






全分布模式:必须至少有三台以上的Linux
前期准备工作:
1、准备三台服务器
目前有两台,克隆第二台(因为第二台没有安装mysql), 克隆结束后,进行修复操作
1) 修改IP 2) 修改主机名 3)修改映射文件hosts
检查是否满足条件:
环境准备⼯作:
1、安装了jdk
2、设置host映射
192.168.32.128 bigdata01
192.168.32.129 bigdata02
192.168.32.130 bigdata03
远程拷贝:(如果三台服务器都已经配置过了,就不需要远程拷贝了)
scp -r /etc/hosts root@bigdata02:/etc/
scp -r /etc/hosts root@bigdata03:/etc/
3、免密登录
bigdata01 免密登录到bigdata01 bigdata02 bigdata03
ssh-copy-id bigdata03
4、第一台安装了hadoop
先不要急着拷贝,因为后面需要修改 bigdata01 上的 hadoop
5、关闭了防⽕墙
systemctl status firewalld
6、修改linux的⼀个安全机制
vi /etc/selinux/config
修改⾥⾯的 SELINUX=disabled
2、检查各项内容是否到位
如果以前安装的有伪分布模式,服务要关闭。 stop-dfs.sh
3、修改bigdata01配置文件
路径:/opt/installs/hadoop/etc/hadoop
core-site.xml
<configuration>
<!-- 设置namenode节点 -->
<!-- 注意: hadoop1.x时代默认端⼝9000 hadoop2.x时代默认端⼝8020 hadoop3.x时 代默认端⼝ 9820 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata01:9820</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的⼀个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/installs/hadoop/tmp</value>
</property>
</configuration>hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--secondarynamenode守护进程的http地址:主机名和端⼝号。参考守护进程布局 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata02:9868</value>
</property>
<!-- namenode守护进程的http地址:主机名和端⼝号。参考守护进程布局 -->
<property>
<name>dfs.namenode.http-address</name>
<value>bigdata01:9870</value>
</property>
</configuration>hadoop-env.sh
export JAVA_HOME=/opt/installs/jdk
# Hadoop3中,需要添加如下配置,设置启动集群⻆⾊的⽤户是谁
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root修改workers
bigdata01
bigdata02
bigdata03修改完了第一台的配置文件,开始分发到其他两台上去。
假如以前没有将bigdata01上的hadoop 拷贝给 02 和 03
那么就远程拷贝:
scp -r /opt/installs/hadoop/ root@bigdata02:/opt/installs/
scp -r /opt/installs/hadoop/ root@bigdata03:/opt/installs/如果以前已经拷贝过了,只需要拷贝刚修改过的配置文件即可:
只需要复制配置文件即可
拷贝环境变量:
scp -r /etc/profile root@bigdata02:/etc/
scp -r /etc/profile root@bigdata03:/etc/
在02 和 03 上刷新环境变量 source /etc/profile4、格式化namenode
hdfs namenode -format5、启动hdfs
只在第一台电脑上启动
start-dfs.sh启动后jps,看到
| bigdata01 | bigdata02 | bigdata03 |
| namenode | secondaryNameNode | x |
| datanode | datanode | datanode |
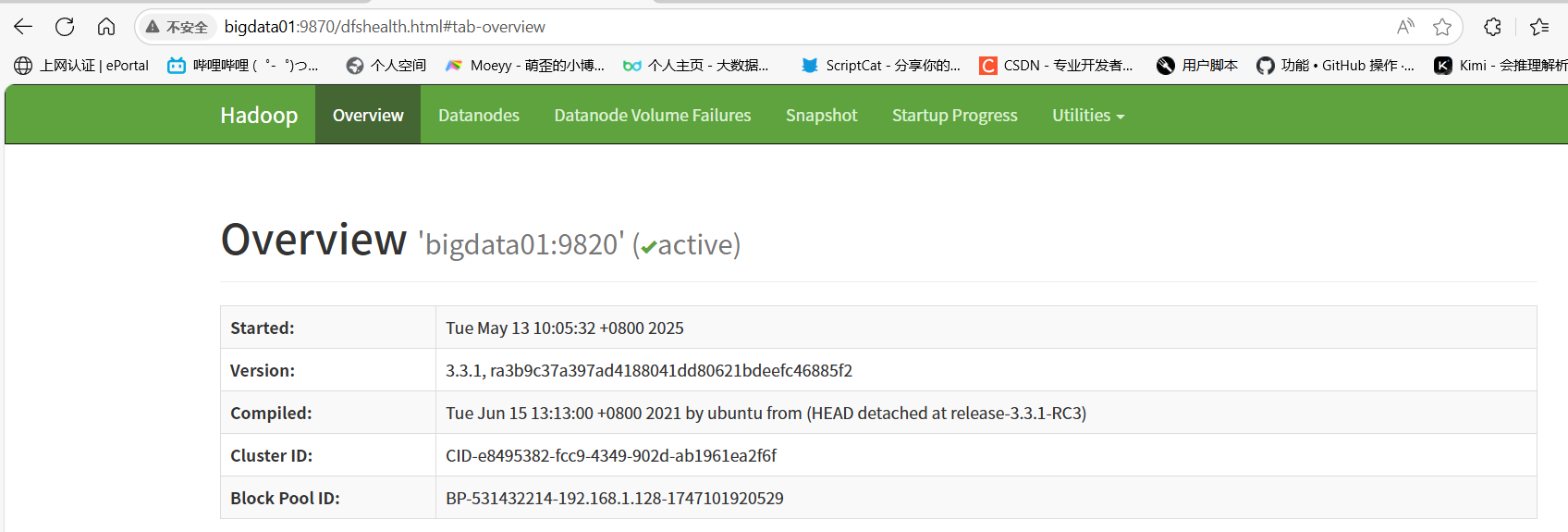
web访问:namenode 在哪一台,就访问哪一台。http://bigdata01:9870
总结:
1、start-dfs.sh 在第一台启动,不意味着只使用了第一台,而是启动了集群。
stop-dfs.sh 其实是关闭了集群
2、一台服务器关闭后再启动,上面的服务是需要重新启动的。
这个时候可以先停止集群,再启动即可。也可以使用单独的命令,启动某一个服务。
hadoop-daemon.sh start namenode # 只开启NameNode
hadoop-daemon.sh start secondarynamenode # 只开启SecondaryNameNode
hadoop-daemon.sh start datanode # 只开启DataNode
hadoop-daemon.sh stop namenode # 只关闭NameNode
hadoop-daemon.sh stop secondarynamenode # 只关闭SecondaryNameNode
hadoop-daemon.sh stop datanode # 只关闭DataNode3、namenode 格式化作用
相当于在整个集群中,进行了初始化,初始化其实就是创建文件夹。创建了什么文件夹:
logs tmp
你的hadoop安装目录下。
















 2442
2442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









