







1.首先,我们要明白执行函数时,编译器对参数以及返回值的处理。编译器会给每个函数参数创建一个临时副本;对于函数返回值,编译器在执行return语句时,会创建一个临时副本,并将该副本放入缓冲区中。
2.下面我们将结合图和代码演示来分析函数在“值传递“和”地址传递“时,发生的动作。
值传递
我们给出这样一段代码片段:
int byvalue(int temp)
{
temp++;
int temp01 = 0;
temp01++;
return temp01;
}
int main()
{
int a = 2;
int b = 2;
cout << "a = " << a << endl;
cout << "b = " << b << endl;
b = byvalue(a);
cout << "a = " << a << endl;
cout << "b = " << b << endl;
return 0;
}我们按照1中知识,我们知道在执行byvalue函数时,编译器会创建参数temp的一个临时副本_temp,在函数体内一切对temp的操作,其实都是对其临时副本_temp的操作。所以对于操作”temp++”其实是”_temp++”,修改的是_temp的值,而temp的值不变,我们可用图1形象表示。
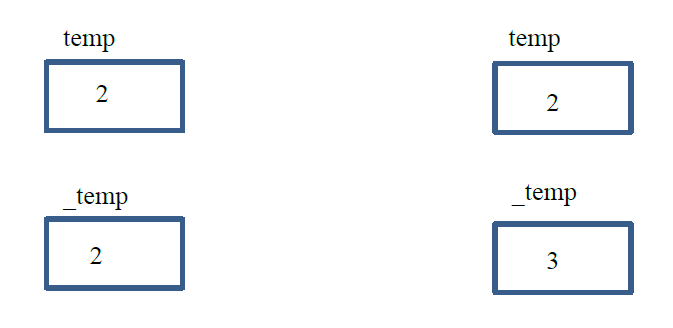
那么,对于返回值呢?又是怎样的情况呢。
同样,从1中我们知道,在执行return temp01时,函数会创建temp01的副本_temp01并将_temp01存在缓冲区中,并且在离开函数作用域后,temp01的生命周期结束,内存被释放,但缓冲区中的_temp01还存在着,如图2所示。

执行上述代码片段,实参a的值在执行byvalue函数之后不会改变,但函数返回值会赋值给b,b会改变。我们可以得到以下结果:
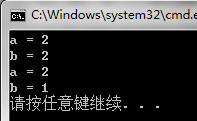
所以函数”值传递“并不会改变实参,但是对返回值却是有效的。
地址传递
同样,我们也给出一段代码,并对代码进行分析。
int* bypointer(int *p)
{
//注意*p++和(*p)++的区别,前者是指针自增1后,取指向值;后者是取p指向的值,并该值自增1
(*p)++;
int temp01 = 1;
temp01++;
int *q = &temp01;
return q;
}
int main()
{
int a = 1;
int *a_p = &a;
cout << *a_p << endl;
int *b_p;
b_p = bypointer(a_p);
//byvalue(a);
cout << *a_p << endl;
cout << *b_p << endl;
return 0;
}对于指针传递,我们同样可以按照值传递的思路分析。首先,在执行函数bypointer()函数时,函数会给指针p一个临时副本_p。我们可以知道指针中存的是某段内存的地址,所以我们知道p和_p中有相同的值,是同一内存段的首地址,即p和_p指向同一内存。在bypointer函数体内执行(*p)++,也就是(*_p)++,不过p和_p指向同一内存,*p和*_p指代同一变量,所以(*p)也确实自增了1,如图4所示。
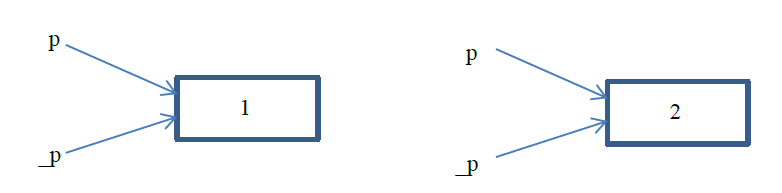
对于”指针传递“的返回值,这里我们需要考虑两种情况:1)指针指向栈内存;2)指针指向非栈内存(堆、全局或静态存储区、常量存储区)
同”值传递“返回值一样分析:
在执行return q;语句时,创建指针q的副本_q,并存在缓冲区中。但若q指向的是栈内存的话,在函数结束后,这块内存会被释放,_q也就成为指向垃圾内存的野指针,自然将其赋值给b_q后,b_q也是指向垃圾内存的野指针,示意如图5所示。
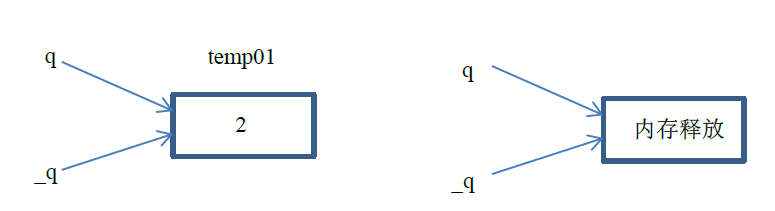
执行上述代码片段,指针a_p指向的值在执行byvalue函数之后会改变,但函数返回的指针指向的栈内存已被释放,故b_p指向的值为垃圾值。我们可以得到以下结果:
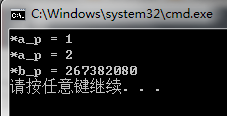
所以,函数返回值不能是指向”栈内存“的指针,但可以是指向”堆内存“的指针,因为函数结束时,编译器不会自动释放堆内存。(注意char *p = “hello world!”,这里的p是指向常量内存区的指针,函数返回这样的指针也是可以的,不过返回的始终是一个只读的内存块。)
Note:栈内存中的变量通常是局部变量、函数参数等。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









