










视频地址: https://www.bilibili.com/video/BV1924y1y7jN
221115上午10点的时候客户反应进入小程序慢,打开监控发现服务pv已经超过了历史之最(印象中最高的是100w),这次到了400w。原因是因为推广了一个发红包的活动。
数据体现
最终pv峰值达到了 400w/小时,5分钟峰值 60w, 1分钟峰值 12w,单个服务1分钟峰值 4.6w

整体数据面板

接口访问排行榜
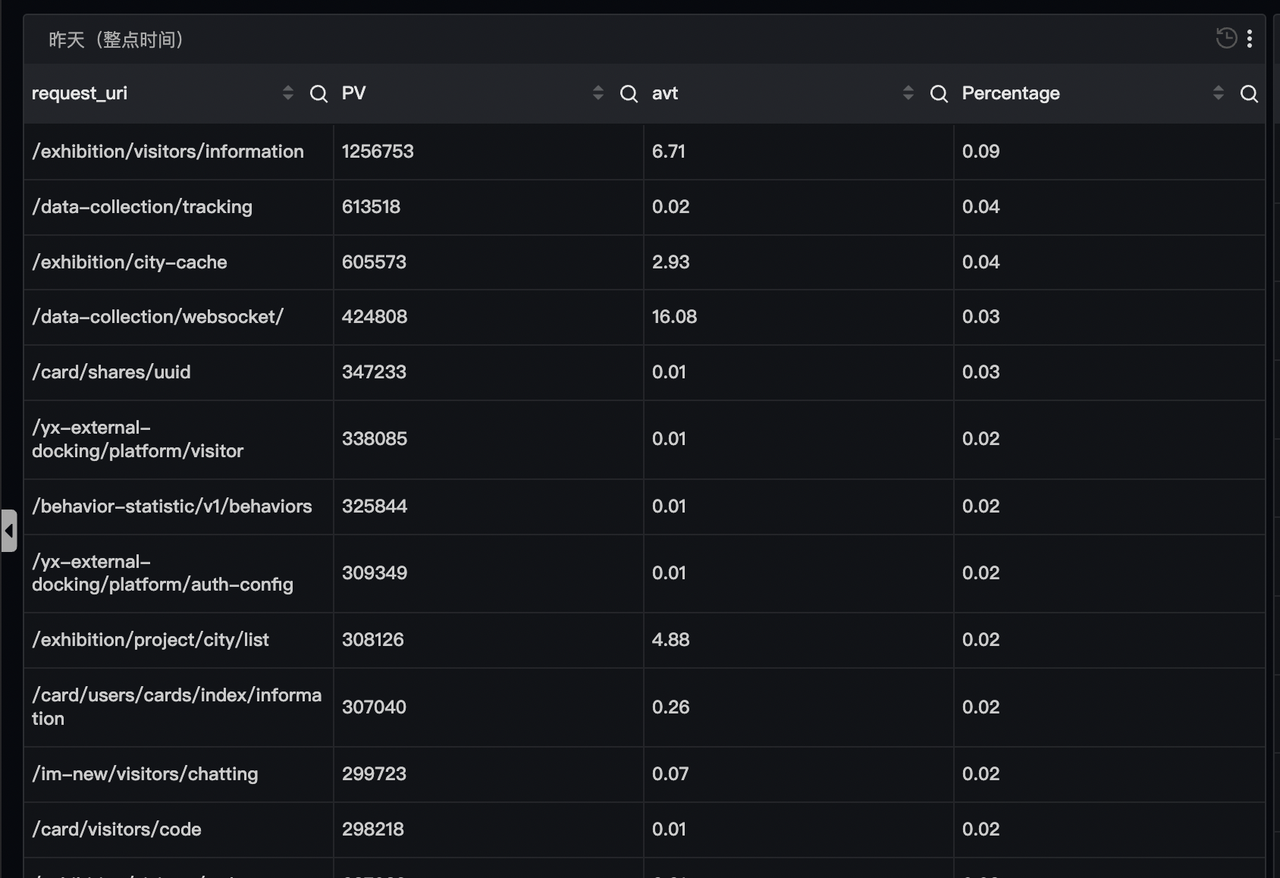
一分钟峰值
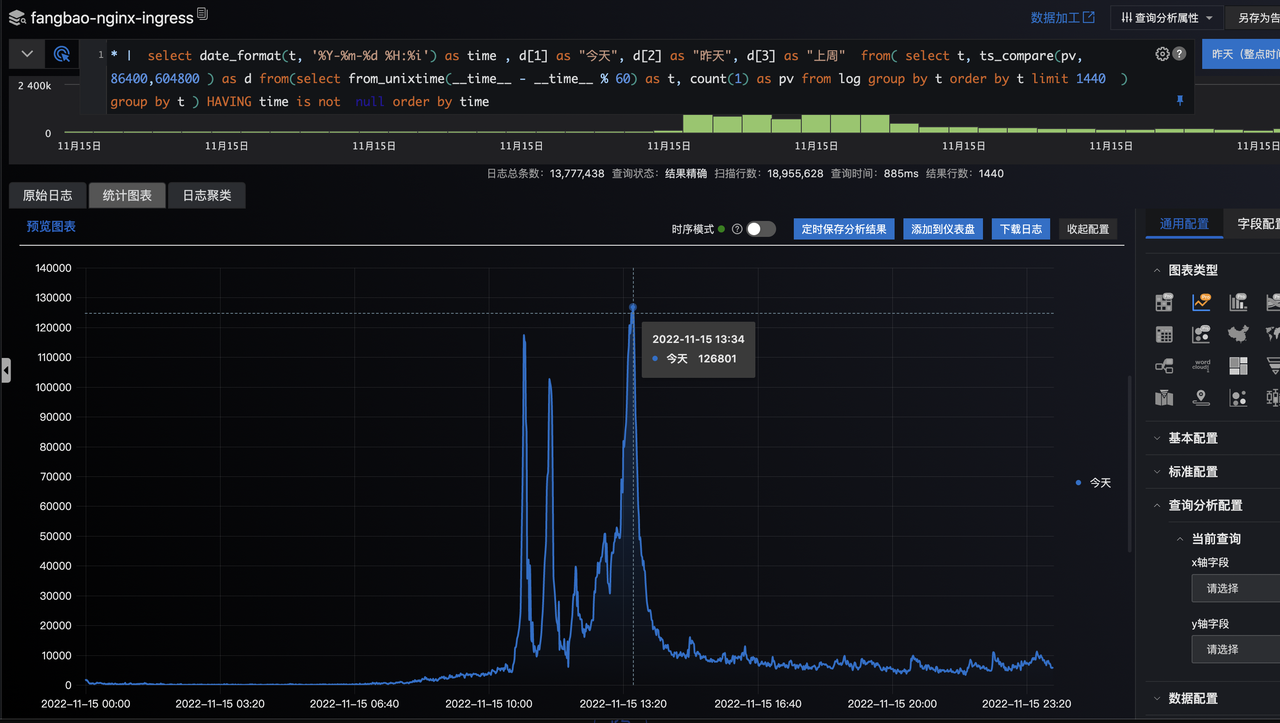
一分钟 exhibition峰值

exhibition 承受的压力
一天整体的访问量是 1377w, exhibition 510w


问题现象
我们后台大概有50多个服务,其实有一个服务是 exhibition,承载了C端用户的主要访问量,exhibition 服务一直重启,我们把节点从 12个扩容到28个依旧扛不住压力。
其它服务的 pod都是看似正常的,exhibition 服务的表象是 pod一直在重启。
问题排查
1、排查所有其它服务
主要是用来判断下游服务是否已经宕机了,其它服务的 pod都是正常,也没有重启,然后就跳过这项。

2、排查压力原因
我们使用的是阿里云的数据库,有很好的监控,查看数据库的压力都很小,cpu 在50%的样子,然后我就把 pod节点从 12、16、20、28, 但是用依旧扛不住。
3、热点接口问题排查
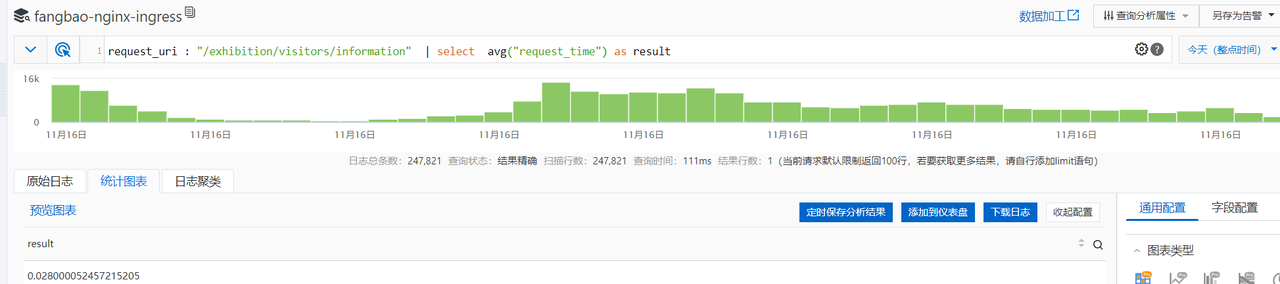
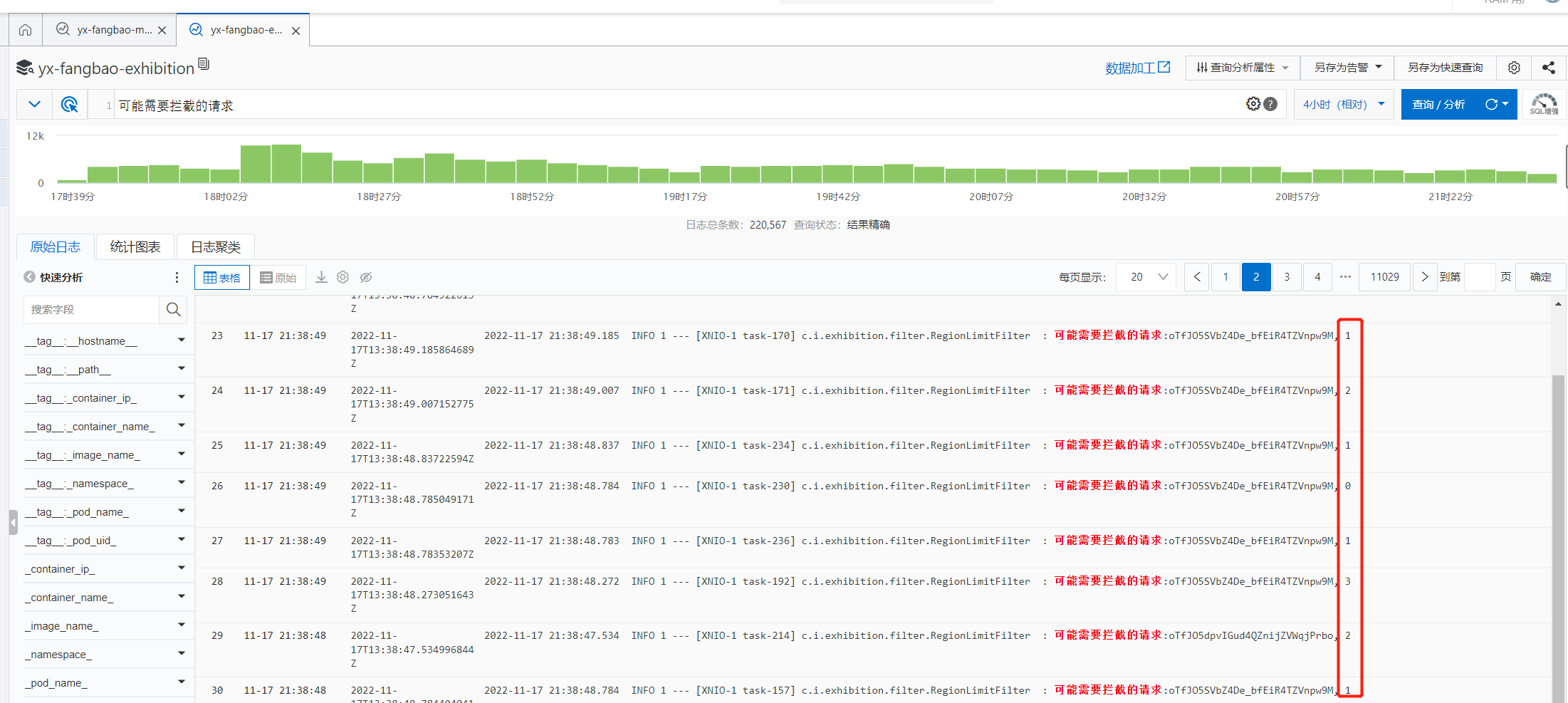
请求最多的接口是 /information 接口,平均响应时间到了 8s+, 仔细看了这个接口却发现也没法优化,因为在正常的时候,它是没问题的,下面是前天和今天的数据
接口平均时间都是在 0.3s 以下

4、连接池排查
我们的服务里面配置了 256个工作线程,但是数据库连接池里面的只配置了50,遂即调到了 200,但是用依旧扛不住。 (ps:这时候的数据库也没有达到顶峰)
server:
undertow:
io-threads: 16
worker-threads: 256
5、结果
到了 13.40的时候流量慢慢下来了,这个时候服务也就恢复了正常,但这不是结束,客户说周四的晚上还会推一波流量,所以就有了我们下面的优化。
另外可能很多人第一反应就是限流,我们也做了,如果不限流一个 pod都起不来,以前对于限流也没有什么思考,现在觉得:限流的第一步是要考虑你的系统最大并发量,不然限流就是个借口。
exhibition 服务在1.5w/min 的时候就开始挂机,顶峰4.5w, 或许我们的服务达不到4.5w,但绝对不会是1.5w。
总结:系统优化
其实很简单,承受大部分流程的就是这个 exhibition 服务,我们要保证它的可用性,要找到它短板,并准备好限流策略。
下面是阿里云的 EDAS全链路追踪工具,通过这个工具,我们可以看到一次请求的全链路,每一个步骤的耗时


优化的手段主要是
- 通过 EADS 去找热点接口超时的数据,分析超时的原因
- 去看异常采集服务都抛出了些什么异常
- 脑子思考
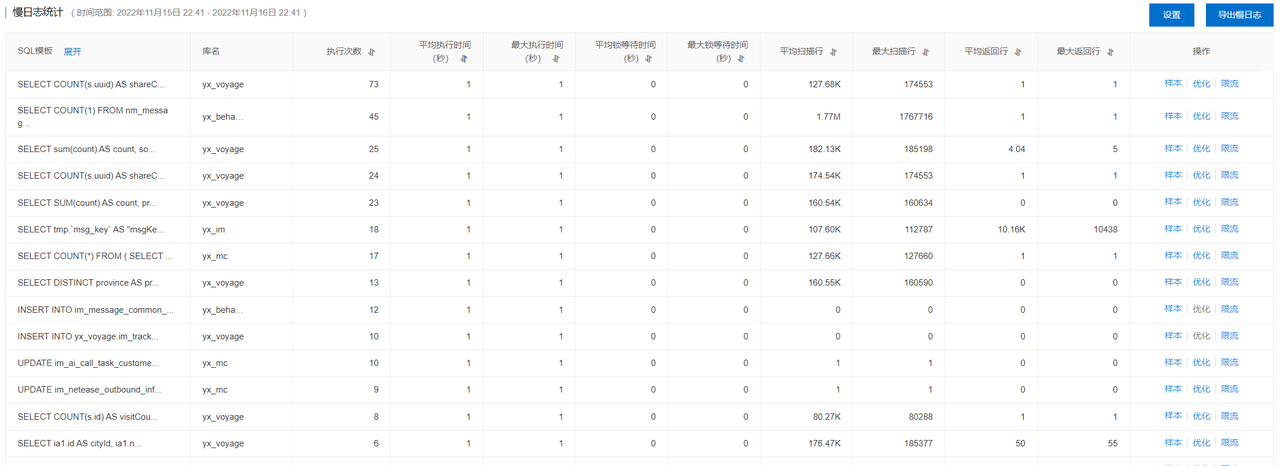
1、慢SQL
慢sql一定是要优化的,这是致命的,并发一大将会全部阻塞。在这之前我们已经做过一轮的慢sql的优化了,并且复杂的查询都已经迁移到 ADB大数据库里面了。
因为是使用阿里云的数据库,所以可以直接查看哪些是慢sql,简单的sql它可以直接给出优化。

2、热点接口优化
上面说到我们的热点接口是 information 接口,正常情况它是没什么性能问题的,但也经不住调用次数那么多。
ps:热点接口一定一定不能是慢sql,不然就死定了,这个接口我们优化过,所以不属于慢接口。
解决办法:
- 从业务出发让前端做本地缓存,减少调用的次数。
3、下游服务超时
通过观察日志、EDAS分析,我们发现有很多的下游服务宕机了
- 基础SDK,我们有基于单表的增删改查SDK
- 错误采集服务
- 飞书通知
日志中可以看到很多调用这三个服务超时的问题,但是我们也检查过我们的基础SDK和错误采集服务,为什么没发现呢?
基础SDK和错误采集服务都是些基础的新增查询操作,它们的pod节点很少,但是服务也没有挂,所以我们检查 pod的时候发现它们都是正常运行,并且没有重启。
原因很简单,它们的工作线程都已经满了,新来的任务都进去了队列等待,队列满了就会拒绝,但是在队列中的请求就会耗时很长,甚至超时,而我们的exhibition服务一直在等它们返回就造成线程阻塞。
基础SDK和错误采集服务不会宕机的原因是因为它是正常工作的,没有内存不足,只是排队工作而言。
exhibition 服务宕机的原因,是因为我们配置了存活检测机制,当连续3次请求服务都得不到结果的时候就会重启,而我们256个工作线程都在工作或者阻塞了,没有线程来处理我们的存活检测,导致存活不过就被重启了。

至于飞书通知就没什么好说了,第三方的工具,一样的先进入队列,然后开始拒绝,队列的就阻塞了。
解决办法:
- 下游服务也跟着扩容,并加上存活检测,及时发现瓶颈
- 去掉飞书通知
4、内部服务调用整改
服务多了,内部之间的调用也会很多,大多数人都会选择使用 域名的方式去调用,但这样其实会走一遍外网会耗时更多也可能被防火墙拦截,而昨天通过 域名调用的次数有 43w

解决办法:
- 统一改成 k8s内部端点 访问
5、连接池
之前我们的MySQL连接池配置的是 50,但是服务的工作线程是256,也匹配把MySQL的连接池配置到 200。
Redis 连接池,之前redis连接池也是50个,现在也改成了200,线上redis支持的连接数是2w个。
6、Redis 慢日志
Redis也是使用的阿里云的,发现也会有不少的慢日志,如果是发生在高并发的时候也是致命的,查看了发现是因为一个操作使用 keys 命令,全表扫描了。

解决办法:
- 找到具体的地方,去掉这个操作,设置过期时间不去使用 keys 命令
7、内部接口逻辑处理慢
有一个给用户发消息的接口,这是一个个循环消息推送,需要组装数据和调用第三方接口
解决办法:
接口做成异步去调用,设置单独的一个线程池,并且设置好线程数、拒绝策略、阻塞队列的大小
N、接口限流
除了做优化本身我们也做了限流策略,用来做兜底。
N-1、基于城市限流
我们有 550w的 openId,其中有手机号的有289w,通过阿里云的归属地查询接口把这289w的数据全部洗到一张表里面,策略就是 保新弃旧

status = 1 就标识限制不能请求,这时候我们会返回http状态为 401,前端接收到了就会给一个友好的提示。
限流的代码也很简单,就是写一个过滤器 (比拦截器好,从过滤器到拦截器这中间要做很多事情,没必要)

这里其实还有2个问题
- 这个查询的SQL性能如何
- 限流策略如何精确
当我创建完这张表的时候,我查询了一下这个SQL,耗时在 60-80ms 之间
SELECT open_id FROM im_region_limit_rule WHERE open_id = 'oTfJO5XKWeMfwOGzsJeU6DcBBBUY' AND status = 1
对于将近300w的数据表来说,好像也还不错了?(已经创建了 openId + status 的联合索引,并且不需要回表,执行分析也是 row = 1),但在高并发情况依旧是不行,后面尝试了很多的策略都不行,
- 比如修改索引为 hash
- 修改引擎为 MyISAM
最后没办法上到线上一看,平均耗时当在 2ms 左右,所有猜想 Navicat 这类的工具主要是耗时在了创建和释放连接上了,而我们的代码是有连接池的
这样简单推算一下,我们数据库16核的,2个节点,工作线程有 64个
2 ms/次 * 64线程 * 500 = 64000次/秒
表很简单,限流策略也很简单,但是如果你的服务被击溃了,你的脑子将是混沌的,思考能力急速下降,流量是花钱投放来了,这时候的时间就等于金钱了,为了最高效的解决问题,其实我们应该提前去把限流的脚本写好,到时候按照批次执行就好了,这里我准备了三个SQL
- 有的手机号是异常手机号查询不到归属地的,第一步限流 —— 26w
- 越秀在全国25个城市有楼盘,限流掉非这25个城市的手机号 —— 134w
- 越秀的总部在广州,我们在深圳,限流掉非这两个城市的数据 —— 214w
N-2、基于ip限流
第一步是上面的城市限流,如果第一步还是扛不住的话,那就需要第二步了。
原理差不多,也是把访问的ip、访问次数、访问地域存到一个表里面去,每分钟异步更新一下数据,然后去实时查询
- 先是限流非 25个楼盘的城市ip
- 再是限流非广州和深圳的ip
- 限流深圳访问大的ip
- 限流广州访问量小的 ip (为什么呢?因为越秀总部在广州,大的访问量应该在他们那里,如果他们领导打不开,那就完蛋)
虽然策略差不多,但是这里的实现思路变了,变得更有趣了,不再是代码侵入式了。
k8s里面有个组件是 路由Ingress, 你可以在你需要限流的服务里面配置一个 annotations ,让它在访问你的服务时候先去访问 B服务,通过B服务的结果来判断是否要访问你的服务。
并且它可以实时修改,实时生效,支持传参,可以实现不同的策略替换,上面的基于城市的限流,也可以放到这个里面了。
metadata:
annotations:
nginx.ingress.kubernetes.io/auth-url: >-
http://XXXXXXXX:8000/mirror/rate/limit?limitType=user
M、另外再说一下机器的配置
M-1、K8S
360核, 796G

M-2、MySQL
双节点 16核 128G

M-3、Redis
16G双节点

M-4、ADB

结果:
哎、本来今天晚上也就是17号,说是会有一波推广,刚好可以验证这次优化,但却只是小推广,太失望了…















 291
291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









