







❀前言:
(1)本次分析流程基于一篇文献的复现,将以其中一个样本为例完成整个chip-seq流程的分析;
(2)文献参考:MLL2 conveys transcription-independent H3K4 trimethylation in oocytes文献链接![]() https://www.nature.com/articles/s41594-017-0013-5(3)文章原始数据参考:来自GEO数据库;文章原始数据参考
https://www.nature.com/articles/s41594-017-0013-5(3)文章原始数据参考:来自GEO数据库;文章原始数据参考![]() https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE93941
https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE93941
(4)以d5_NGO_H3K4me3和d5_NGO_input为例;NGO表示未生长的卵母细胞;
H3K4me3为组蛋白H3K4的三甲基化,是最重要的甲基化修饰之一;
input即代表空白对照组,即未经抗体处理的对照样本,用于排除背景信号的影响;
一、文献数据下载:
(本分析从sra数据开始,也可从fastq文件开始;sra 文件是一种专门用于存储原始测序数据的二进制格式,而 fastq文件是一种通用的文本格式,用于存储测序读数及其相应的质量信息;简单来说就是sra数据未经处理,而fastq数据则被进行了部分处理)
(1)查找样本sra序号:点击GSM2465447
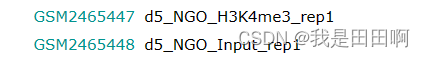
(2)鼠标滑到下面,找到SRX序号:
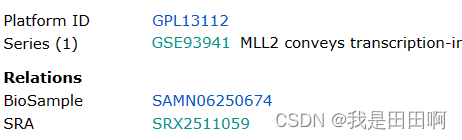
(3)点击后,鼠标再次滑到最下面,找到SRR序号:
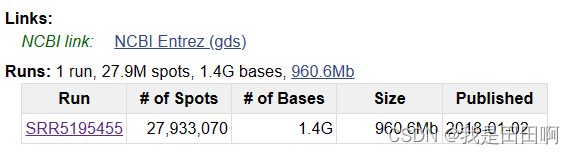
(4)使用命令行下载文件:(其余文件同理)
prefetch https://sra-pub-run-odp.s3.amazonaws.com/sra/SRR5195455/SRR5195455(4.1)温馨提示:可以使用nohup命令将数据的下载挂在后台,防止突然断连:
nohup prefetch https://sra-pub-run-odp.s3.amazonaws.com/sra/SRR5195455/SRR5195455 &(4.2)如果nohup命令使用效果不好,可以使用screen命令:(详细用法也可再自行学习)
screen -S name ##name可自定义,回车后即可正常输入以下命令:
prefetch https://sra-pub-run-odp.s3.amazonaws.com/sra/SRR5195455/SRR5195455
##快捷键 ctrl+a+d:退出当前窗口二、获得样本信息:
(1)平台信息为:(获取SRR序号时的页面)

(2)获取平台信息:
esearch -db sra -query PRJNA362876 | efetch -format runinfo > runinfo.csv(2.1)esearch命令:是 NCBI(美国国家生物技术信息中心)提供的一个用于在其数据库中进行检索的命令行工具;以下为使用用法:
esearch -db sra -query your_search_terms | efetch -format runinfo
- esearch: 启动检索命令。
- -db sra:指定要在哪个 NCBI 数据库中进行检索,这里是 sra 数据库。
- -query your_search_terms:指定要搜索的关键词或查询条件,将 your_search_terms"替换为实际的搜索条件。
- |: 管道符,将 esearch 的输出传递给下一个命令。
- efetch -format runinfo:使用 efetch 命令检索并以runinfo格式显示结果。
- > runinfo.csv 则表示将输出结果写入runinfo.csv文件。
(2.2)得到runinfo.csv格式文件后需要保留所需样本信息,删除不需要的信息:目前只探索到了一个比较“foolish”的办法:即使用vim文本编辑器进行编辑,具体用法比较简单基础,网络上很多资源,大家也可以自行查找。有什么好的方法也可以多多留言呀~~
















 3274
3274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











