






伪分布:按照分布式的步骤搭建,但是呢,服务器只有一台。
只能用于开发、和学习用。
比如我想搭建一个集群,将集群中的所有磁盘连接在一起形成一个云端的hdfs.
但是公司就买了一台服务器。所以搭建出来的就是伪分布模式。
伪分布的意思:按照全分布的步骤搭建的集群,但是linux服务器只有一台。
进行搭建之前的一些准备工作:
环境准备⼯作:
1、安装了jdk
2、安装了hadoop
3、关闭了防⽕墙
systemctl status firewalld
4、免密登录
⾃⼰对⾃⼰免密
ssh-copy-id bigdata01 选择yes 输⼊密码
测试免密是否成功: ssh bigdata01
5、修改linux的⼀个安全机制
vi /etc/selinux/config
修改⾥⾯的 SELINUX=disabled
6、设置host映射 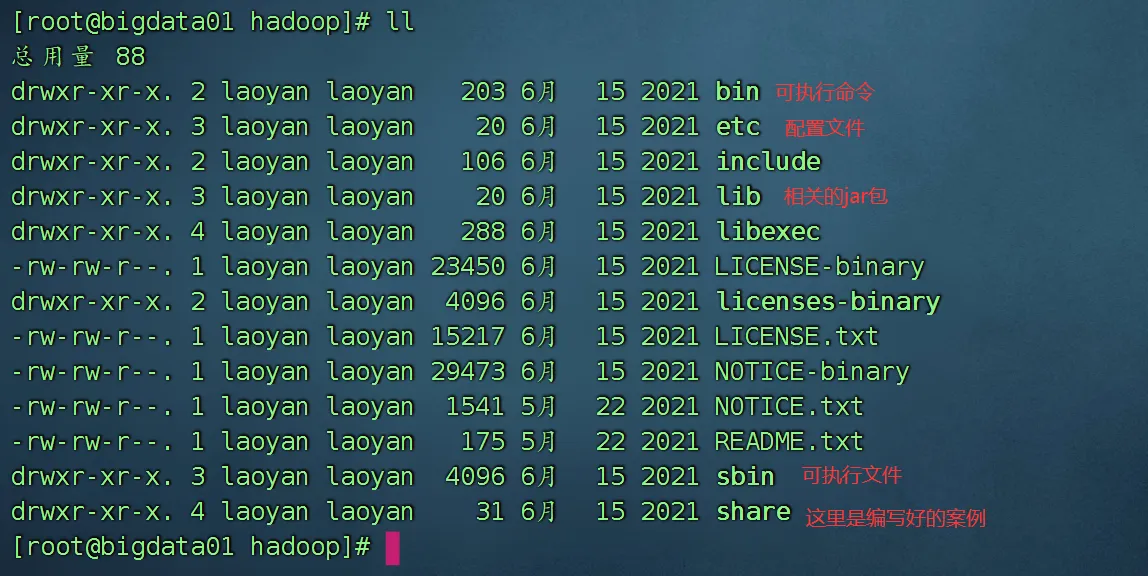
配置开始:
位置: /opt/installs/hadoop/etc/hadoop
以下圈住的都是重要的文件:

配置:core-site.xml文件
<configuration>
<!-- 设置namenode节点 -->
<!-- 注意: hadoop1.x时代默认端⼝9000 hadoop2.x时代默认端⼝8020 hadoop3.x时 代默认端⼝ 9820 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata01:9820</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的⼀个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/installs/hadoop/tmp</value>
</property>
</configuration>配置:hdfs-site.xml文件
<configuration>
<property>
<!--备份数量-->
<name>dfs.replication</name>
<value>1</value>
</property>
<!--secondarynamenode守护进程的http地址:主机名和端⼝号。参考守护进程布局 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata01:9868</value>
</property>
<!-- namenode守护进程的http地址:主机名和端⼝号。参考守护进程布局 -->
<property>
<name>dfs.namenode.http-address</name>
<value>bigdata01:9870</value>
</property>
</configuration>配置:hadoop-env.sh文件
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export JAVA_HOME=/opt/installs/jdk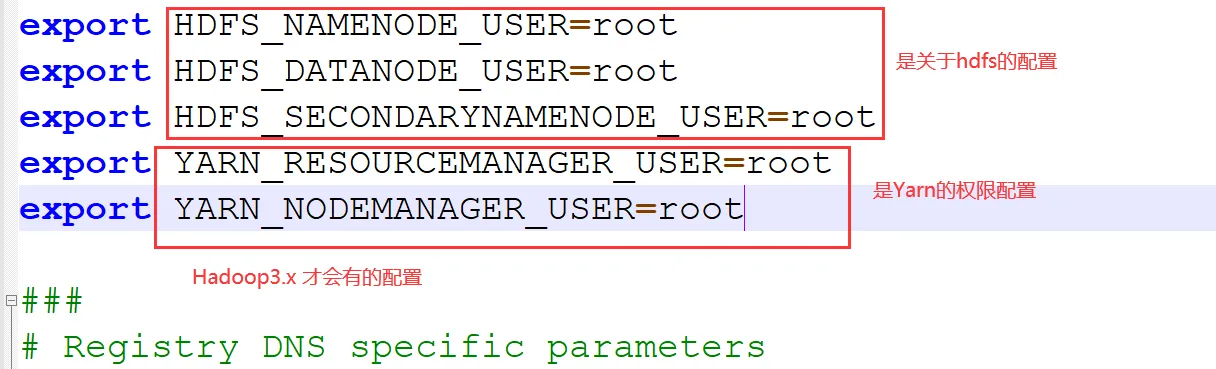
修改workers 文件:
vi workers
修改里面的内容为: bigdata01 保存
对整个集群记性namenode格式化:
hdfs namenode -format启动集群:
start-dfs.sh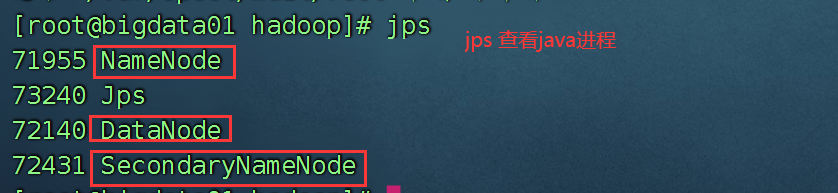
通过网址访问hdfs集群:
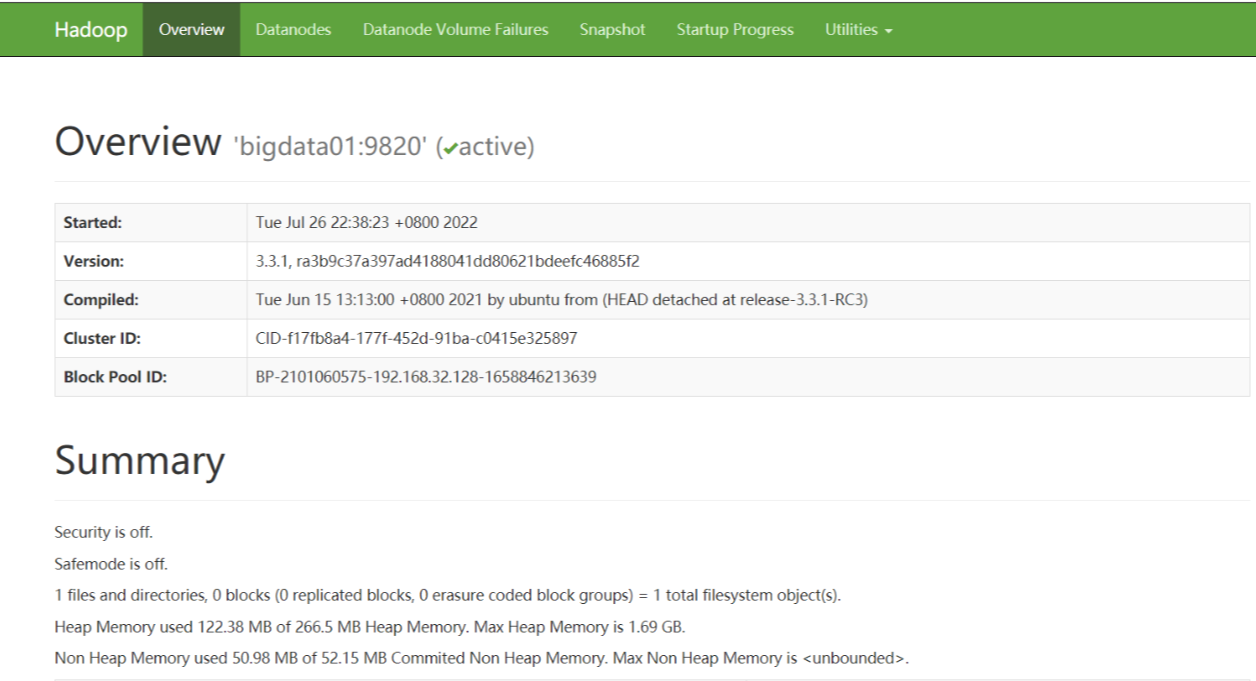
如果访问不到:检查防火墙是否关闭。
测试一下这个hdfs的文件系统:
目前搭建的这个到底是hdfs的伪分布还是hadoop伪分布?
答案是 hdfs的伪分布,但是hdfs 也是hadoop的一部分。
真正的hadoop伪分布还需要配置yarn 才算真正的伪分布。
使用这个文件系统:
1、将要统计的内容上传至hdfs文件系统
hdfs dfs -mkdir /home
hdfs dfs -put /home/wc.txt /home
2、使用wordcount统计wc.txt
hadoop jar /opt/installs/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /home/wc.txt /home/output
3、查看统计结果
hdfs dfs -cat /output/*假如你的环境是伪分布式模式,那么本地模式直接被替换了,回不去了。
此模式跟本地模式有何区别?
这两种方式,首选统计的代码都在本地,但是本地模式,数据和统计的结果都在本地。
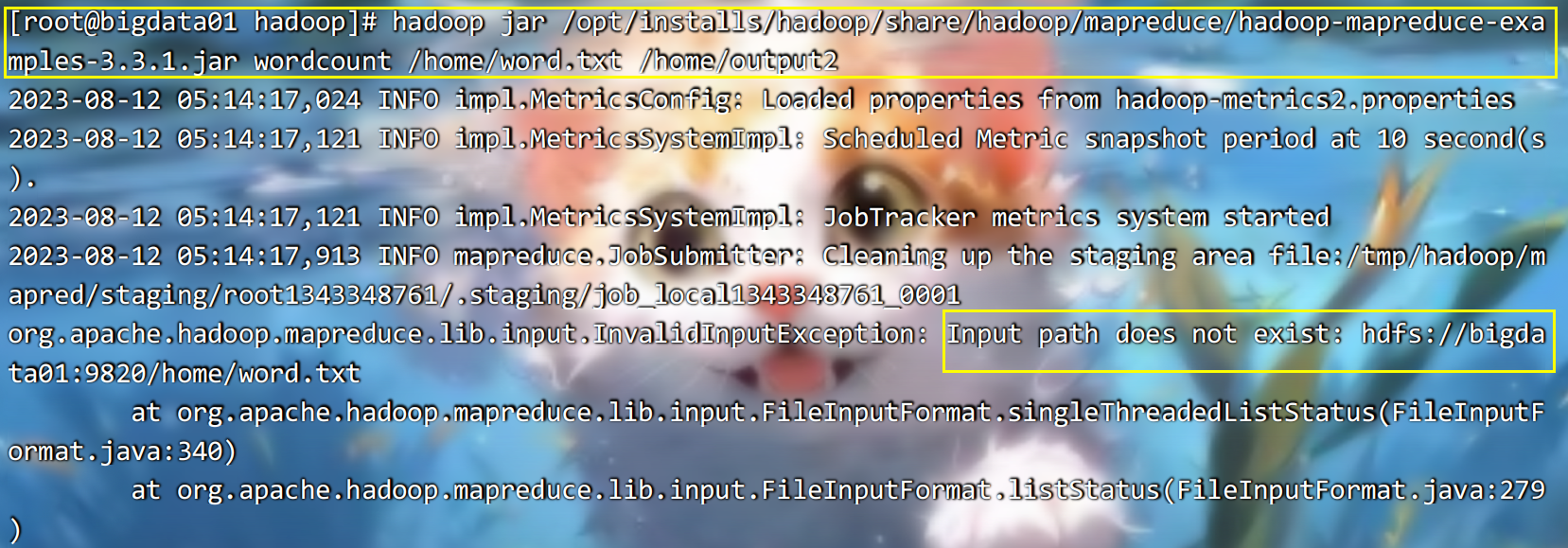
伪分布模式,它的数据来源在 hdfs 上,统计结果也放在 hdfs上。如果此时再执行以前的workcount就会报错,原因是以前是本地模式,现在是伪分布模式,伪分布模式,只会获取hdfs上的数据,将来的结果也放入到hdfs上,不会获取本地数据:

















 954
954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









