







 本文介绍了使用Logistic回归分析信用卡欺诈数据集的过程,包括数据预处理、下采样、交叉验证等步骤。通过下采样解决类别不平衡问题,使用交叉验证调整模型参数,并展示模型在原始数据上的表现,强调了样本不均衡对模型性能的影响。
本文介绍了使用Logistic回归分析信用卡欺诈数据集的过程,包括数据预处理、下采样、交叉验证等步骤。通过下采样解决类别不平衡问题,使用交叉验证调整模型参数,并展示模型在原始数据上的表现,强调了样本不均衡对模型性能的影响。
Logistic回归建模分类实例——信用卡欺诈监测
现有一个creditcard.csv(点此下载)数据集,其中包含不同客户信用卡的特征数据(V1、V2……V28、Amount)和标签数据(Class),利用Logistic回归建模,通过这个模型预测客户信用卡是否有被欺诈的风险。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
% matplotlib inline
data = pd.read_csv('creditcard.csv')
from sklearn.preprocessing import StandardScaler
data['normAmount'] = StandardScaler().fit_transform(data['Amount'].values.reshape(-1,1))
data = data.drop(['Amount','Time'], axis=1)
#data.head()% matplotlib inline表示将图表嵌入到Notebook中。如果不加这一行代码,下面的图2中的柱状图会显示不出来。
将creditcard.csv中的数据读到data中,因为creditcard.csv中的数据中Amount这一列比较特殊,其他列都在(-1,1)的区间内,而Amount这一两列浮动范围比较的,要知道特征数据的浮动范围越大,在建模过程中对于预测结果的影响就越大,但就这组数据来说我们并有足够的先验信息来说明特征数据的重要程度,故我们要对所有特征数据一视同仁,让他们都在(-1,1)之间。所以我们要对数据进行一些预处理,首先就要通过sklearn.preprocessing中的StandardScaler模块将Amount这一列的数据进行归一化(标准化)操作。而后数据中有一列是Time,这一列数据是无用的,也就是说对于信用卡欺诈预测是没有用的,所以我们要将其删掉。
注意:data.drop([‘Amount’,’Time’], axis=1) 不会改变data本身,所以要将其赋值给data。笔者在用的时候以为它和reverse(),sort()这些函数一样会改变数据本身,在这儿踩了一脚坑。
data[‘Amount’].values.reshape(-1,1)中reshape后(-1,1)表示将这个数组变换成X*1的形式,至于X是多少就要看原始数组中到底有多少元素了。
因为一般情况下,我们得到的原始数据集中都是不能直接拿来用的,它们要么有大量无用信息,要么有缺失数据……,总之对于原始数据的预处理是必不可少的。下面就是通过data.head()显示出来的处理完成的数据预览图。
count_classes = pd.value_counts(data['Class'], sort = True).sort_index()
print count_classes
count_classes.plot(kind = 'bar')
plt.title("Fraud class histogram")
plt.xlabel("Class")
plt.ylabel("Frequency")通过matplotlib.pyplot来画一个图,统计一下数据中正负样本的个数,结果如下图所示:
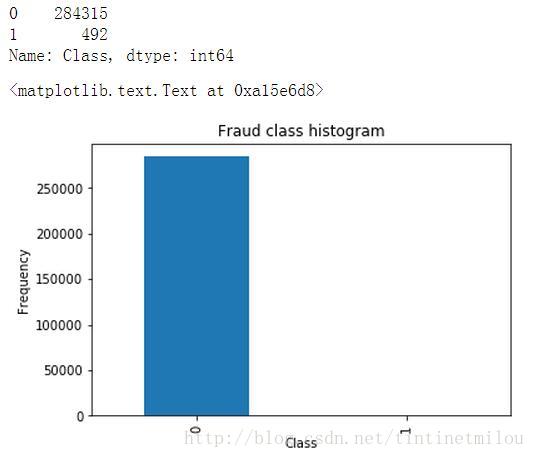
由图可知,我们的数据中的负样本(本例中1表示信用卡有被欺诈风险,为负样本)是很少的,这叫做样本不均衡,如果我们不进行处理,直接用这样的数据来进行训练建模,那得到的结果是很糟糕的(有多糟糕见下文)。所以我们要进行样本数据处理,这用两种方法:下采样和过采样。本篇博客主要介绍下采样的实现步骤,下一篇介绍过采样。
下采样
就是从数量比较多的那类样本中,随机选出和与数量比较少的那类样本数量相同的样本,最终组成正负样本数量相同的样本集进行训练建模。
X = data.ix[:,data.columns != 'Class']
Y = data.ix[:,data.columns == 'Class']
number_record_fraud = len(Y[Y.Class==1])
fraud_indices = np.array(data[data.Class == 1].index)
normal_indices = np.array(data[data.Class == 0].index)
random_normal_indices = np.array(np.random.choice(normal_indices,number_record_fraud,replace=False))
under_sample_indices = np.concatenate([fraud_indices,random_normal_indices])
under_sample_data = data.iloc[under_sample_indices,:]
X_under_sample = under_sample_data.ix[:,under_sample_data.columns != 'Class']
Y_under_sample = under_sample_data.ix[:,under_sample_data.columns == 'Class']
from sklearn.cross_validation import train_test_split
X_train_under_sample,X_test_under_sample,Y_train_under_sample,Y_test_under_sample = train_test_split(X_under_sample,Y_under_sample,test_size=0.3,random_state=0)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=0)通过np.random.choice在正样本的索引(normal_indices)中随机选负样本个数(number_record_fraud )个索引。
np.concatenate将负样本和挑选的负样本索引进行合并成
根据上面得到的索引来去原始数据中提取特征(X_under_sample)和标签(Y_under_sample )
接下来是用klearn.cross_validation 模块中的train_test_split来将上面提取到的数据(特征,标签)分为训练集和测试集,测试占总体的30%。X_train, X_test, Y_train, Y_test是对原始未进行下采样的数据进行的同样操作得到的,这些数据后面测试的时候会用到。
交叉验证
机器学习中,当将要采用的机器学习算法确定后,模型训练的实质就是确定一系列的参数了(调参)。调参其实就是各种试,但也是有章可循的。首先要用一些数据和某个参数来训练得到一个模型,然后用另外一些数据来带入刚才训练好的模型,输出结果和标签进行比较,计算出来一个评价指标,根据这个评价指标来判断刚才带入的那个参数到底好不好。
先说上面的评价指标,最常见的评价指标为精度:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 358
358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









