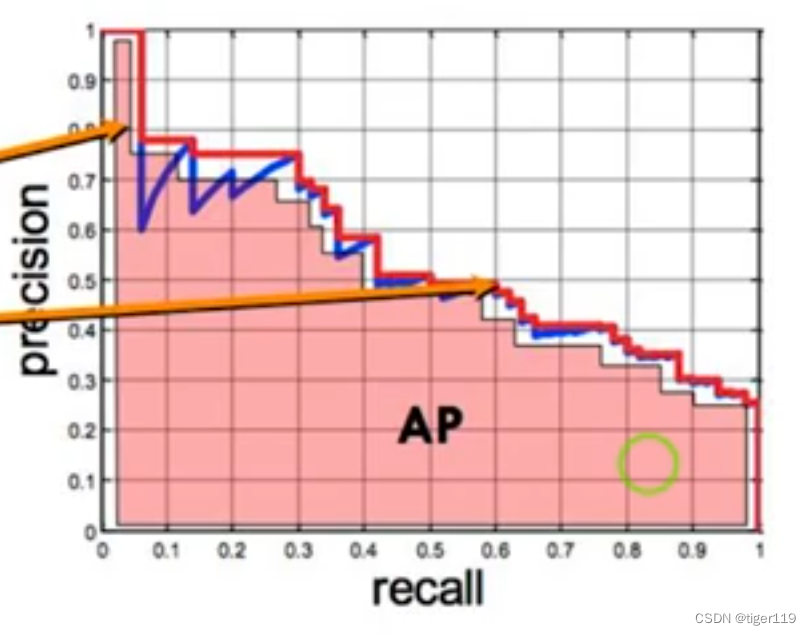
注意;一定要基于IOU的值,还要基于类别。两者都有阀值。(类别仍然是根据概率来确定的)
mAP:目标检测的综合指标
从上图也可以看出,两者的关系。所以,我们有一个更合适的评估:
mAP(Mean Average Precision)是衡量目标检测算法性能的一个重要指标。它综合了多个类别的检测精度和召回率,是评估目标检测模型在整个数据集上表现的常用方法。
具体 计算 mAP 的步骤
-
计算每个类别的 Precision-Recall 曲线:
- Precision(精度): 正确检测到的目标数量(True Positives, TP)占所有检测到的目标数量(TP + FP)的比例。
- Recall(召回率): 正确检测到的目标数量(TP)占所有实际存在的目标数量(TP + FN)的比例。
-
计算每个类别的 Average Precision (AP):
- AP 是 Precision-Recall 曲线下面积的平均值。
- AP 通常通过在 Recall 变化的不同点取 Precision 值并求平均来计算。
-
计算 mAP:
- 对所有类别的 AP 取平均值。
mAP@0.5
mAP@0.5 是指在 IoU(Intersection over Union)阈值为 0.5 的情况下计算的 mAP。IoU 是衡量预测框与真实框重叠程度的指标,定义为预测框与真实框交集面积除以并集面积。IoU 为 0.5 意味着预测框和真实框的重叠面积至少占并集面积的一半。
mAP@0.5:0.95
mAP@0.5:0.95 是指在 IoU 阈值从 0.5 到 0.95(步长为 0.05)的多种情况下计算的 mAP 的平均值。它考虑了更高的 IoU 阈值,对模型的检测精度要求更高。
mAP@0.5 更适合初步评估和低精度要求的任务,而 mAP@0.5:0.95 更适合全面评估和高精度要求的任务。
上面指标计算和理解都很简单,但非常重要。
三、目标检测的技术原理:
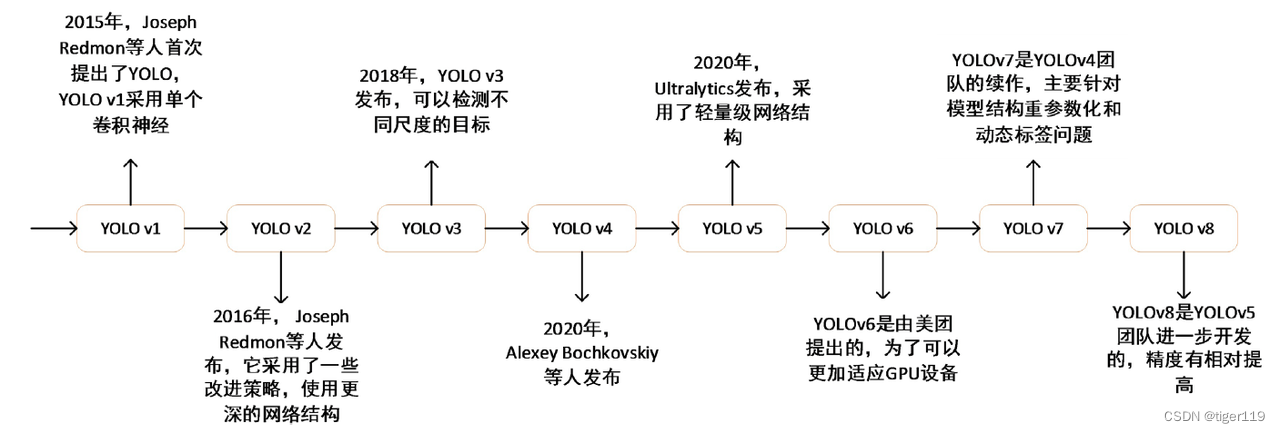
3.1:技术历史
说到技术原理,太旧的技术我们就不提了,只提最新的技术,旧的技术线路图,有兴趣的同学可以自行研究,如下图:

3.2:深度学习技术
从2012年开始,使用深度学习完成目标检测。(解决人做特征工程的事情,变成机器自动生成)
通用的技术分类
方法一:One-stage
以YoLo,SSD,Retina-Net 为主,回归位置和类别做为同一个任务来完成。特点是速度很快,可以做为工业落地使用。Retina-Net 的特点解决样本平衡的,多尺度学习等……
方法二:Two-stage
RCNN为主,拆成2个阶段,一个是做框(定位),一个是做分类。分别训练2个模型,一阶段找侯选框,二阶段进行分类。AnchBox,FeatureFusion概念。
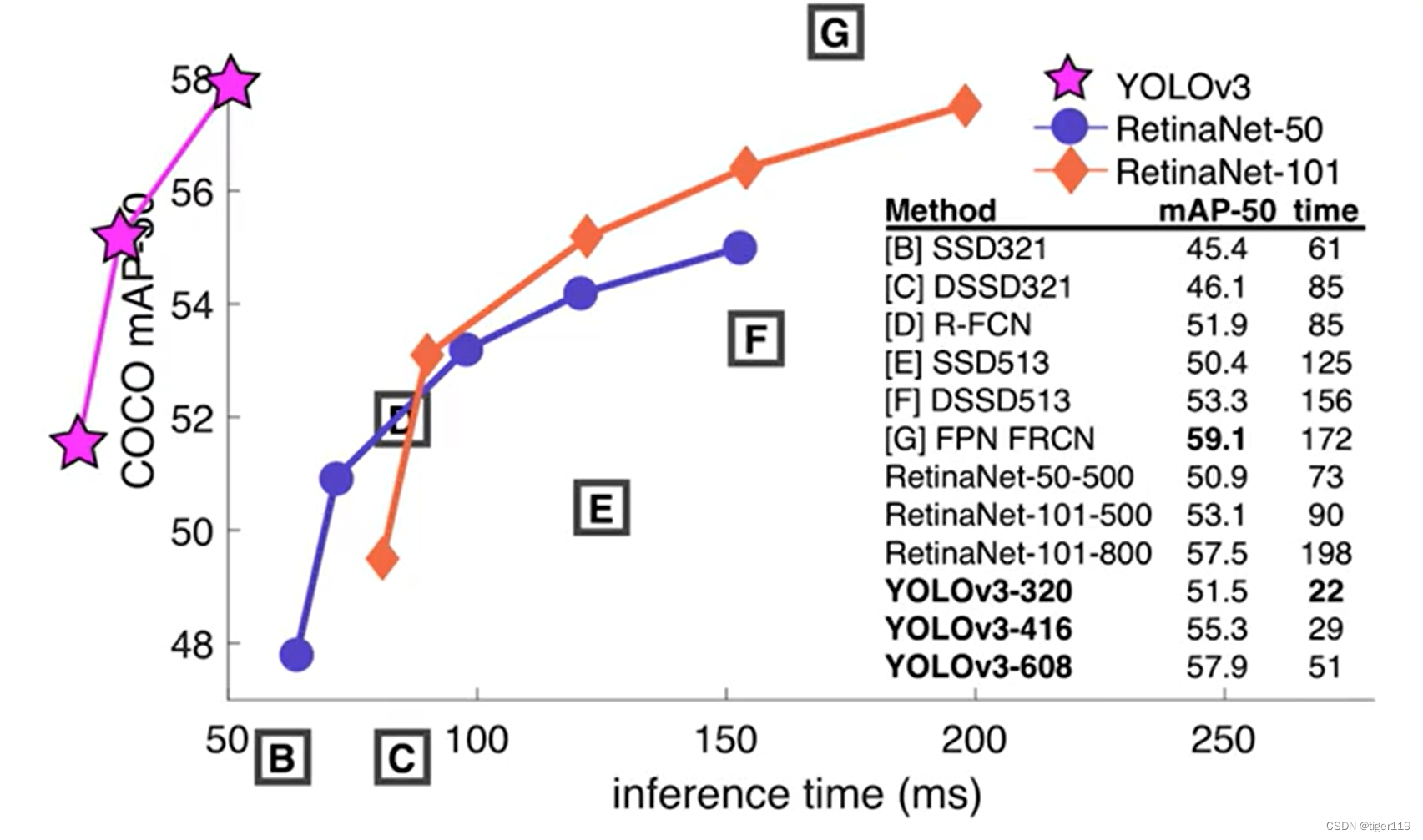
从下图可以比较不同模型的效果:
Faster RCNN的精度最高,但速度慢。用在高精度场景
YoLo的速度不错,精度一般。用在实时的工业场景

两阶段的模型
RCNN模型(两阶段)

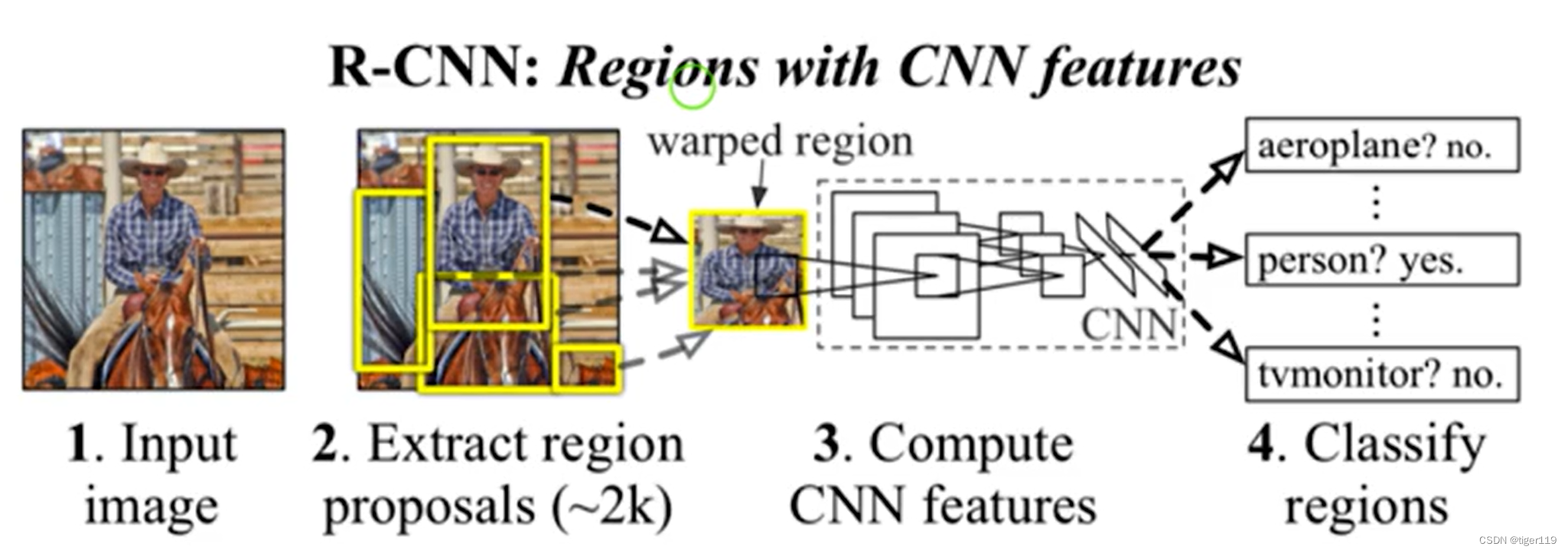
第一步:选择锚框——启发式搜索选择(这个启发式搜索很复杂,这里就不详细讲解了,算是一种老式的选择算法)。Selective Search(可以给出选择框)。
第二步:对每个锚框抽取feature,直接通过CNN抽取。存储到硬盘(量太大)
第三步:训练SVM模型(支持向量机,一种监督学习算法实现分类和回归任务),完成分类。
第四步:训练线性回归模型来预测边缘框的偏移。
特点:非常的慢,运算量太大。
Fast RCNN:
针对RCNN进行增强,不对每个锚框进行特征提取,而是针对整图进行抽取,节省重复区域的抽取任务。训练时使用并行任务方式提供2个loss函数完成分类和边缘定位。

Faster RCCN:
使用 一个RPN的网络来替换启发式检索。(选出侯选框的方法)
另外,可以针对不同尺寸进行训练,检测器可适应不同的图。
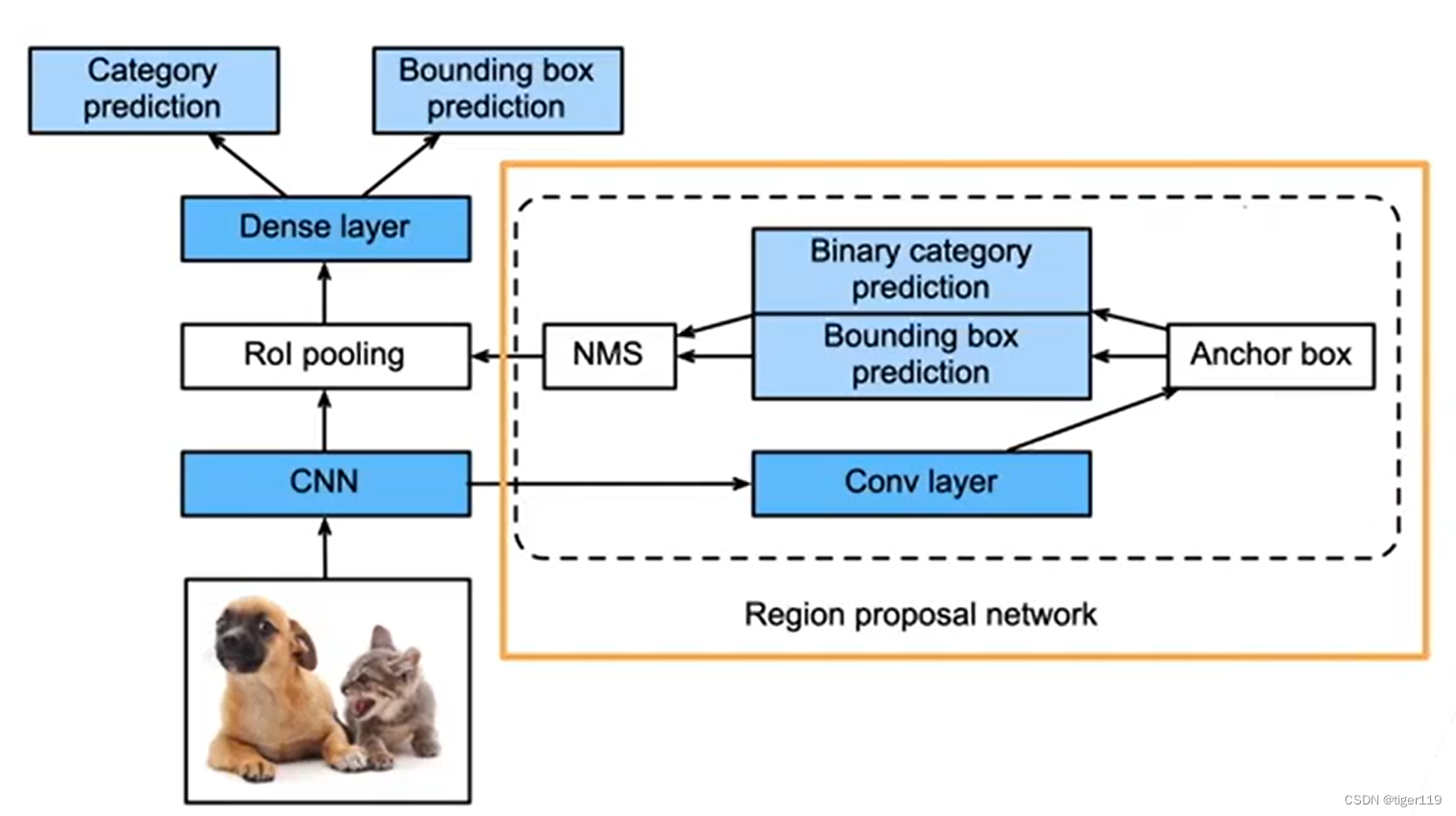
Mask R-CNN:
如果有像素级的标号,可以使用FCN来利用这些信息,可提升性能。

单阶段模型
SSD 单发多框检测:
只做一次预测,单阶段处理。

第一步:针对单个像素生成,不同大小,不同高宽比的多个锚框。上图只是一个分辨率(4*4),正常应该要取很多个分辨率,用于检测不同大小的特体。
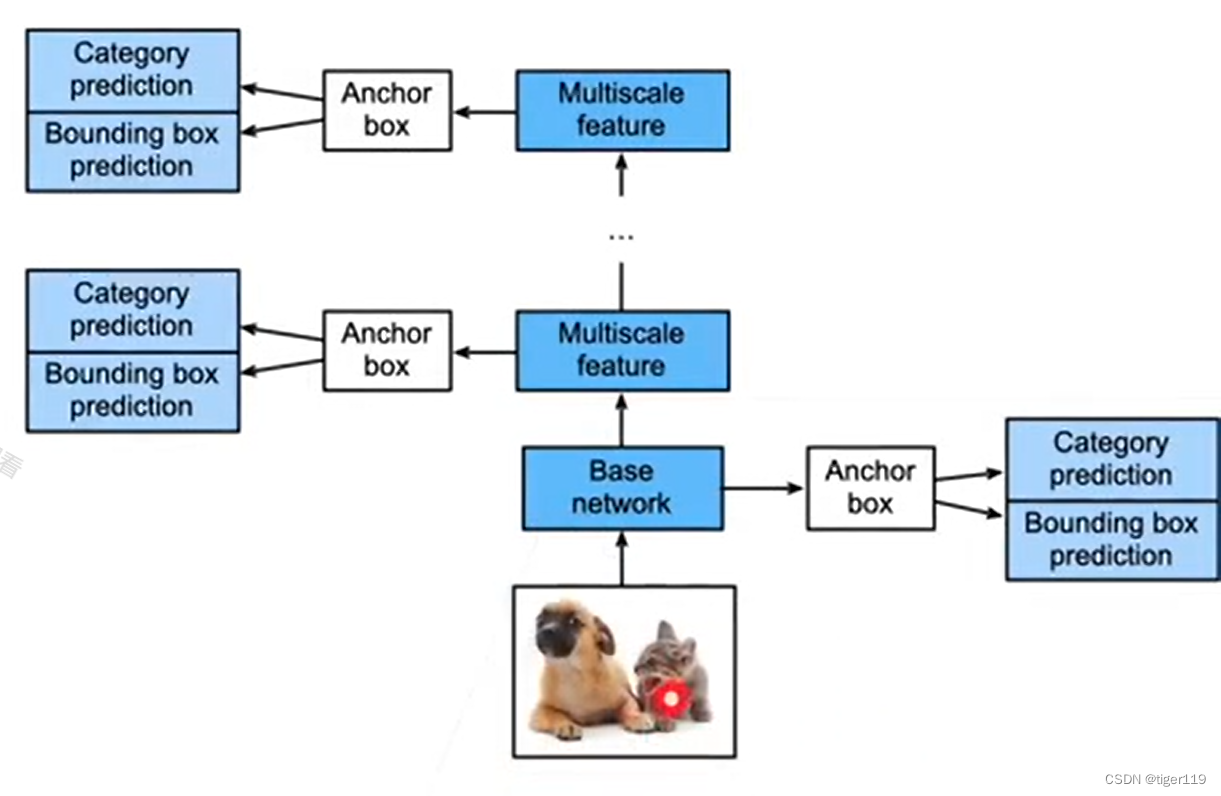
直接对锚框进行检测,产生的锚框会非常的多,有大的,小的,会用于检测不同的样式,可以直接预测,不再需要分阶段处理。
SSD很快,但是精度不是很好。原因是:很早的模型,之前不再维护。需要持续维护。SSD的作者不再继续做。对后面的任务有很多启发。这个相对比较简单(相比RCNN)
SSD的实现其实很简单,自已也可以用python来写代码实现,当然,它的精度并不是很好(并且用python速度不行)。
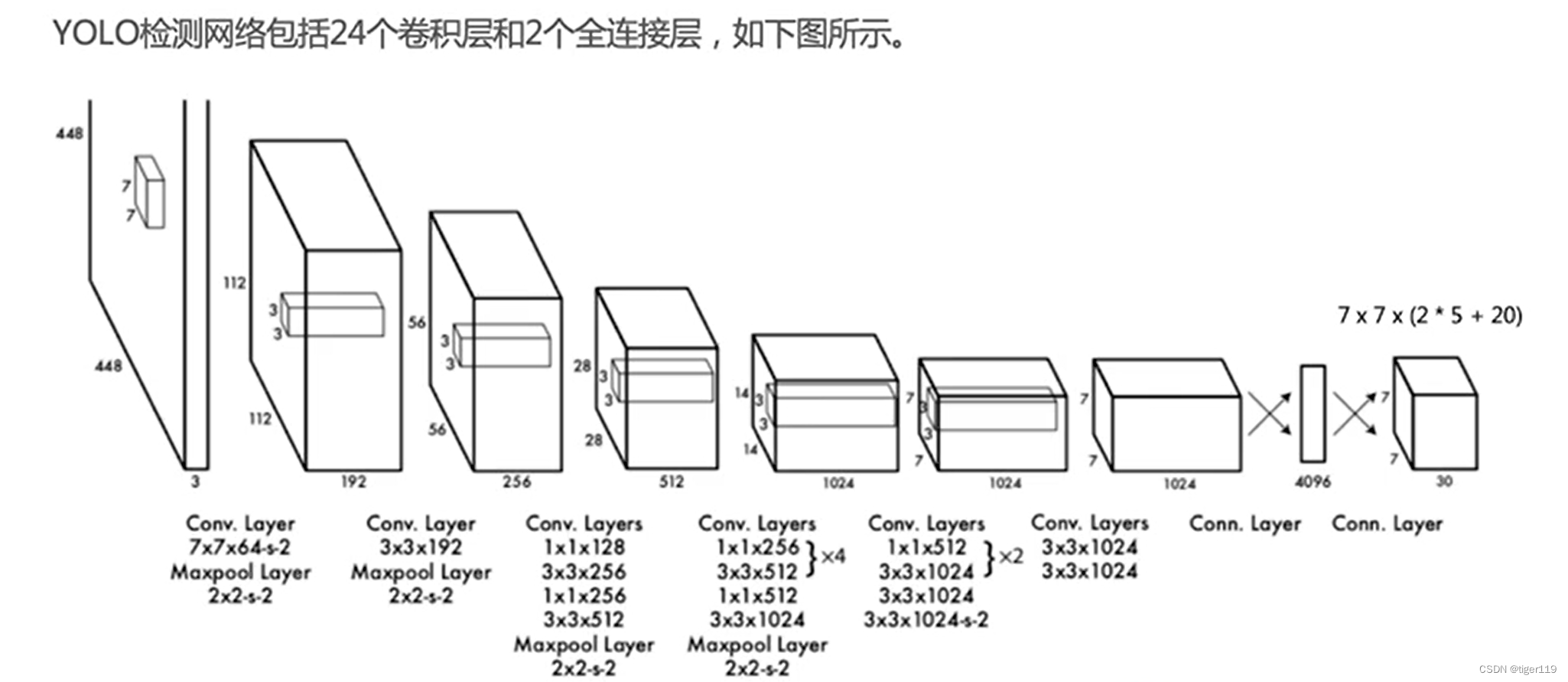
YOLO模型:(只需要看一次)
把两阶变成了一个也是阶段。单阶段检测。
和RCNN的比较:

三个步骤:
1:变成特定尺寸的图像(进行Resize)。进行固定格子的划分,切成若干格。将图均分为S * S。锚框不重桑。

2:检测某个物体是否有落在某个格子内。格子需要检测出某个物体。
每个格子都有一个值,标明是什么类别?对多个类别的概率值(相加为1)
每个格子还有一个置信度(不同分类的概率)
YOLO重要的输出向量:S * S * (B * 5 + C)
S:是分拆的格式数
B:预测多少个框,这个在不同版本有不同的定义,对于Yolo3是3个边框,这里预测多个,应该是为了预测一些小目标。
5:包括位置(4个)和框框的置信度。
C:分类的数量。每种分类都有各自的概率值。
3:NMS处理预测结果,主要是要减少重复检测的准确性。

YoLo的精度要高于SSD,实时性远超 RCNN。
YoloV1
缺点:对于靠得很近的物体会有问题。同一类物体如果大小有很大的不同,可能泛化会有问题。很大和很小的物品检测会有问题(召回率有问题)。(不适合货架,新旧物品外形相同大小不同)
优点:检测非常的快(1秒是45张),背景误检率比较低,通用性比较强(不同类型的物品)位置的精准度比较差,会产生漏检。
YoLoV2
速度更快,准确率更高。添加了一些小的技巧(具体技巧见下表)
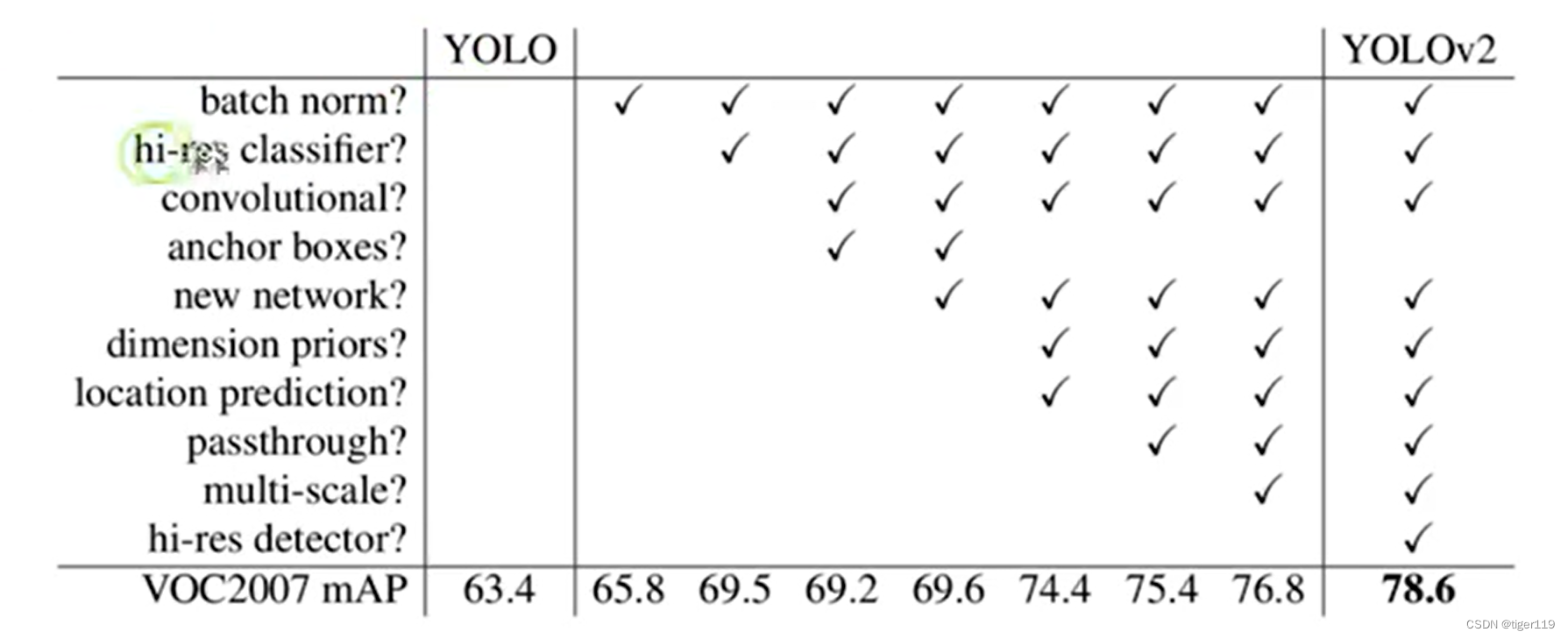
新的网络结构:Darknet-19
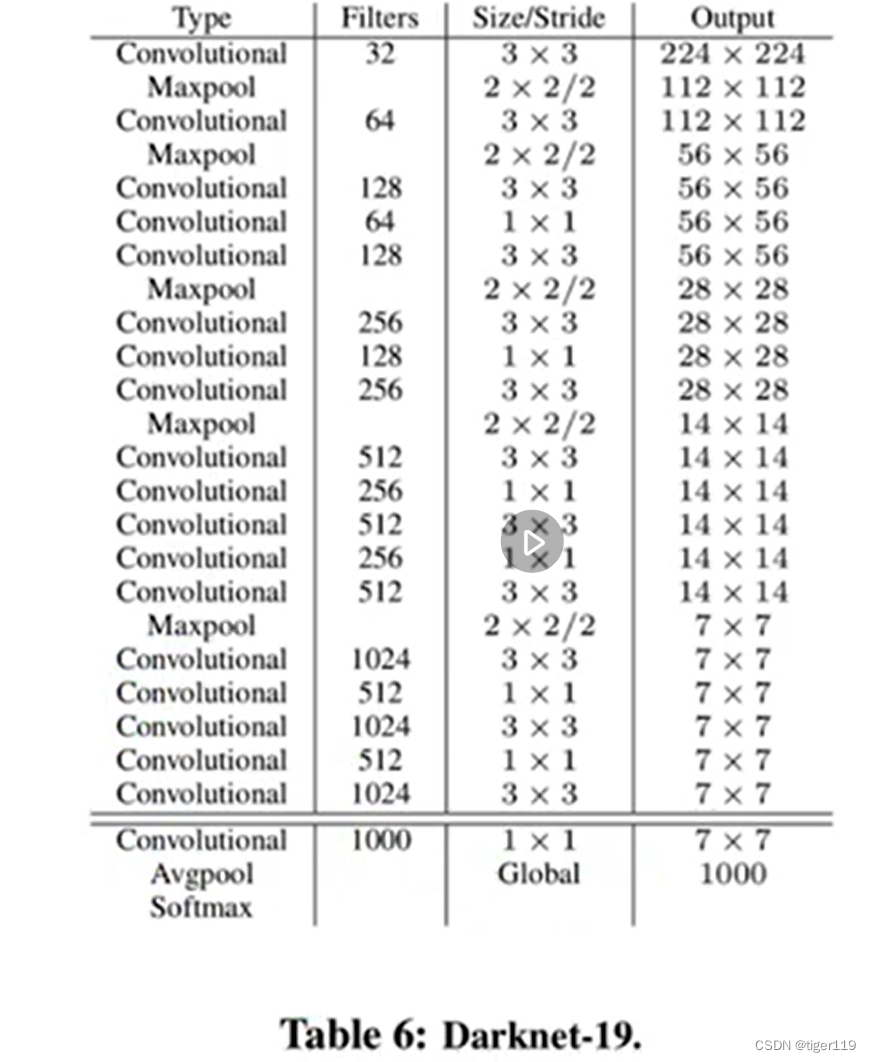
特别注意:引入了锚点(Anchors)概念,提高小目标检测能力。
YoLoV3
增加了多级预测,多个Detection针对不同大小的检测。可以支持多个分辨率的输入。
使用Darknet-53卷积神经网络来提取特征,通过调整模型结构和大小,可提升算法精度和速度,网络结构更复杂,对设备要求高。
解决了小目标检测的问题。达到工业级高性能的目标检测器。
Yolo 其它
V3之后,原作者就不做了,后续版本都是非原作者的扩展版本。
YoloV4:主要是增强边框的预测。引入特征提取器(CSPDarknet53)、数据增强等技术。主要还是应用在监控,自动驾驶的领域。
YoLoV5:简化了配置和训练的流程。适用于快速配置和部署的任务。性能应该是不如V4的版本。
YoLoV6:主要是对主干网络和检测头进行了优化。适用于高效率和高准确度的场景。模型更小,推理速度更快,对小型设备的适用性较强。适合于实时推理的场景。我司的FPGA场景选用了这个版本。
YoLoV7:改进了模型结构,引入了EfficientNet作为新的主干网络。准确度进一步提升,易于部署。但在处理极低分辨率时,存在问题。
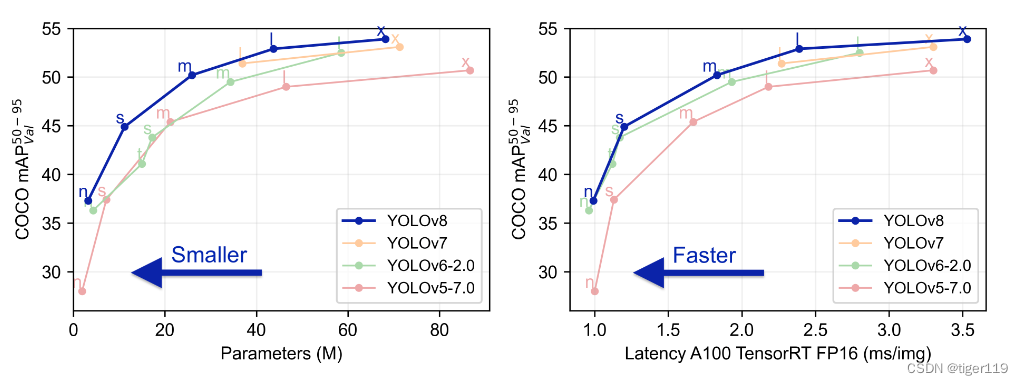
YoLoV8:基于YoloV5的扩展,性能和精准度更高,支持更多的优化技术,如自适应锚框,自定义损失函数等。
| 算法 | 作者 | 发布/创建时间 | 公司/实验室 |
| YOLOv1 | Joseph Redmon | 2016.05.09 | 华盛顿大学艾伦研究所Facebook实验室 |
| YOLOv2 | Joseph Redmon | 2015.12.25 | 华盛顿大学艾伦研究所 |
| YOLOv3 | Joseph Redmon | 2018.04.08 | 华盛顿大学 |
| YOLOv4 | Alexey Bochkovskiy Chien-Yao Wang | 2020.04.23 | 中国台湾中央信息研究所 |
| ScaledYOLOv4 | Chien-Yao Wang Alexey Bochkovskiy | 2021.06 | 中国台湾中央信息研究所 |
| YOLOv5 | Glenn Jocher | 2020.06.26 | Ultralytic公司 |
| YOLOX | Zheng Ge | 2021.08.18 | 旷视科技 |
| YOLOR | Chien-Yao Wang | 2021.10.03 | 中国台湾中央信息研究所 |
| YOLOv6 | Chui Li | 2022.06.23 | 美团 |
| YOLOv7 | Chien-Yao Wang | 2022.07.07 | 中国台湾中央信息研究所 |
| YOLOv8 | Glenn Jocher | 2023 | Ultralytic公司 |
RetinaNet 模型:
适合于密集排列的场景(比如:货架物品的检测)
出现了RCNN和Yolo之后的改进方案。哪些场景可能会有问题:
1:正负样本不平衡。对于RCNN的负样本较多(侯选框太多)。对于YoLo的侯选框也是非常的多。
新的损失函数:Focal Loss

这个比R-CNN中抽样的方式更好。
2:解决类别不平衡的问题。
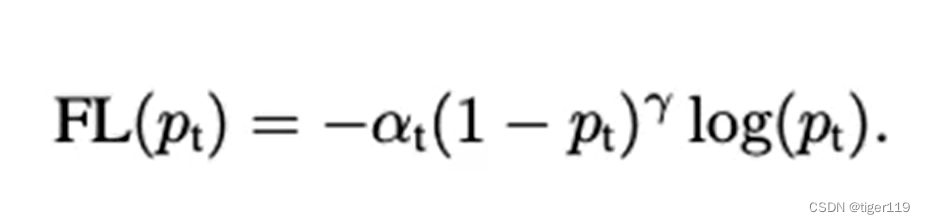
结合1的处理,形成上述的 Focal Loss
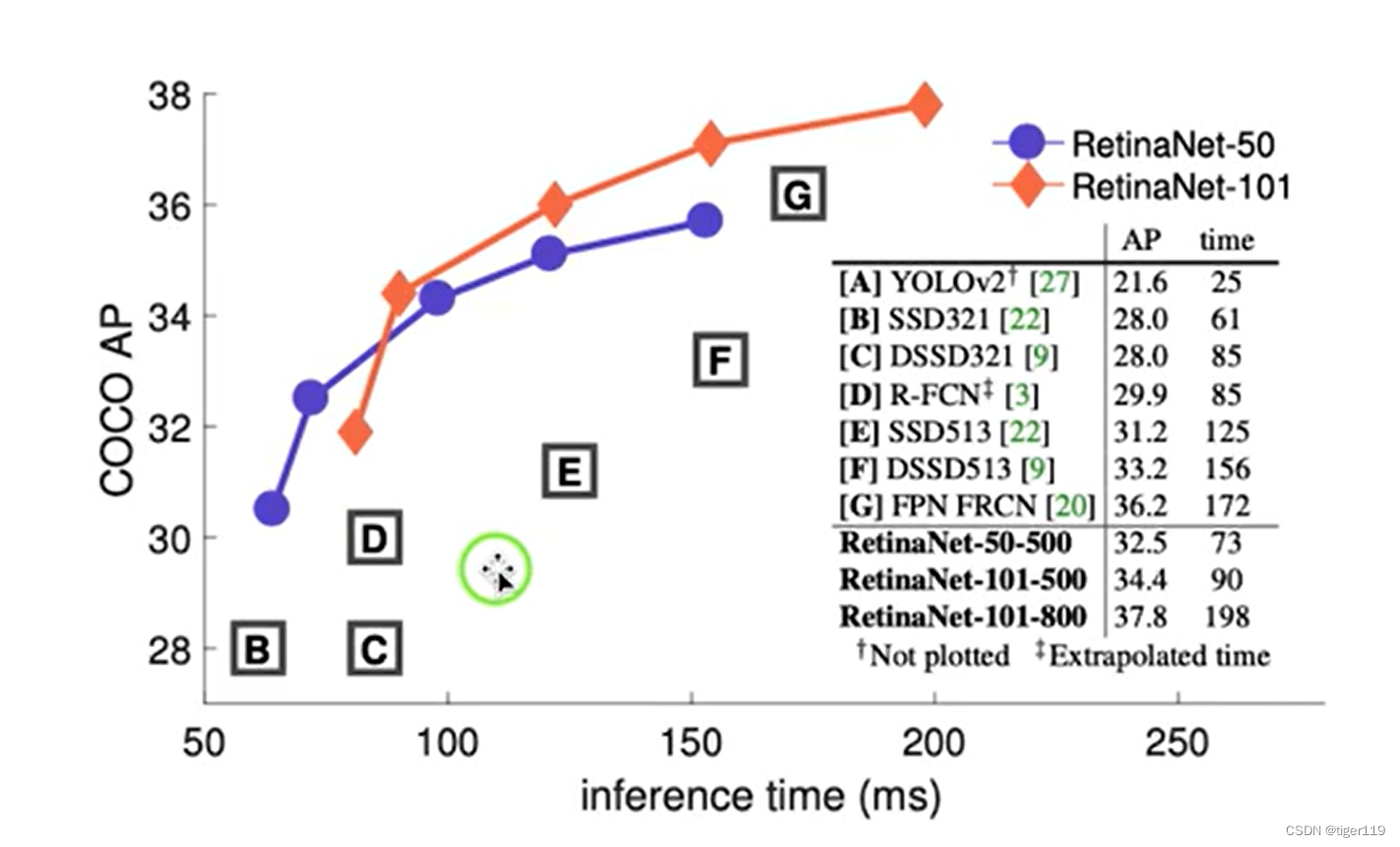
RetinaNet的性能比较:
网络结构:

四、目标检测模型效果影响:

五、数据标注
可以使用开源的工具来手工标注。这对于小规模的训练数据准备是够了。
如:LabelImg
安装方法:pip install labelImg

六、数据增强
对于数据,肯定会存在不够的情况,所以,我们必须要对已有数据做增强,常见的增强方法有:
图像翻转:

图像切割:(随机高宽比,随机大小,随机位置)

改变颜色:明亮度,色调

可以使用PhotoShop的一些功能,做更多的处理(当然,要结合实际的场景)
以上图像增广的代码,都是比图简单的,可以使用Pytorch来简单完成。
七:常用数据集

Pascal VOC:

Coco数据集:

对于复杂图像比较好用。主要指标是 AP值
ImageNet LSVRC

有一些训练好的模型,可以基于已有模型做迁移学习。
八:目标检测模型在FPGA上部署
对于AI模型在FPGA上部署,实际上是可行的。无非是在算力和空间上需要支持,还有就是FPGA不建议浮点运算,需要转成INT8定点运行。
第一步:模型选型
对于YOLO的模型,有针对受限设备的,比如:YoLoV6-lite S

YoloV6目前在Coco 2017 val的第一名:

对于YoLoV8,准确度会更高,基于单分类的数据如下(因为我们的项目只需要针对二维码进行定位):
| P | R | mAP50 | mAP50-95 | Inference time | Para | Size | |
| YOLOv8n | 0.99 | 0.995 | 0.994 | 0.974 | 2.0ms | 3.2M | 6.0MB |
| YOLOv6Lite-S | 0.94 | 0.963 | 0.987 | 0.948 | 1.4ms | 0.55M | 1.5MB |
| YOlOv5s | 0.894 | 0.865 | 0.927 | 0.8 | 2.2ms | 7.2M | 14.3MB |
综合以上情况,我们选用YoLoV6 Lite-S作为原始模型。
第二步:模型量化
采用PTQ方式,对YoLov6Lite-S的模型进行量化。
CUDA_VISIBLE_DEVICES=0 python tools/train.py \
--data ./data/coco.yaml \
--output-dir ./runs/opt_train_v6s_ptq \
--conf configs/repopt/yolov6s_opt_qat.py \
--quant \
--calib \
--batch 32 \
--workers 0
如何使用 QAT的实现方式。
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python -m torch.distributed.launch --nproc_per_node=8 \
tools/train.py \
--data ./data/coco.yaml \
--output-dir ./runs/opt_train_v6s_qat \
--conf configs/repopt/yolov6s_opt_qat.py \
--quant \
--distill \
--distill_feat \
--batch 128 \
--epochs 10 \
--workers 32 \
--teacher_model_path ./assets/yolov6s_v2_reopt_43.1.pt \
--device 0,1,2,3,4,5,6,7
下面是官方的数据(我司的数据就不贴了)
| Model | Size | Precision | mAPval 0.5:0.95 | SpeedT4 trt b1 (fps) | SpeedT4 trt b32 (fps) |
|---|---|---|---|---|---|
| [YOLOv6-S RepOpt] | 640 | INT8 | 43.3 | 619 | 924 |
| [YOLOv6-S] | 640 | FP16 | 43.4 | 377 | 541 |
| [YOLOv6-T RepOpt] | 640 | INT8 | 39.8 | 741 | 1167 |
| [YOLOv6-T] | 640 | FP16 | 40.3 | 449 | 659 |
| [YOLOv6-N RepOpt] | 640 | INT8 | 34.8 | 1114 | 1828 |
| [YOLOv6-N] | 640 | FP16 | 35.9 | 802 | 1234 |
在量化时,如果版本不对,需要先变成RepOpt版本。
第三步:模型剪枝
通过结构化剪枝,结构化剪枝的标准方法。(非结构化剪枝的收益不大)
具体的结构化剪枝的方法,没有规律,此处略(后面有时间单独讨论)。主要是参考了开源项目YoloV8-pruning的实现。
第四步:FPGA算子实现
标准算子实现:conv,concat,mul,slice,softmax等的实现
对于FPGA中工作流的控制以及算子实现,如何利用DSP,BRAM,DDR,在这里就不细讲,后面可以单独总结。这个并不难,主要是工作量。
其它:重要工具使用
ONNX转换:
python3 qat_export.py --weights yolov6s_v2_reopt_43.1.pt --quant-weights yolov6s_v2_reopt_qat_43.0.pt --graph-opt --export-batch-size 1
使用netron工具:
使用工具,直接打开ONNX格式的模型文件即可。
使用 TensorRT工具:(build TRT engine)
trtexec --workspace=1024 --percentile=99 --streams=1 --int8 --fp16 --avgRuns=10 --onnx=yolov6s_v2_reopt_qat_43.0_bs1.sim.onnx --calib=yolov6s_v2_reopt_qat_43.0_remove_qdq_bs1_calibration_addscale.cache --saveEngine=yolov6s_v2_reopt_qat_43.0_bs1.sim.trt
使用TrnsorRT可以查看推理阶段的主要性能损耗。















 3040
3040











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









