






基于SMOTE-特征选择的XGBoost模型分类预测代码。
1、数据处理
#------------1.导入数据--------------------
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
# 设置Matplotlib以显示中文
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置默认绘图风格
plt.style.use("ggplot")
df = pd.read_csv('2024_B/data.csv')
# 标签划分与标准化:
y = df['class'].values
print("标签转换前的结果:", y[:10])# 获取前10个元素
# 创建一个字典来映射旧的标签到新的标签
label_mapping = {1: 0, 2: 1, 3: 2, 4: 3}
# 使用列表推导式来替换标签,同时保持不在映射中的标签不变
converted_labels = [label_mapping.get(label, label) for label in y]
# 标签划分与标准化
y = converted_labels
print("标签转换后的结果:", converted_labels[:10])
# x_data = df.drop(["id", "class"], axis=1)
x_data = df[['x7', 'x6', 'x4','x5','y1', 'x3', 'x1','x8','x9','y2','y3']]
# x = (x_data - np.min(x_data)) / (np.max(x_data) - np.min(x_data))
# 计算每个特征的均值和标准差
means = np.mean(x_data, axis=0)
stds = np.std(x_data, axis=0)
# 确保标准差不为零以避免除以零错误
stds[stds == 0] = 1e-6 # 使用一个很小的正数如1e-6代替0
# 应用Z得分标准化
x = (x_data - means) / stds
from sklearn.datasets import make_classification
from collections import Counter
from imblearn.over_sampling import SMOTE
smo = SMOTE(random_state=24)
x_smo, y_smo = smo.fit_resample(x, y)
print(Counter(y))
print(Counter(y_smo))
结果:
标签转换前的结果: [2 2 2 1 2 1 2 1 2 2]
标签转换后的结果: [1, 1, 1, 0, 1, 0, 1, 0, 1, 1]
Counter({1: 118997, 2: 37422, 0: 34399, 3: 9182})
Counter({1: 118997, 0: 118997, 2: 118997, 3: 118997})
2、模型训练
#------------2.建模--------------------
from xgboost import XGBClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, roc_auc_score, matthews_corrcoef, classification_report, \
average_precision_score
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
# 切分训练集和测试集
# train_x, test_x, train_y, test_y = train_test_split(x, y, test_size=0.3, random_state=24)
train_x, test_x, train_y, test_y = train_test_split(x_smo, y_smo, test_size=0.3, random_state=24)
# XGBoost参数初始化
xgb = XGBClassifier(
objective='multi:softprob', # 将'multi:softmax' 改为 'multi:softprob'方便后面绘图
num_class=4,
colsample_bytree=0.7,
learning_rate=0.1,
max_depth=5,
subsample=0.7,
gamma=0.6,
alpha=1,
reg_lambda=2,
n_estimators=2900
)
# 建模与预测
xgb.fit(train_x, train_y)
predictions_train = xgb.predict(train_x)
y_pred = xgb.predict(test_x)
# 多分类性能指标计算辅助函数
from sklearn.metrics import recall_score, f1_score
def calculate_multiclass_metrics(y_true, y_pred):
lb = LabelBinarizer()
lb.fit(y_true)
y_true_bin = lb.transform(y_true)
y_pred_bin = lb.transform(y_pred)
acc = accuracy_score(y_true, y_pred)
cm = confusion_matrix(y_true, y_pred)
class_report = classification_report(y_true, y_pred, output_dict=True)
avg_auc = roc_auc_score(y_true_bin, y_pred_bin, multi_class="ovr") # One-vs-Rest策略计算AUC
avg_precision = average_precision_score(y_true_bin, y_pred_bin, average="macro") # 宏平均精度
avg_recall = recall_score(y_true_bin, y_pred_bin, average="macro") # 宏平均召回率
avg_f1 = f1_score(y_true_bin, y_pred_bin, average="macro") # 宏平均F1分数
m_coef = matthews_corrcoef(y_true, y_pred)
return {
"accuracy": acc,
"confusion_matrix": cm,
"avg_auc": avg_auc,
"avg_precision": avg_precision,
"avg_recall": avg_recall,
"avg_f1": avg_f1,
"mcc": m_coef,
"class_report": class_report
}
print('---'*20)
# 训练集性能评估
train_metrics = calculate_multiclass_metrics(train_y, predictions_train)
print("Training Metrics:")
# print(f"Confusion Matrix:\n{train_metrics['confusion_matrix']}")
print(f"Accuracy: {train_metrics['accuracy']:.6f}")
print(f"Avg. AUC: {train_metrics['avg_auc']:.6f}")
print(f"Avg. Precision: {train_metrics['avg_precision']:.6f}")
print(f"Avg. recall: {train_metrics['avg_recall']:.6f}")
print(f"Avg. avg_f1: {train_metrics['avg_f1']:.6f}")
print(f"MCC: {train_metrics['mcc']:.6f}")
print(f"class_report: {train_metrics['class_report']}")
print('---'*20)
# 测试集性能评估
test_metrics = calculate_multiclass_metrics(test_y, y_pred)
print("\nTest Metrics:")
# print(f"Confusion Matrix:\n{test_metrics['confusion_matrix']}")
print(f"Accuracy: {test_metrics['accuracy']:.6f} ")
print(f"Avg. AUC: {test_metrics['avg_auc']:.6f}")
print(f"Avg. Precision: {test_metrics['avg_precision']:.6f}")
print(f"Avg. recall: {test_metrics['avg_recall']:.6f}")
print(f"Avg. avg_f1: {test_metrics['avg_f1']:.6f}")
print(f"MCC: {test_metrics['mcc']:.6f}")
print(f"class_report: {test_metrics['class_report']}")
print('---'*20)
结果:
------------------------------------------------------------
Training Metrics:
Accuracy: 0.999114
Avg. AUC: 0.998785
Avg. Precision: 0.996574
Avg. recall: 0.997930
Avg. avg_f1: 0.998173
MCC: 0.998472
class_report: {'0': {'precision': 0.9997933286487827, 'recall': 0.9995867427060088, 'f1-score': 0.9996900250046497, 'support': 24198.0},
'1': {'precision': 0.9994834586646806, 'recall': 0.9996755977411991, 'f1-score': 0.9995795189697013, 'support': 83230.0},
'2': {'precision': 0.9979722232849982, 'recall': 0.9980485938396786, 'f1-score': 0.9980104071013162, 'support': 26135.0},
'3': {'precision': 0.9964196762141968, 'recall': 0.9944073326083579, 'f1-score': 0.9954124873649016, 'support': 6437.0},
'accuracy': 0.9991142857142857,
'macro avg': {'precision': 0.9984171717031647, 'recall': 0.9979295667238112, 'f1-score': 0.9981731096101422, 'support': 140000.0},
'weighted avg': {'precision': 0.999114033876063, 'recall': 0.9991142857142857, 'f1-score': 0.9991141054262251, 'support': 140000.0}}
------------------------------------------------------------
Test Metrics:
Accuracy: 0.997133
Avg. AUC: 0.996294
Avg. Precision: 0.989559
Avg. recall: 0.993733
Avg. avg_f1: 0.994392
MCC: 0.995042
class_report: {'0': {'precision': 0.9990188383045526, 'recall': 0.9981374375061268, 'f1-score': 0.998577943411955, 'support': 10201.0},
'1': {'precision': 0.9984624846248462, 'recall': 0.9986020633544888, 'f1-score': 0.9985322691119528, 'support': 35767.0},
'2': {'precision': 0.9930144132991423, 'recall': 0.994949942411624, 'f1-score': 0.9939812356169233, 'support': 11287.0},
'3': {'precision': 0.9897323065639897, 'recall': 0.9832422586520947, 'f1-score': 0.9864766081871346, 'support': 2745.0},
'accuracy': 0.9971333333333333,
'macro avg': {'precision': 0.9950570106981328, 'recall': 0.9937329254810835, 'f1-score': 0.9943920140819914, 'support': 60000.0},
'weighted avg': {'precision': 0.9971327953591196, 'recall': 0.9971333333333333, 'f1-score': 0.997132362765908, 'support': 60000.0}}
------------------------------------------------------------
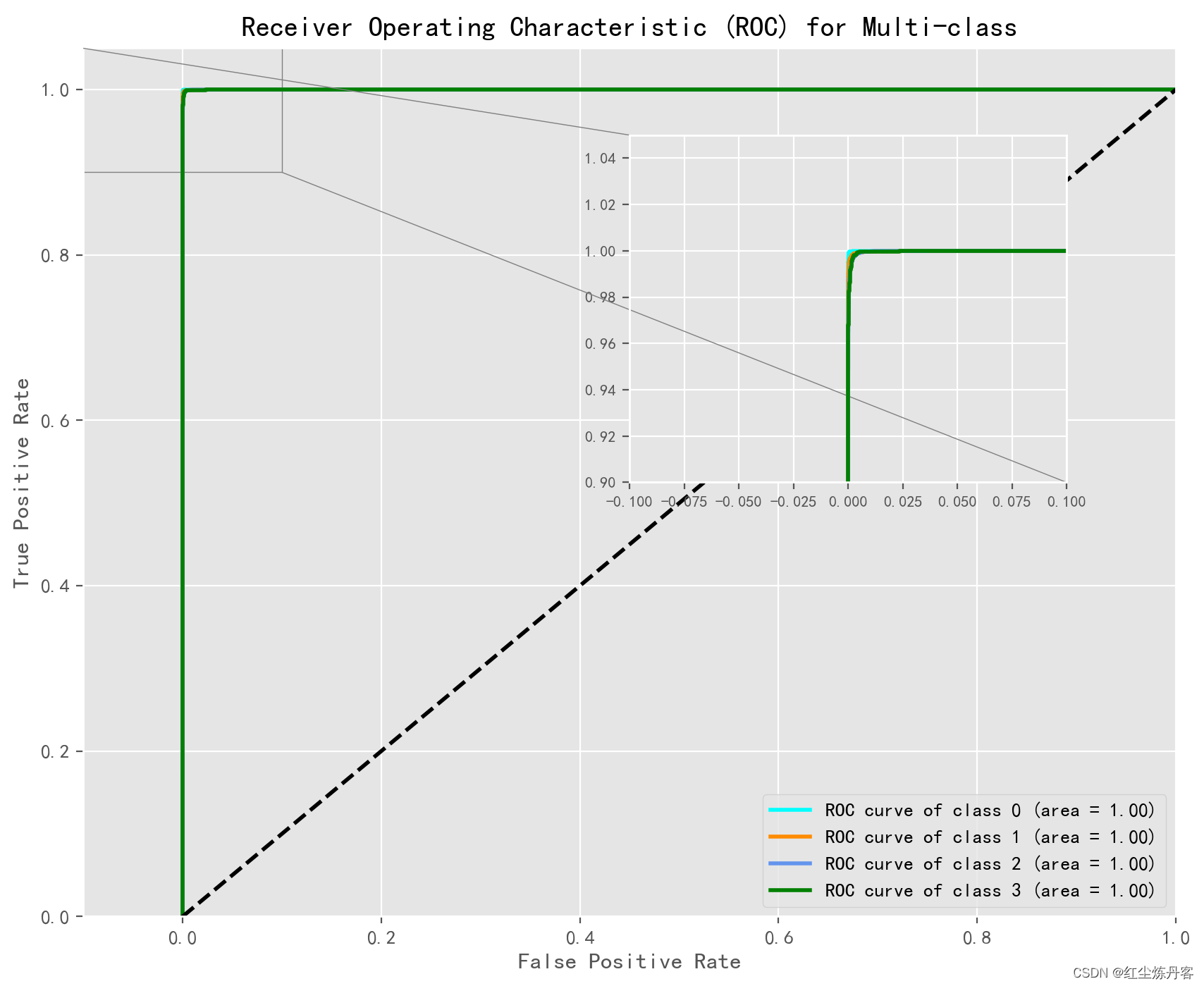
3、ROC图
#-------------------绘制ROC图-----------------
from sklearn.metrics import roc_curve, auc
from itertools import cycle
import matplotlib.pyplot as plt
from sklearn.preprocessing import label_binarize
from mpl_toolkits.axes_grid1.inset_locator import inset_axes, mark_inset
# 多类别标签二值化(OvR策略)
y_test_binarized = label_binarize(test_y, classes=np.arange(4))
n_classes = y_test_binarized.shape[1]
# 预测概率
y_score = xgb.predict_proba(test_x)
# 绘制ROC曲线
plt.figure(figsize=(10, 8), dpi=200)
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test_binarized[:, i], y_score[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
colors = cycle(['aqua', 'darkorange', 'cornflowerblue', 'green'])
# 绘制ROC曲线
for i, color in zip(range(n_classes), colors):
plt.plot(fpr[i], tpr[i], color=color, lw=2,
label='ROC curve of class {0} (area = {1:0.2f})'
''.format(i, roc_auc[i]))
plt.plot([0, 1], [0, 1], 'k--', lw=2)
plt.xlim([-0.1, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) for Multi-class')
# 创建局部放大的视图
axins = plt.gca().inset_axes([0.5, 0.5, 0.4, 0.4]) # 调整局部放大视图的位置和大小
for i, color in zip(range(n_classes), colors):
axins.plot(fpr[i], tpr[i], color=color, lw=2)
x1, x2, y1, y2 = -0.1, 0.1, 0.9, 1.05
axins.set_xlim(x1, x2)
axins.set_ylim(y1, y2)
# 控制小图横纵坐标字体大小
axins.tick_params(axis='x', labelsize=8)
axins.tick_params(axis='y', labelsize=8)
# # 设置局部放大视图的显示范围
x_ratio = 0.3 # x轴显示范围的扩展比例
y_ratio = 0.02 # y轴显示范围的扩展比例
x1, x2, y1, y2 = -0.1, 0.1, 0.9, 1.05
axins.set_xlim(x1 - x_ratio, x2 + x_ratio)
axins.set_ylim(y1 - y_ratio, y2 + y_ratio)
mark_inset(plt.gca(), axins, loc1=2, loc2=4, fc="none", ec="0.5")
plt.legend(loc="lower right")
plt.savefig('XGB-result-AUC.svg', format='svg', dpi=1000)
plt.show()
4、批量预测
#------------3.应用模型预测数据--------------------
df1 = pd.read_csv('2024_B/predict.csv')
X_test = df1[['x7', 'x6', 'x4','x5','y1', 'x3', 'x1','x8','x9','y2','y3']]
# x = (x_data - np.min(x_data)) / (np.max(x_data) - np.min(x_data))
# 计算每个特征的均值和标准差
means = np.mean(x_data, axis=0)
stds = np.std(x_data, axis=0)
# 确保标准差不为零以避免除以零错误
stds[stds == 0] = 1e-6 # 使用一个很小的正数如1e-6代替0
# 应用Z得分标准化
x = (x_data - means) / stds
y_pred = xgb.predict(X_test)
# 构建提交结果的DataFrame
submission_df = pd.DataFrame({'id': df1['id'], 'class': y_pred})
print(submission_df.head(25))
print('--'*25)
print(submission_df.sample(25))
submission_df = pd.read_csv('2024_B/submit.csv')
# 将预测结果填充到'class'列
submission_df['class'] = y_pred
submission_df.to_csv('2024_B/submit.csv', index=False)
















 2865
2865

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









