







目录
神经网络-搭建小实战和Sequential的使用
torch.nn.Sequential的官方文档地址,模块将按照它们在构造函数中传递的顺序添加。- 代码实现的是下图:

版本1——未用Sequential
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
# 3,32,32 ---> 32,32,32
self.conv1 = Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2)
# 32,32,32 ---> 32,16,16
self.maxpool1 = MaxPool2d(kernel_size=2, stride=2)
# 32,16,16 ---> 32,16,16
self.conv2 = Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2)
# 32,16,16 ---> 32,8,8
self.maxpool2 = MaxPool2d(kernel_size=2, stride=2)
# 32,8,8 ---> 64,8,8
self.conv3 = Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2)
# 64,8,8 ---> 64,4,4
self.maxpool3 = MaxPool2d(kernel_size=2, stride=2)
# 64,4,4 ---> 1024
self.flatten = Flatten() # 因为start_dim默认为1,所以可不再另外设置
# 1024 ---> 64
self.linear1 = Linear(1024, 64)
# 64 ---> 10
self.linear2 = Linear(64, 10)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
model = Model()
print(model)
input = torch.ones((64, 3, 32, 32))
out = model(input)
print(out.shape) # torch.Size([64, 10])
版本2——用Sequential
代码更简洁,而且会给每层自动从0开始编序。
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.model = Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2, stride=2),
Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2, stride=2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2, stride=2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
return self.model(x)
model = Model()
print(model)
input = torch.ones((64, 3, 32, 32))
out = model(input)
print(out.shape) # torch.Size([64, 10])
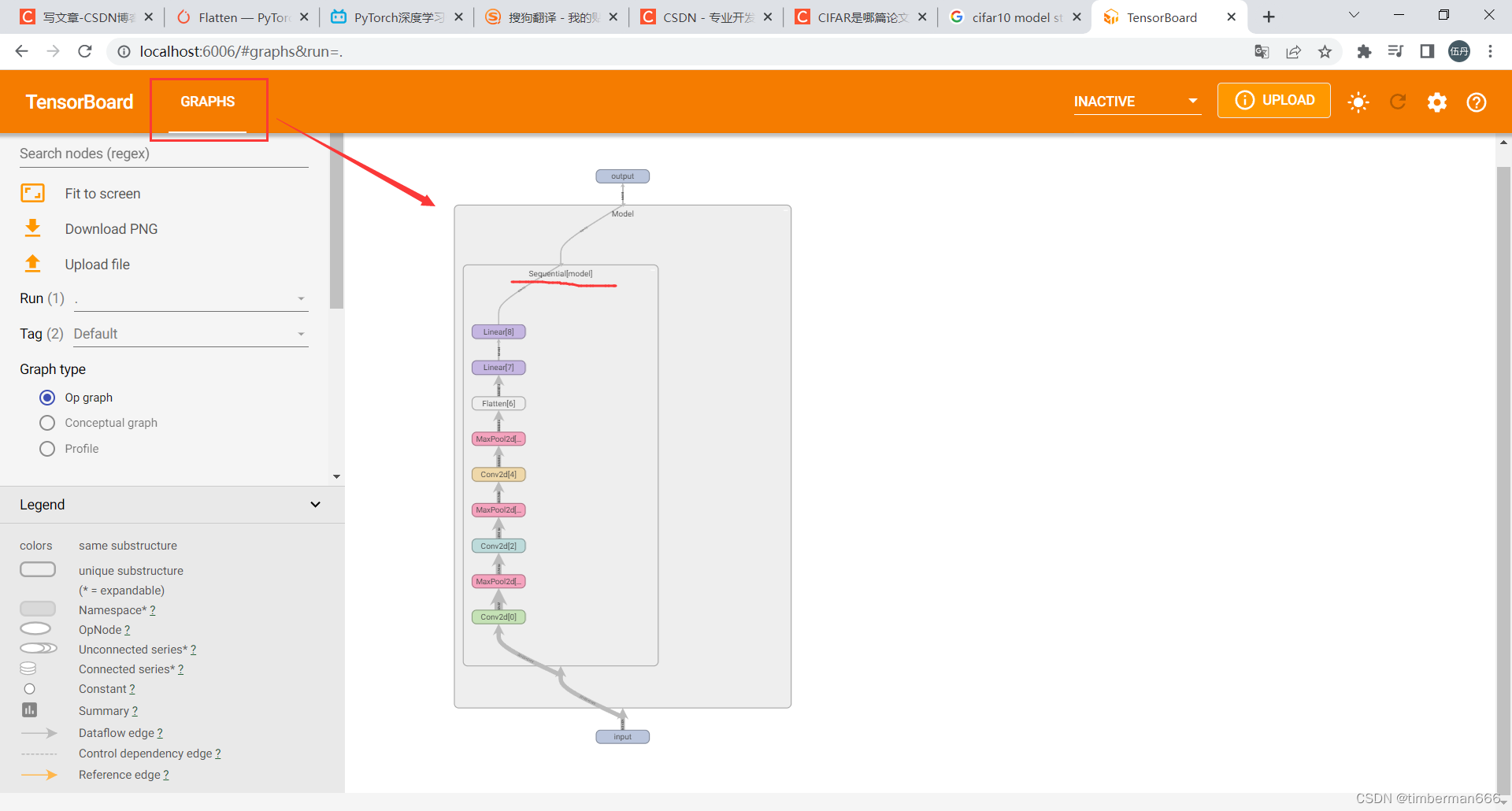
在代码最末尾加上writer.add_gragh(model, input)就可看到模型计算图,可放大查看。
writer = SummaryWriter('./logs/Seq')
writer.add_graph(model, input)
writer.close()















 987
987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









