







利用python进行分类-预测顾客流失(简版)

更新内容:第4点c方式
计算准确率的方式(用了sklearn方式)
由于每个算法都基于某些特定的假设,且均含有某些缺点,因此需要通过大量的实践为特定的问题选择合适的算法。可以这么说:没有任何一种分类器可以在所有的情况下都有良好的表现。
分类器的性能,计算能力,预测能力在很大程度上都依赖于用于模型的相关数据。训练机器学习算法涉及到五个主要的步骤:
- 1.特征的选择
- 2.确定性能评价标准
- 3.选择分类器及其优化算法
- 4.对模型性能的评估
- 5.算法的调优
写在前面:接下来的我们通过一些电信数据来看看一些常用的分类器的简单情况(默认参数),通过这些分类器来预测客户是否会流失。这次是一些比较简单的做法,有空再来完善,比如超参调优等。
1.加载数据
数据下载链接https://pan.baidu.com/s/1bp8nloV
import pandas as pd
data = pd.read_csv("customer_churn.csv",header=0,index_col=0)
data.head()
但是在读取的过程中出现了如下错误:
OSError:Initializing from file failed
查看了源码,应该是调用pandas的read_csv()方法时,默认使用C engine作为parser engine,而当文件名中含有中文的时候,用C engine在部分情况下就会出错
所以解决方案有二:
- 1.将文件路径的中文替换掉
- 2.在read_csv中加入engine=‘python’参数,即:
data = pd.read_csv("C:\\Users\\Administrator\\OneDrive\\公开\\customer_churn.csv",header=0,index_col=0,engine='python')
2.查看数据
data.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 3333 entries, 1 to 3333
Data columns (total 20 columns):
state 3333 non-null object
account_length 3333 non-null int64
area_code 3333 non-null object
international_plan 3333 non-null object
voice_mail_plan 3333 non-null object
number_vmail_messages 3333 non-null int64
total_day_minutes 3333 non-null float64
total_day_calls 3333 non-null int64
total_day_charge 3333 non-null float64
total_eve_minutes 3333 non-null float64
total_eve_calls 3333 non-null int64
total_eve_charge 3333 non-null float64
total_night_minutes 3333 non-null float64
total_night_calls 3333 non-null int64
total_night_charge 3333 non-null float64
total_intl_minutes 3333 non-null float64
total_intl_calls 3333 non-null int64
total_intl_charge 3333 non-null float64
number_customer_service_calls 3333 non-null int64
churn 3333 non-null object
dtypes: float64(8), int64(7), object(5)
memory usage: 546.8+ KB
3.特征选取
特征其实就是属性、字段等的意思
我们这里采取比较简单的方式,直接将state 、account_length 、area_code 这三列去掉,因为和是否流失的关系不大
data = data.ix[:,3:]
data.head()
4.将标称特征的值转换为整数,方便算法的运算
这里的话我们有三种方式
- a.
var = ['international_plan', 'voice_mail_plan','churn']
for v in var:
data[v] = data[v].map(lambda a:1 if a=='yes' else 0)
- b
#可以用字典的方式
data = pd.read_csv("customer_churn.csv",header=0,index_col=0,engine='python')
data = data.ix[:,3:]
mapping = {'yes':1,'no':0}
var = ['international_plan', 'voice_mail_plan','churn']
for v in var:
data[v] = data[v].map(mapping)
- c
#或者也可以使用sklearn里的LabelEncoder类
from sklearn.preprocessing import LabelEncoder
data = pd.read_csv("customer_churn.csv",header=0,index_col=0,engine='python')
data = data.ix[:,3:]
le = LabelEncoder()
var = ['international_plan', 'voice_mail_plan','churn']
for v in var:
data[v] = le.fit_transform(data[v])
data[var].head()
c方式我们可以用以下方式得出将yes和no分别转换成了什么整数
le.transform(['yes','no'])
结果
array([1, 0], dtype=int64)
5.将数据分为测试集和训练集
X=data.ix[:,:-1]
y=data.ix[:,-1]
from sklearn.cross_validation import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=0)
6.1使用决策树进行分类
#使用决策树
from sklearn import tree
clf = tree.DecisionTreeClassifier(max_depth=3)
clf.fit(X_train,y_train)
我们可以通过以下方式将决策树的图导出来,只是在python上相对R来说要麻烦一点,需要下载Graphviz软件,并将其安装目录下的bin文件夹设置在系统变量中
#将决策树的决策过程导出到当前代码文件所在文件夹
tree.export_graphviz(clf,out_file='tree3.dot')
再在cmd中输入以下命令,将dot文件转换为png文件
dot -T png tree.dot -o tree.png
因为本人用的是jupyter notebook,所以要想在jupyter notebookz中插入图片的话,得用以下命令
%pylab inline
from IPython.display import Image
Image("tree.png")
结果如下
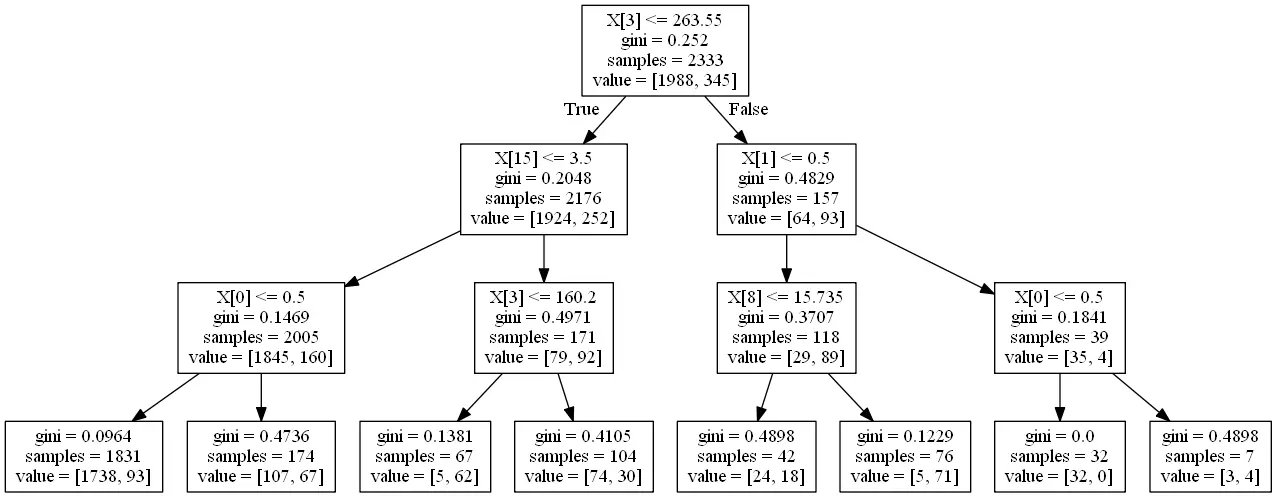
可以看到决策树最先是以训练集中的第3列特征进行分支的
#检测分类结果
import numpy as np
print("Test accuracy:%.3f" %(np.sum(y_test==clf.predict(X_test))/len(y_test)))
结果为:Test accuracy:0.910
我们可以利用sklearn里面的东西直接计算准确率
#1
print("Test accuracy:%.3f" % clf.score(X_test,y_test))
#2
from sklearn.metrics import accuracy_score
print("Test accuracy:%.3f" % accuracy_score(y_test,clf.predict(X_test)))
结果同样都为0.910
6.2逻辑回归
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression()
clf.fit(X_train,y_train)
print("Test accuracy:%.3f" % clf.score(X_test,y_test))
结果为:Test accuracy:0.870
6.3支持向量机
#使用支持向量机
from sklearn.svm import SVC
clf = SVC()
clf.fit(X_train,y_train)
print("Test accuracy:%.3f" % clf.score(X_test,y_test))
结果为:Test accuracy:0.862
写在最后:从准确率上看,这份数据决策树分类器的泛化能力最好,但是我们这里用的是各个分类器的默认参数,没有进行相关检验,调优,所以目前的结果并不可信,也不能完全按照准确率去比较分类器的优劣















 3192
3192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









