






A Novel Cross-Attention Fusion-Based Joint Training Framework for Robust Underwater Acoustic Signal Recognition 论文链接
期刊:IEEE TRANSACTIONS ON GEOSCIENCE AND REMOTE SENSING
水声信号识别(UASR)系统在实现高精度的处理水下环境中低信噪比的复杂数据时面临着挑战,导致其面对噪声时鲁棒性有限。传统方法通常使用预训练的去噪模型来对噪声信号进行预处理。然而,由于去噪和识别模型的优化目标不同,去噪方法可能会引入信号失真,阻碍系统精度的有效提高。针对这一问题,本文提出了一种基于交叉注意融合的鲁棒UASR联合训练框架CAF-JT。CAF-JT由去噪模块、识别模块和CAF模块组成。它通过联合训练去噪前端和识别后端来解决不同优化方向的失配问题。此外,受多条件训练(MCT)方法的启发,CAF模块被设计为融合去噪和噪声音频的特征,从而融合噪声信息。这种融合机制使模型能够更好地适应噪声环境的特点,增强了模型的噪声鲁棒性。此外,为了提高UASR的性能,本文在去噪模块和识别模块中都加入了时频变换(TF-Transform)块来捕捉谱特征的时空分布。在两个开源水声信号数据集ShipsEar和DeepShip上对该方法进行了评估。大量实验表明,CAF-JT比传统的联合训练方法具有更好的噪声稳健性。特别是在低信噪比条件下,CAF-JT在两个数据集上的平均识别率分别达到94.84%和93.61%
引言
在实际的水下环境中,期望的声音信号(如船舶声、海洋生物声和海洋环境事件信号)不可避免地受到水下环境噪声和多径传播的污染和干扰,导致水声信号识别(UASR)的性能急剧下降。随着近年来海洋信息技术的飞速发展,数据驱动的智能识别技术,尤其是深度神经网络(DNN)技术,在水声信号识别领域取得了重大突破。这些先进技术有望辅助甚至替代传统声纳操作员,处理和监控水下目标发出的声波信号。然而,在实际海洋环境中,我们期望获取的声音信号,例如舰船噪声、海洋生物叫声和海洋环境事件产生的声波,常常受到水下环境噪声以及多径传播效应的严重影响,这直接导致了水声信号识别(UASR)性能的显著下降。特别是在信噪比较低(SNR)的水下环境中,基于DNN的识别模型往往会过分关注无关的噪声成分,这会对识别过程造成干扰,从而对决策产生负面影响。鉴于此,研究并开发一种针对低信噪比水声环境的抗噪智能识别方法显得尤为关键。本文的主要目标是应对这一挑战,旨在设计一种有效的解决方案,以便在低信噪比的水下环境中实现稳健的信号识别。
本文提出了一种创新的交叉注意融合联合训练框架(CAF-JT),旨在构建一个能够在低信噪比环境下有效运行的抗噪水声信号识别(UASR)系统。该框架通过将去噪和识别模块整合至单一网络结构中,实现了两者的联合优化。为了克服复杂海洋环境下的UASR挑战,采用了交叉注意融合(CAF)模块和联合训练策略。具体而言,针对舰船辐射信号的频谱特性,本文设计了一个时频变换(TF-Transform)模块,用于同时构建去噪和识别组件,从而显著提升了模型的综合性能。
这项研究的主要成果可以概括如下:
- 我们开发了一个联合训练框架,旨在减轻去噪前端预处理可能导致的音频失真问题。CAF-JT框架具有高度的可扩展性,能够灵活适应去噪和识别模块的各种组合。
- 我们采用CAF模块来动态地融合去噪音频和含噪音频的特征。这种融合策略不仅使得识别后端能够从前端接收到高质量的目标音频特征,还能够从含噪音频中提取相关的噪声细节,有效解决了噪声失配问题。
- 我们在去噪和识别模块中部署了多个连续的TF变换块,以提取能够从频谱特征的时间和频率维度捕获目标音频时空分布信息的特征。
- 通过广泛的实验验证,我们的框架展现了卓越的噪声稳健性。实验结果明确表明,在低信噪比条件下,CAF-JT框架的性能显著超越了传统的联合训练方法和独立的训练策略。
方法
下图展示了本文为抗噪水声信号识别(UASR)设计的CAF-JT框架的整体架构。该框架由三个主要部分组成:去噪前端、识别后端,以及负责融合去噪和噪声特征的交叉注意融合(CAF)模块。模型以短时傅立叶变换(STFT)得到的幅值谱图作为输入。首先,去噪模块被用于抑制噪声音频中的噪声成分。接着,去噪后的音频和原始带噪音频一同输入到我们设计的特征融合模块CAF中,该模块旨在聚合不同来源的特征信息,并从中提取出CAF特征表示。随后,识别模块利用这些融合后的特征来学习区分不同水下声源的特定特征。为了实现前端和后端模块的同步优化,我们采用了将两个组件联合训练的损失函数,从而显著提升了系统的整体性能。

在水声信号去噪前端,使用了经典的编解码器结构。同时将基于T-F的自我注意块引入到去噪模型中。在本文中,进一步设计了一些连续的TF变换块,以从频谱特征中提取时间和空间分布特征。如下图所示:

编解码器的主体由三个堆叠的卷积块组成,每个块包括2-D卷积层、非线性激活函数(RELU)和归一化层[批归一化(BN)]。所有二维卷积层的核大小为(5,7),步长为(1,1)。
在本文中,Transformer具体指的是模型的编码器部分。本文中的TF块由两个核心处理阶段构成,这两个阶段分别对频谱图特征的时间维度和频率维度进行操作。在每个阶段中,输入特征会沿着各自的维度被分割成多个小块。接着,这些小块将通过一系列的多头自注意力机制和前馈网络(FFN)层进行独立处理。多头自注意力机制使得模型能够关注来自不同区块的关联信息,并理解语谱图中的上下文依赖性。这种机制使得模型能够在维持局部结构一致性的同时,有效地融入全局信息。在FFN模块内,使用了LSTM层,而不是原始的全连接层。

本文设计了一个新的CAF模块。CAF将去噪和带噪的特征都作为输入,并通过融合来自不同来源的信息捕获更健壮的特征,使用CAF分量之前,从幅度谱图中提取对数梅尔滤波器组特征。总体架构如下图:

本文进一步拓展了交叉注意力机制,应用于CAF模块中,该模块包含两个主要分支:一个处理去噪特征,另一个处理噪声特征。具体而言,每个分支不仅接收来自自身的数据,还接收来自另一分支的信息,并将处理后的结果反馈回各自的分支。信息融合在每个分支内部的特征频率和时间维度上同时进行。随后,在CAF模块的后续迭代中,融合后的特征会再次与另一分支的信息进行深入交互。这种迭代过程会重复多次,使得CAF模块能够从不同来源有效地学习和捕捉特征。具体过程如下图:

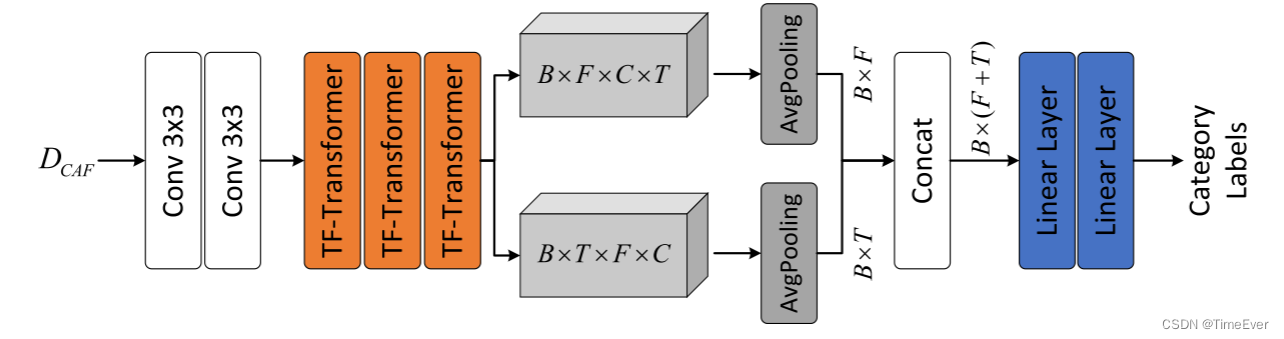
在水声信号识别任务中,本文采用了串联的TF变换器块作为核心架构。这些TF变换器块设计用于捕捉水声信号中复杂的时间与空间相关性。通过分析不同目标类别独有的频率特征和时间动态,识别后端能够有效地对它们进行区分和归类。下图展示了CAF-JT框架中识别后端的结构概览。识别模块接收融合特征DCAF作为输入,并通过两个3×3的卷积层进行初步处理,以提取抽象特征。这两个卷积层的输出通道数分别为6和12。接着,特征图经过多个TF变换器块,以进一步提取能够区分不同目标类别的高级特征,并确保输入信号能够被准确分类。在特征提取阶段完成后,特征图将通过诸如平均池化、全连接层或Softmax层等附加层进行处理,以便将特征精确地映射到各自的目标类别。这一步骤通常被称为分类层。为了充分挖掘时间和频谱频率特征的价值,我们采用了沿特征图时间和频率维度的平均池化来聚集关键信息。此外,所有卷积层后面都跟随批量归一化(BN)和参数化ReLU(PReLU)激活函数。
实验和结果
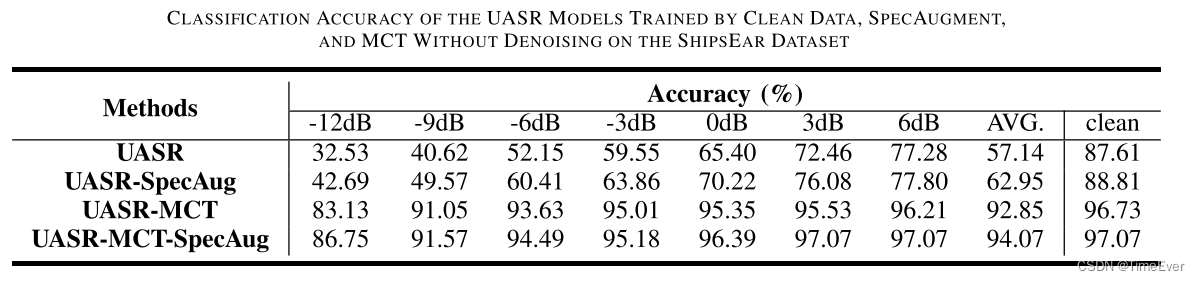
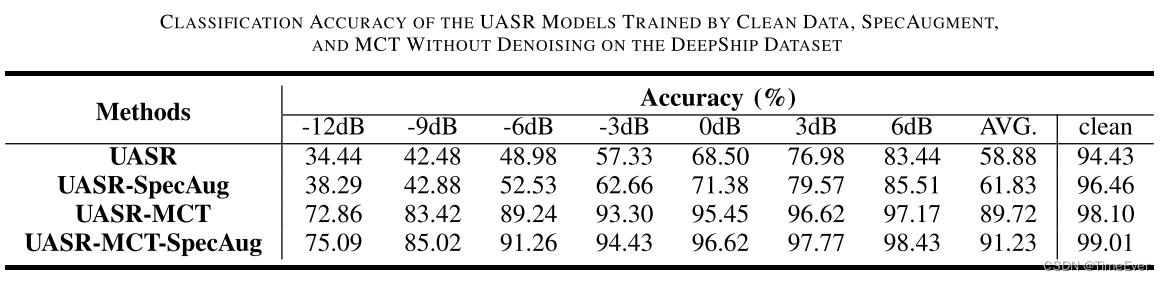
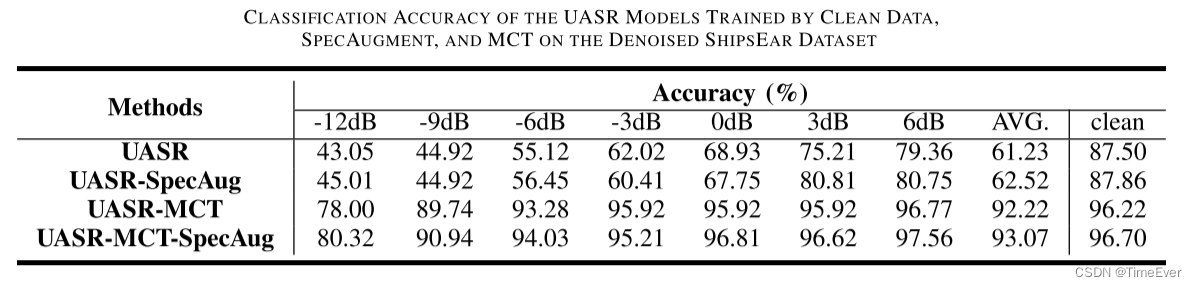
分别测试了在两种开源数据集上的降噪效果,结果如下:
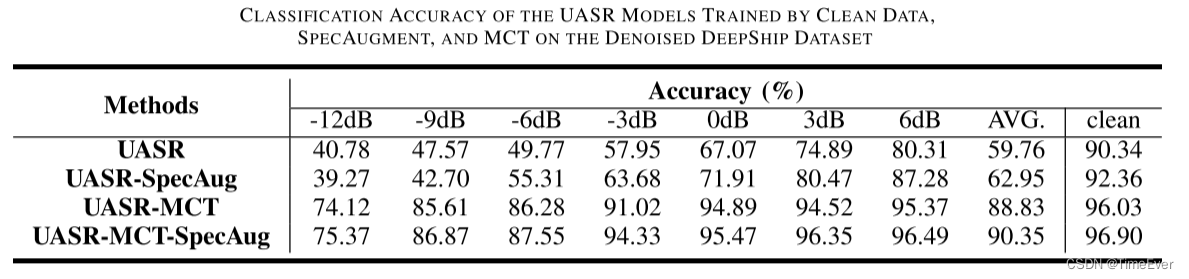
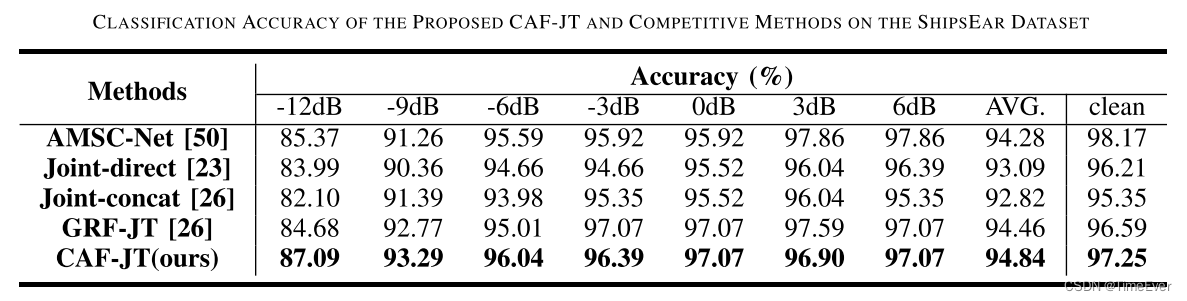
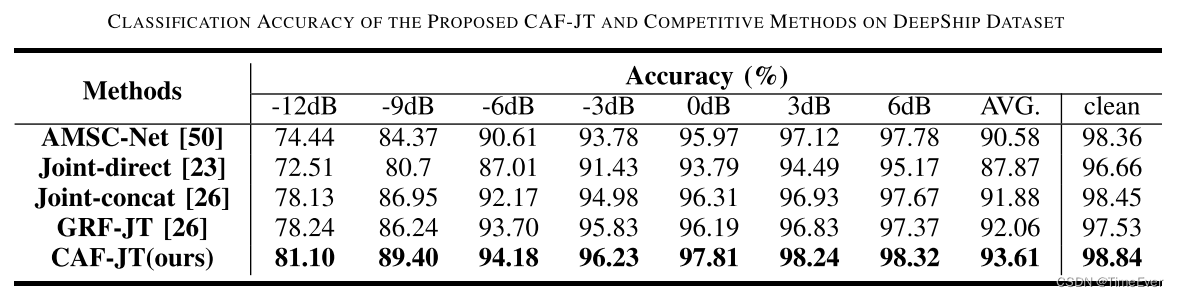

















 780
780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









