







这里介绍机器学习中最简单的一种分类方法:感知机模型。
感知机模型:
其中sign是符号函数,w和b是参数,x是输入特征向量,f(x)返回决策结果。
分离超平面S:
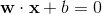
对于二类线性可分问题,分离超平面将两类样本分在S两侧。
空间中一点x0到S的距离:
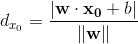
损失函数:
定义损失函数的意义是所有误分类的点到分离超平面的距离之和最小,如果是线性可分问题,则该距离之和为0。
设误分类的点的集合为M,某误分类点xm到S的距离为:
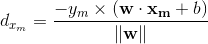
所以可得损失函数(优化目标)为:
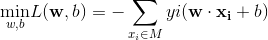
梯度下降法求解w和b:
使用经典的梯度下降法求解最优化问题。
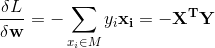
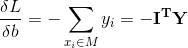
(一般梯度下降法有两种选择:批量梯度下降和随机梯度下降。批量梯度下降就是使用上述公式,可以得到全局最优解(也不一定哦),但是当数据量很大时,批量梯度下降会非常慢,因为每次迭代都要使用全部的数据进行计算;而相应的,随机梯度下降每次迭代只使用一个样本数据,速度快,但是不够鲁棒,不一定可以得到最优解。)
这里使用随机梯度下降的方案,即每次只使用一个样本对参数进行更新:
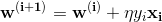
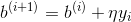
对于二类线性可分问题,上述随机梯度下降过程是可以证明收敛的,经过若干次迭代即可以求出分离超平面S,即决策函数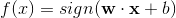
感知机学习算法的对偶问题:
为什么要提感知机学习算法的对偶问题呢?因为感知机是SVM的基础,并且感知机学习算法和其对偶算法与SVM学习算法和其对偶算法有对应关系,感知机学习算法的对偶算法相对比较容易理解!
对偶算法的思想是:将w和b表示为实例xi和标记yi的线性组合的形式,通过求解其系数而求得w和b。
在上述随机梯度下降的迭代过程中,即:
如果令w和b的初值为0,则可以将最终w和b的值表示成以下形式:
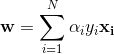
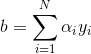
其中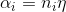
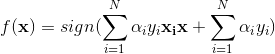
可以看出,只要求出a,就可以求出决策函数。
具体的感知机对偶学习算法如下:
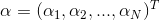
(1)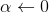
(2)在训练数据集中选取数据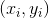
(3)如果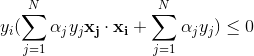
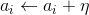
(4)转(2),直到没有误分类的数据。
注意在(3)中出现的内积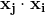















 913
913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









