







 本文探讨如何使用SQL解决连续登陆问题,通过数据去重、自链接表格、row_number()和lag()窗口函数进行分析。文章以牛客网SQL29平均次日留存和SQL58连续自然月练题为例,详细讲解了不同方法的实现思路,包括表链接和窗口函数的应用。
本文探讨如何使用SQL解决连续登陆问题,通过数据去重、自链接表格、row_number()和lag()窗口函数进行分析。文章以牛客网SQL29平均次日留存和SQL58连续自然月练题为例,详细讲解了不同方法的实现思路,包括表链接和窗口函数的应用。
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
前言
在牛客网刷题,发现有几道比较难的题都跟连续登陆挂钩
可以连续的天或者连续的月
可以是连续两天,也可以是连续三天,连续n天
可以扩展到连续购买,连续刷题等业务场景
比如sql29 平均次日留存,sql58 任意两个连续自然月练题次数大于1的用户这两个例题
参考b站董旭阳TonyDong董老师的SQL面试题:连续登陆问题思考总结下基本的答题思路
并对这两道牛客网的题目进行整理。
提示:以下是本篇文章正文内容,下面案例可供参考
一、数据源
一张用户登录的表格 u_login
包括用户u_id,登陆日期login_time
二、自链接表格的方法
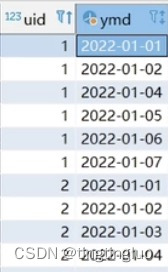
1.对原始数据进行去重处理
因为一个用户可以在一天登陆好几次,但是只需要每个用户一天有一条记录就可以了,所以需要先去重
想得到的表:
代码:
select distinct u_id, date(login_time) ymd
from u_login
where login_time between timestamp '2022-10-1 00:00:00' and timestamp '2022-10-31 00:00:00'
#指定一个时间段知识点:
1,用date()函数提取日期,可以命名为ymd,如果只提取到月就用date_format,命名为ym
2,timestamp时间戳指定一个时间段
3,如果distinct关键字后面有多个字段时,则会对多个字段进行组合去重,只有多个字段组合起来的值是相等的才会被去重
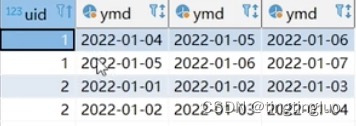
2.如和判断是否是连续登陆
自己跟自己链接,此处以连续登陆三天为例子
t1的时间加一天是t2的时间,t2的时间加一天是t3的时间
想得到的表:
代码:
select t1.id,t1.ymd,t2.ymd,t3.ymd
from
(select distinct u_id, date(login_time) ymd
from u_login
where login_time between timestamp '2022-10-1 00:00:00' and timestamp '2022-10-31 00:00:00') t1
join
(select distinct u_id, date(login_time) ymd
from u_login
where login_time between timestamp '2022-10-1 00:00:00' and timestamp '2022-10-31 00:00:00') t2
on t1.u_id=t2.u_id
and t1.ymd=date_add(t2.ymd+interval 1 day)
#此处用datediff()函数也ok,datediff(t2.ymd,t1.ymd)=1
join
(select distinct u_id, date(login_time) ymd
from u_login
where login_time between timestamp '2022-10-1 00:00:00' and timestamp '2022-10-31 00:00:00') t3
on t2.u_id=t3.u_id
and t2.ymd=date_add(t3.ymd+interval 1 day)
知识点:
1,此处连表不用left join,用的是join
原因:用join来连接的话,若第二天没有登陆,则t1的表里的id数据就会过滤掉,过滤掉就表示没有连续登陆所以没关系。跟留存率不一样,第一天登陆(注册)的用户不能过滤,所以留存率连表的时候用的left join。
2,链接条件里面的datediff()和date_add()函数的运用
三.用row_number()窗口函数优化代码
1.将t1定义为一个子查询因子(临时表)
with t1 as
(select distinct u_id, date(login_time) ymd
from u 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8368
8368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









