






Q1: The Relational Model
Q1(a): Write down the relations that directly map the dataset file into a mega table/relation.
REGION (CityId [TEXT], CityCode[TEXT], City [TEXT], Province[TEXT], Total_tickets[INTEGER] )
TIME(TimeId[INTEGER], day [INTEGER], month[INTEGER], year[INTEGER], ddmmyy[TEXT] )
LOG (LogId [INTEGER] , TimeId[INTEGER] , WinnerNum[INTEGER], FirstPrice[INTEGER], CityId [TEXT] )
Q1(b): List the minimal set of Functional Dependencies (FDs) and provide an explanation.
CityId -> CityCode
CityId -> City
CityId -> Province
CityId -> Total_tickets
TimeId is a unique identifier assigned to each day in time
TimeId -> day
TimeId -> month
TimeId -> year
TimeId -> ddmmyy
LogId is the column number of csv
LogId -> TimeID
LogId -> WinnerNum
LogId -> FirstPrice
LogId -> CityId
Q1©: List all potential candidate keys with justification
Because a candidate key contains no redundant attributes, I chose the following attribute as the candidate key:
CityId
CityCode
City
TimeId
Ddmmyy
LogId
Q1(d): Identify a suitable primary key, and justify your decision
CityId
TimeId
LogId
I consider following factors to choose primary key:
- Uniqueness: The primary key should have a unique value for each record in the table.
- Simplicity: A primary key should be simple and easy to understand. The use of complex data types or combinations of fields may make it difficult to manage tables.
- Stability: The primary key should be stable, meaning that it should not change frequently. Changing the primary key of a table may create issues with table relationships or referencing.
- Non-nullability: A primary key must have a value for each record in the table. It cannot have null values.
Q2: Normalization
In this exercise, you will decompose the mega relation into a set of normalized schemas and explain the role of each schema in the database.
You should apply step by step procedure to transform the unnormalized tables created in Q1 to create a normalized database. Each schema must be in the 3rd Normal Form. Please consider the following guidelines while answering the below questions:
Q2(a): List any partial-key dependencies from the mega relation as it stands in the dataset file and any resulting additional relations you should create as part of the decomposition.
For future change total_tickets may have partial-key dependencies, so create a new relations:
REGION (CityId [TEXT], CityCode[TEXT], City [TEXT], Province[TEXT])
TICKETS(CItyId[TEXT], Total_tickets[INTEGER])
TimeId is the primary key in the table, and because the three properties of day, month, and year all depend on TimeId, there is no partial dependency. However, the property ddmmyy only depends on the three properties of day, month, and year, and does not depend on TimeId, so there is a partial key dependency.To eliminate some key dependencies, TimeId and ddmmyy in two separate tables.
TIME(TimeId[INTEGER], day [INTEGER], month[INTEGER], year[INTEGER])
DATE(TimeId[INTEGER], ddmmyy[TEXT])
And similarly,
LOG (LogId [INTEGER] , TimeId[INTEGER] , CityId [TEXT] )
LOGDATA (LogId [INTEGER] , WinnerNum[INTEGER], FirstPrice[INTEGER] )
Q2(b): Convert the relation into 2nd Normal Form using your answer to the above. List the new relations and their fields, types, and keys. Explain the process you took.
REGION (CityId [TEXT], CityCode[TEXT], City [TEXT], Province[TEXT])
TICKETS(CItyId[TEXT], Total_tickets[INTEGER])
TIME(TimeId[INTEGER], day [INTEGER], month[INTEGER], year[INTEGER] )
DATE(TimeId[INTEGER], ddmmyy[TEXT])
LOG (LogId [INTEGER] , TimeId[INTEGER] , CityId [TEXT] )
LOGDATA (LogId [INTEGER] , WinnerNum[INTEGER], FirstPrice[INTEGER] )
Q2©: List any transitive dependencies, if any, in your new relations and justify your answer
In the REGION table, there is a transitive dependency:
CityId → CityCode
CityCode → City
CityId → Province
This means that CityCode and Province are indirectly dependent on the primary key (CityId).
Split it into two tables:
REGION (CityId [TEXT], CityCode [TEXT], City [TEXT])
PROVINCE (CityId [TEXT], Province [TEXT])
And in LOG table, split it into two tables:
LOGTIME (LogId [INTEGER] , TimeId[INTEGER])
LOGCITY (LogId [INTEGER] , CityId [TEXT] )
After the above normalization, none of the tables contain any transitive dependencies.
Q2(d): Convert the relation into 3rd Normal Form using your answers to the above. List the new relations and their fields, types, and keys. Explain the process you took.
REGION (CityId [TEXT], CityCode [TEXT], City [TEXT])
PROVINCE (CityId [TEXT], Province [TEXT])
TICKETS(CItyId[TEXT], Total_tickets[INTEGER])
TIME(TimeId[INTEGER], day [INTEGER], month[INTEGER], year[INTEGER])
DATE(TimeId[INTEGER], ddmmyy[TEXT])
LOGTIME (LogId [INTEGER] , TimeId[INTEGER])
LOGCITY (LogId [INTEGER] , CityId [TEXT] )
LOGDATA (LogId [INTEGER] , WinnerNum[INTEGER], FirstPrice[INTEGER] )
Each table has its own primary key and no non-key attributes depend on other non-key attributes.
Q2(e): Is your relation in Boyce-Codd Normal Form? Justify your answer.
The relation is not in BCNF.
checking for functional dependencies:
TimeId → day, month, year, ddmmyy
These are transitive dependencies, since the attributes on the right-hand side depend on attributes other than the primary key. Therefore, to bring the relation into BCNF, we need to decompose it into smaller relations that satisfy the BCNF conditions.
REGION (CityId [TEXT], CityCode [TEXT], City [TEXT])
PROVINCE (CityId [TEXT], Province [TEXT])
TICKETS(CItyId[TEXT], Total_tickets[INTEGER])
TIMEDAY(TimeId[INTEGER], day [INTEGER])
TIMEMONTH(TimeId[INTEGER], month [INTEGER])
TIMEYEAR(TimeId[INTEGER], year [INTEGER])
DATE(TimeId[INTEGER], ddmmyy[TEXT])
LOGTIME (LogId [INTEGER] , TimeId[INTEGER])
LOGCITY (LogId [INTEGER] , CityId [TEXT] )
LOGDATA (LogId [INTEGER] , WinnerNum[INTEGER], FirstPrice[INTEGER] )
Each of these relations satisfies the condition of having no non-trivial functional dependencies involving only part of a candidate key, and no transitive dependencies. Therefore, the overall relation is in BCNF after this decomposition.
Q3: Database Construction
Q3(a): Import the raw dataset into a single table called ‘dataset’.
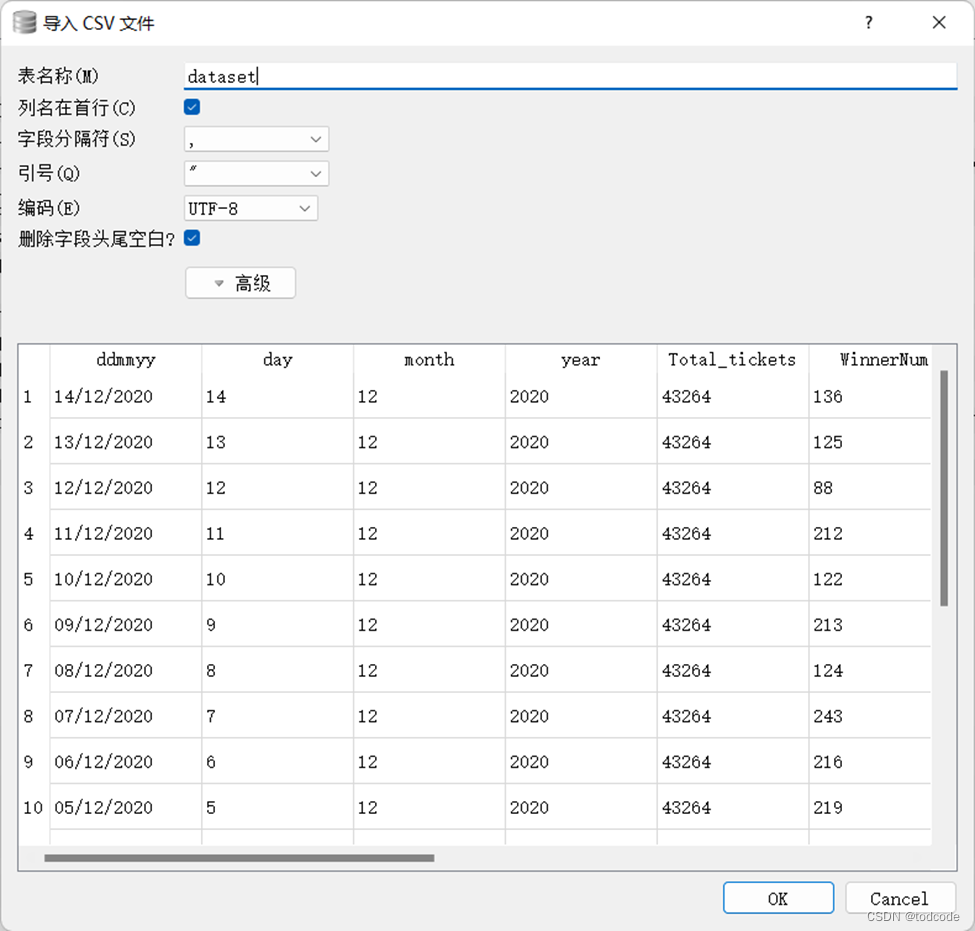
Q3(b): Write the SQL to create the full normalized representation, including all tables as a result of the decomposition process you took for Q2, excluding the mega dataset table.
The SQL should contain CREATE statements to create all new tables. You should include foreign keys where appropriate, and list and justify these in your answer.
REGION (CityId [TEXT], CityCode [TEXT], City [TEXT])
PROVINCE (CityId [TEXT], Province [TEXT])
TICKETS(CItyId[TEXT], Total_tickets[INTEGER])
TIMEDAY(TimeId[INTEGER], day [INTEGER])
TIMEMONTH(TimeId[INTEGER], month [INTEGER])
TIMEYEAR(TimeId[INTEGER], year [INTEGER])
DATE(TimeId[INTEGER], ddmmyy[TEXT])
LOGTIME (LogId [INTEGER] , TimeId[INTEGER])
LOGCITY (LogId [INTEGER] , CityId [TEXT] )
LOGDATA (LogId [INTEGER] , WinnerNum[INTEGER], FirstPrice[INTEGER] )
Q3©: Write INSERT statements using SELECT to populate the new tables from the ‘dataset’ table.
To facilitate import, I added a LogId column to the dataset table and modified the dataset .sql
All you need to do is to run dataset.sql and then run NormalizedData.sql.
Q4: Querying
For each exercise in this question, you will need to write a SQL query against your newly created normalized tables in your database. The queries created over the unnormalized mega dataset table will be considered wrong.
Each SQL statement, explanation, snapshot of results should be written in the report, as well as all queries should be saved in a single file with numbers such as 4a, 4b, and so on, as sqlScript.sql which can be run against your normalized database, as it stands at the end of Q3. You should also briefly describe your approach for each in the report.
Write SQL statement, explanation, and snapshot of results for each of the following questions:
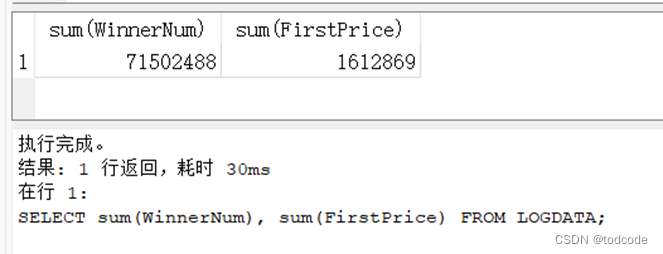
Q4(a): The worldwide total number of winners and first prizes with total winners and total first prizes as columns.
SELECT sum(WinnerNum), sum(FirstPrice) FROM LOGDATA;
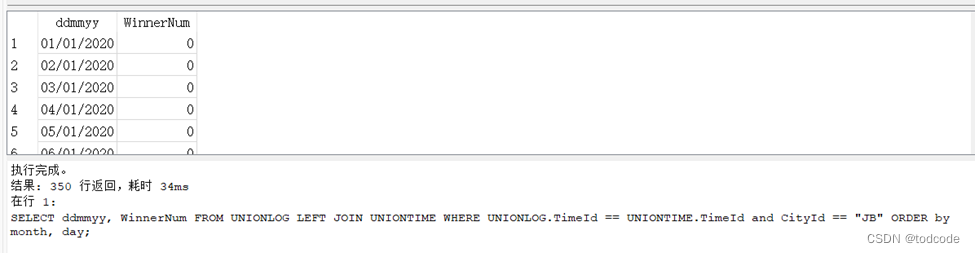
Q4(b): The number of WinnerNum by date, in increasing date order, for the city ‘Jnddanbbrr’ with date and number of WinnerNum as columns.
For the convenience of querying, the following table has been added:
UNIONREGION (CityId [TEXT], CityCode [TEXT], City [TEXT], Province [TEXT], Total_tickets[INTEGER])
UNIONTIME (TimeId[INTEGER], day [INTEGER], month [INTEGER], year [INTEGER], ddmmyy[TEXT] )
UNIONLOG (LogId [INTEGER] , TimeId[INTEGER], CityId [TEXT], WinnerNum[INTEGER], FirstPrice[INTEGER])
SELECT ddmmyy, WinnerNum FROM UNIONLOG LEFT JOIN UNIONTIME WHERE UNIONLOG.TimeId == UNIONTIME.TimeId and CityId == “JB” ORDER by month, day;
Q4©: The total number of winners and first prize by date, in increasing date order, for each province (with the province, date, number of winners, and number of first prize as columns)
SELECT count(WinnerNum), count(Firstprice) FROM UNIONLOG LEFT JOIN UNIONTIME on UNIONLOG.TimeId == UNIONTIME.TimeId LEFT JOIN Province on province.CityId == UNIONLOG.CityId GROUP by Province ORDER by month, day;

Q4(d): The number of winners and first prizes as a percentage of the Total_tickets, for each city (with
city, % winner of total scratch-off (lottery) tickets, % first prize of total scratch-off (lottery) tickets as columns).
SELECT City, WinnerNum * 1.0 / Total_tickets, FirstPrice * 1.0 / Total_tickets FROM UNIONLOG left join UNIONREGION on UNIONLOG.CityId == UNIONREGION.CityId;
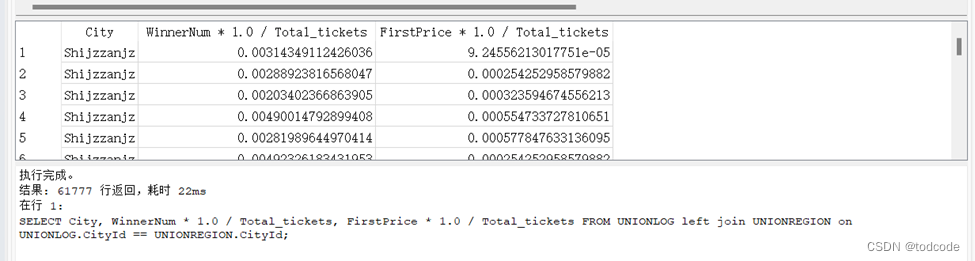
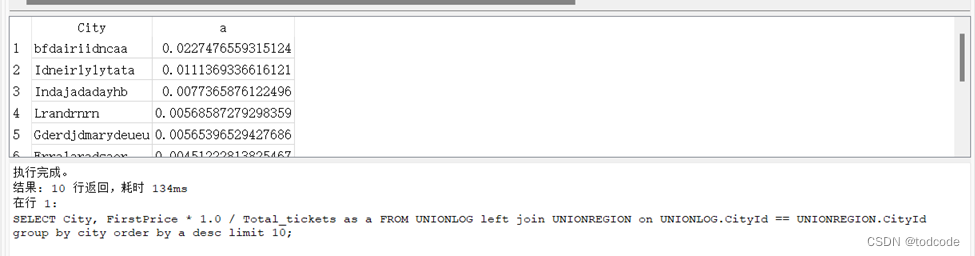
Q4(e): A descending list of the top 10 cities, by percentage total first prizes out of total scratch-off (lottery) tickets in that city (with city name, and % first prizes of city scratch-off (lottery) tickets as columns)
SELECT City, FirstPrice * 1.0 / Total_tickets as a FROM UNIONLOG left join UNIONREGION on UNIONLOG.CityId == UNIONREGION.CityId group by city order by a desc limit 10;
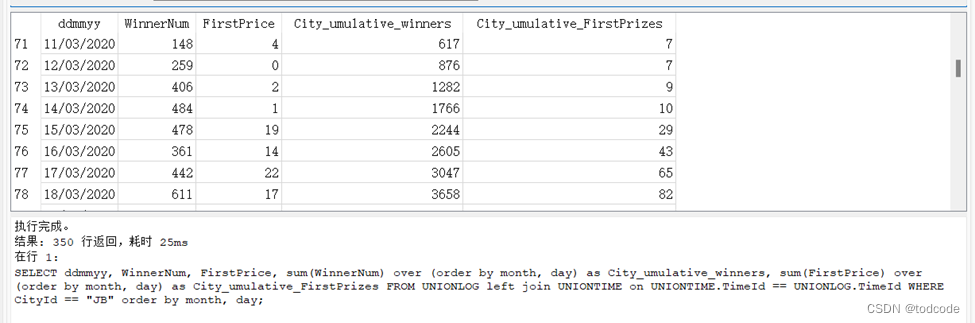
Q4(f): The date against a cumulative running total of the number of first prizes by day and winners by day for the city ‘Jnddanbbrr‘ (i.e. date, City_daily_winners, City_cumulative_winners, City_daily_FirstPrizes, and City_umulative_FirstPrizes as columns)
SELECT ddmmyy, WinnerNum, FirstPrice, sum(WinnerNum) over (order by month, day) as City_umulative_winners, sum(FirstPrice) over (order by month, day) as City_umulative_FirstPrizes FROM UNIONLOG left join UNIONTIME on UNIONTIME.TimeId == UNIONLOG.TimeId WHERE CityId == “JB” order by month, day;
Q5: Visualization
Q5(a): Write a SQL script to plot the top 10 cities in terms of overall cumulative first prizes only. Include an explanation of your script in the report.
SELECT City, sum(FirstPrice) as cumulate_firstprize FROM REGION LEFT JOIN UNIONLOG on REGION.CityId == UNIONLOG.CityId GROUP by City order by cumulate_firstprize desc limit 10;
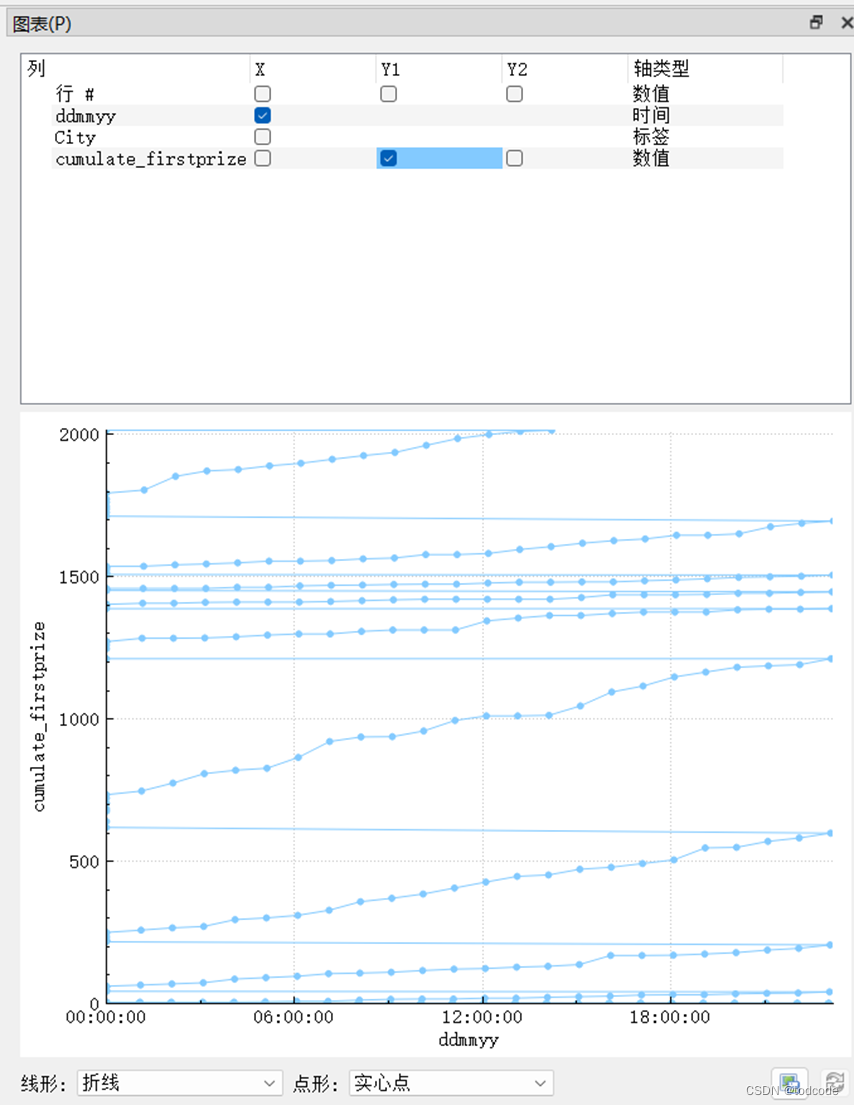
Q5(b): Produce a graph that has a date on the horizontal axis and the cumulative number of first prizes by city on the vertical axis. You should represent the top 10 cities in terms of overall cumulative first prizes only.
The full script and resulting screenshot of the graph should be included in the report.
SELECT ddmmyy, city, sum(FirstPrice) over (order by month, day) as cumulate_firstprize FROM UNIONLOG LEFT JOIN REGION on REGION.CityId == UNIONLOG.CityId LEFT JOIN UNIONTIME on UNIONTIME.TimeId == UNIONLOG.TimeId GROUP by UNIONLOG.TimeId order by month, day;
Q5: Visualization
Q5(a): Write a SQL script to plot the top 10 cities in terms of overall cumulative first prizes only. Include an explanation of your script in the report.
SELECT City, sum(FirstPrice) as cumulate_firstprize FROM REGION LEFT JOIN UNIONLOG on REGION.CityId == UNIONLOG.CityId GROUP by City order by cumulate_firstprize desc limit 10;
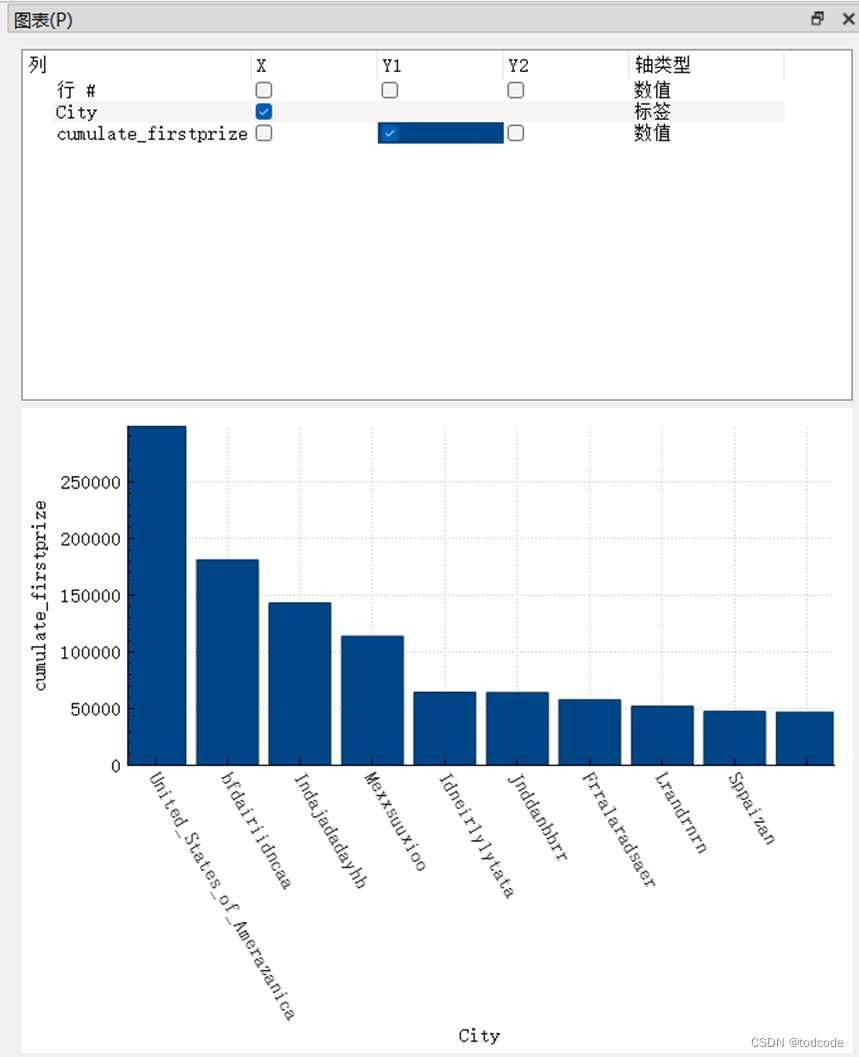
Q5(b): Produce a graph that has a date on the horizontal axis and the cumulative number of first prizes by city on the vertical axis. You should represent the top 10 cities in terms of overall cumulative first prizes only.
The full script and resulting screenshot of the graph should be included in the report.
SELECT ddmmyy, city, sum(FirstPrice) over (order by month, day) as cumulate_firstprize FROM UNIONLOG LEFT JOIN REGION on REGION.CityId == UNIONLOG.CityId LEFT JOIN UNIONTIME on UNIONTIME.TimeId == UNIONLOG.TimeId GROUP by UNIONLOG.TimeId order by month, day;















 2942
2942











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









