







import tensorflow as tf
import numpy as np
import pandas as pd
train = pd.read_csv('../Datasets/Breast-Cancer/breast-cancer-train.csv')
test = pd.read_csv('../Datasets/Breast-Cancer/breast-cancer-test.csv')
X_train = np.float32(train[['Clump Thickness','Cell Size']].T)
y_train = np.float32(train['Type'].T)
X_test = np.float32(test[['Clump Thickness','Cell Size']].T)
y_test = np.float32(test['Type'].T)
#定义一个tensorflow的变量b作为线性模型的截距,同时设置初始值为 1 0
b = tf.Variable(tf.zeros([1]))
#定义一个tensorflow的变量w作为线性模型的参数,并设置初始值为-1.0至1.0之间均匀分布的随机数
W = tf.Variable(tf.random_uniform([1,2],-1.0,1.0))
#显示定义这个线性函数
y = tf.matmul(W,X_train)+b
#使用tensorflow中的reduce_mean 取得训练集上均方误差
loss = tf.reduce_mean(tf.square(y-y_train))
#使用梯度下降法估计参数W, b,并且设置迭代步长为0.01,这个与Scikit-learn中的SGDRegressor类似D
optimizer = tf.train.GradientDescentOptimizer(0.01)
#以最小二乘损失为优化目标
train = optimizer.minimize(loss)
#初始化所有变量
init = tf.initialize_all_variables()
#开启tensorflow中的会话
sess = tf.Session()
sess.run(init)
#迭代1000轮次,训练参数
for step in range(0,1000):
sess.run(train)
if step % 200 == 0:
print(step,sess.run(W),sess.run(b))
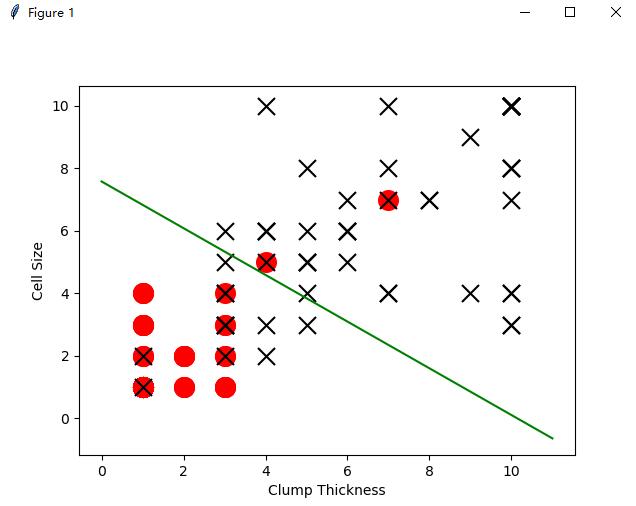
test_negative = test.loc[test['Type'] == 0][['Clump Thickness','Cell Size']]
test_positive = test.loc[test['Type'] == 1][['Clump Thickness','Cell Size']]
#以最终的参数作图
import matplotlib.pyplot as plot
plot.scatter(test_negative['Clump Thickness'],test_negative['Cell Size'],marker='o',s=200,c='red')
plot.scatter(test_positive['Clump Thickness'],test_positive['Cell Size'],marker='x',s=150,c='black')
plot.xlabel('Clump Thickness')
plot.ylabel('Cell Size')
lx = np.arange(0,12)
ly = (0.5-sess.run(b)-lx*sess.run(W)[0][0])/sess.run(W)[0][1]
plot.plot(lx,ly,color='green')
plot.show()
效果图如下















 2210
2210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









