







使用Intellij-idea调试Spark-Application
这里的spark application是指需要被submit到spark集群计算环境上运行的job,也就是一个jar包,它虽然有main方法,但是肯定不能以直接在IDEA中右键main函数所在类然后选择debug的方式来调试。因为它不是一个独立的可运行的程序,而是运行云spark集群环境之上,是由另外一个JVM来调用的。就如同调试web程序,把web程序部署在tomcat上后,需要以debug的方式启动tomcat才能调试web程序。因此调试Spark Job的关键就是要以debug的方式启动spark Job将要跑的JVM。
启动一个JVM当然是要有一个主类,使用java命令启动,所以需要找到spark启动的java命令。阅读下spark的bin目录下的各个脚本,可以知道,不管是启动master,还是worker,或者是submit一个job,都是最终会落脚到spark-class脚本的最后1行:
exec "${CMD[@]}"shell变量${CMD[@]}就是最终启动JVM进程的java命令,可以在运行之前把它打印出来:
echo "${CMD[@]}"修改之后,以local模式提交一个job:
/bin/spark-submit \
--class "App" \
--master local[*] \
target/spark-1.0-SNAPSHOT.jar打印出的命令命令类似于:
/home/zoukang/it/java/jdk1.8.0_77/bin/java -cp /home/zoukang/it/spark/spark-home/conf/:/home/zoukang/it/spark/spark-home/lib/spark-assembly-1.6.2-hadoop2.2.0.jar:/home/zoukang/it/hadoop/hadoop-home/etc/hadoop/:/home/zoukang/it/hadoop/hadoop-home/share/hadoop/common/lib/*:/home/zoukang/it/hadoop/hadoop-home/share/hadoop/common/*:/home/zoukang/it/hadoop/hadoop-home/share/hadoop/hdfs/:/home/zoukang/it/hadoop/hadoop-home/share/hadoop/hdfs/lib/*:/home/zoukang/it/hadoop/hadoop-home/share/hadoop/hdfs/*:/home/zoukang/it/hadoop/hadoop-home/share/hadoop/yarn/lib/*:/home/zoukang/it/hadoop/hadoop-home/share/hadoop/yarn/*:/home/zoukang/it/hadoop/hadoop-home/share/hadoop/mapreduce/lib/*:/home/zoukang/it/hadoop/hadoop-home/share/hadoop/mapreduce/*:/home/zoukang/it/hadoop/hadoop-home/contrib/capacity-scheduler/*.jar -Xms1g -Xmx1g org.apache.spark.deploy.SparkSubmit --master local[*] --class com.tmzk.App spark-apps/spark-1.0-SNAPSHOT.jar
可以看出,实际就是运行一个java命令,调试的话我们需要在启动的时候增加调试选项。
-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=20000(使用20000端口,可以指定其他的端口)
修改后的命令就是:
/home/zoukang/it/java/jdk1.8.0_77/bin/java -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=20000 -cp /home/zoukang/it/spark/spark-home/conf/:/home/zoukang/it/spark/spark-home/lib/spark-assembly-1.6.2-hadoop2.2.0.jar:/home/zoukang/it/hadoop/hadoop-home/etc/hadoop/:/home/zoukang/it/hadoop/hadoop-home/share/hadoop/common/lib/*:/home/zoukang/it/hadoop/hadoop-home/share/hadoop/common/*:/home/zoukang/it/hadoop/hadoop-home/share/hadoop/hdfs/:/home/zoukang/it/hadoop/hadoop-home/share/hadoop/hdfs/lib/*:/home/zoukang/it/hadoop/hadoop-home/share/hadoop/hdfs/*:/home/zoukang/it/hadoop/hadoop-home/share/hadoop/yarn/lib/*:/home/zoukang/it/hadoop/hadoop-home/share/hadoop/yarn/*:/home/zoukang/it/hadoop/hadoop-home/share/hadoop/mapreduce/lib/*:/home/zoukang/it/hadoop/hadoop-home/share/hadoop/mapreduce/*:/home/zoukang/it/hadoop/hadoop-home/contrib/capacity-scheduler/*.jar -Xms1g -Xmx1g org.apache.spark.deploy.SparkSubmit --master local[*] --class com.tmzk.App spark-apps/spark-1.0-SNAPSHOT.jar得到这个命令后,我们就不需要通过脚本来启动spark了,在spark机器上直接运行这个命令,会看到:
Listening for transport dt_socket at address: 20000被调试JVM已经准备就绪,下一步就是使用IDEA去调式这个JVM。
我们准备的一个简单的spark app如下:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
public class App {
public static void main( String[] args ) {
String dataFile = "/test.txt";
SparkConf sparkConf = new SparkConf().setAppName("Simple App");
JavaSparkContext sparkContext = new JavaSparkContext(sparkConf);
JavaRDD<String> data = sparkContext.textFile(dataFile).cache();
long numAs = data.filter((String str) -> str.contains("a")).count();
long numBs = data.filter((String str) -> str.contains("b")).count();
System.out.println("Lines with a : " + numAs + " , lines with b : " + numBs);
}
}
在程序开头先打一个断点:
建立一个调试:
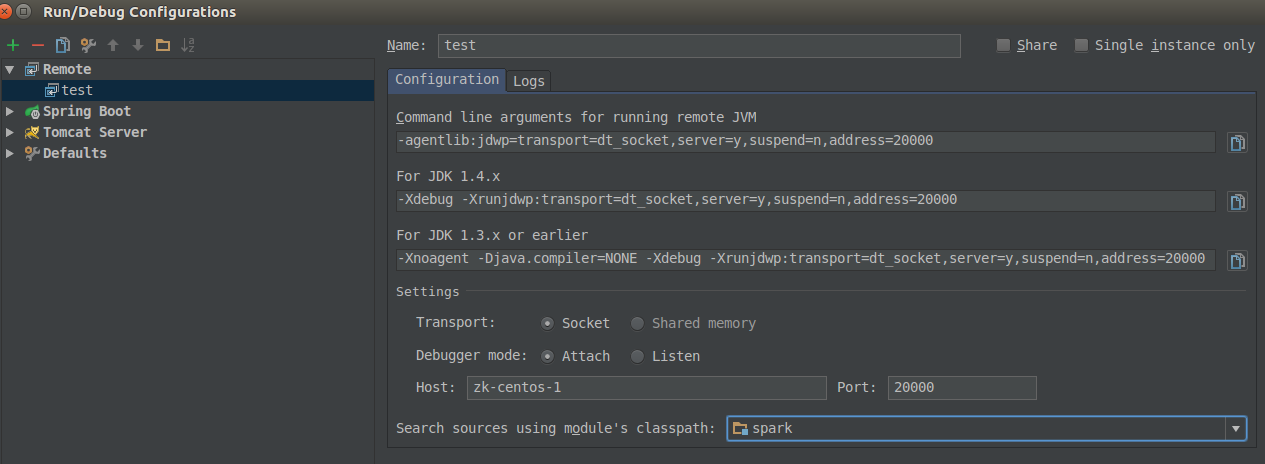
配置:
1.命一个名字
2.配置被调试JVM所在机器的ip或者主机名
3.端口,和启动被调JVM相同,这里为20000端口
4.配置搜寻源码范围
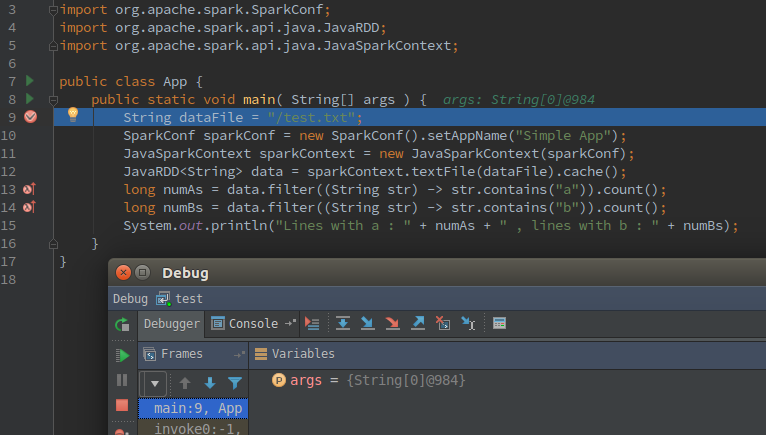
确定之后点击开始调试:

可以看到:
可以愉快的调试spark app了,而不用每次改了代码->加点print语句->打包->submit->查看输出
这里只讨论了一个机器的spark以本地local的模式启动app,对于调试足够了。不怕麻烦的话应该可以已同样的方式使用debug的方式启动spark集群类各个机器上的JVM,然后在IDEA建立多个remote debug,连接到每个被调试的JVM,完全控制每个worker的执行流程。
另外,如果经常需要调试,可以把spark的bin下的脚本复制一份,适当修改以下($RUNNER变量的值)方便以调试的方式启动spark计算环境。















 541
541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









