







ResNet的提出
随着网络的加深,出现了训练集准确率下降的现象,我们可以确定这不是由于Overfit过拟合造成的(因为过拟合的情况训练集应该准确率很高),对于这种深度网络的退化问题,限制了模型的深度。ResNet的出现解决了这一问题(对于是否解决了,也有人提出质疑),因此是继AlexNet之后的有一个里程碑。
作者针对这个问题提出了一种全新的网络,叫深度残差网络,它允许网络尽可能的加深,其中引入了全新的结构如图1;
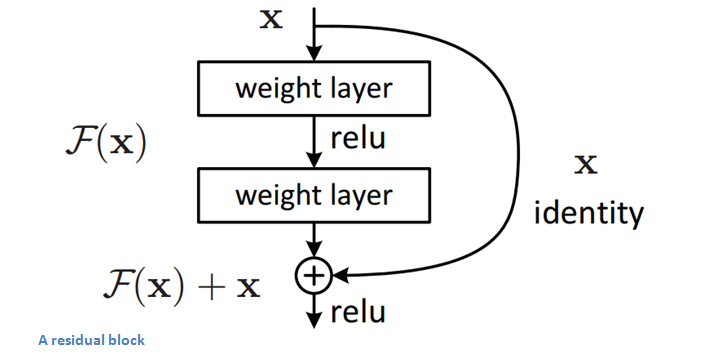
设想如果深层网络的后面那些层是恒等映射,那么模型就退化为一个浅层网络。那现在要解决的就是学习恒等映射函数了。但直接让一些层去拟合一个潜在的恒等映射函数H(x) = x,比较困难,这可能就是深层网络难以训练的原因。但是,如果把网络设计为H(x) = F(x) + x,如下图。我们可以转换为学习一个残差函数F(x) = H(x) - x. 只要F(x)=0,就构成了一个恒等映射H(x) = x. 而且,拟合残差肯定更加容易。
ResNet的核心思想是:计算层到层的残差,即F(x),以F(x)+x作为输出。
正是由于多了这条捷径,来自深层的梯度能直接畅通无阻地通过,去到上一层,使得浅层的网络层参数等到有效的训练!
之后开发了ResNet34,ResNet50,ResNet101,ResNet152等一系列网络结构。

数学角度分析
从数学的角度来分析这个问题,首先残差单元可以表示为:

其中  和
和  分别表示的是第
分别表示的是第  个残差单元的输入和输出,注意每个残差单元一般包含多层结构。
个残差单元的输入和输出,注意每个残差单元一般包含多层结构。  是残差函数,表示学习到的残差,而
是残差函数,表示学习到的残差,而  表示恒等映射,
表示恒等映射,  是ReLU激活函数。基于上式,我们求得从浅层 到深层
是ReLU激活函数。基于上式,我们求得从浅层 到深层  的学习特征为:
的学习特征为:

利用链式规则,可以求得反向过程的梯度:

式子的第一个因子  表示的损失函数到达 的梯度,小括号中的1表明短路机制可以将深处的梯度无损地传播到上一层,而另外一项残差梯度则需要经过带有weights的层。但是经过卷积层的梯度在往底层反向传递时,往往回发生梯度弥散,梯度会变的很小,导致底层的权重参数得不到很好地训练。有1的存在不会导致梯度消失。所以残差学习会更容易。
表示的损失函数到达 的梯度,小括号中的1表明短路机制可以将深处的梯度无损地传播到上一层,而另外一项残差梯度则需要经过带有weights的层。但是经过卷积层的梯度在往底层反向传递时,往往回发生梯度弥散,梯度会变的很小,导致底层的权重参数得不到很好地训练。有1的存在不会导致梯度消失。所以残差学习会更容易。
对ResNet的另类解读
基本的残差网络其实可以从另一个角度来理解,这是从另一篇论文里看到的,如下图所示: 
残差网络单元其中可以分解成右图的形式,从图中可以看出,残差网络其实是由多种路径组合的一个网络,直白了说,残差网络其实是很多并行子网络的组合,整个残差网络其实相当于一个多人投票系统(Ensembling)。
ResNet的真面目
ResNet的确可以做到很深,但是从上面的介绍可以看出,网络很深的路径其实很少,大部分的网络路径其实都集中在中间的路径长度上,如下图所示: 
从这可以看出其实ResNet是由大多数中度网络和一小部分浅度网络和深度网络组成的,说明虽然表面上ResNet网络很深,但是其实起实际作用的网络层数并没有很深
详情请看论文 Residual Networks Behave Like Ensembles ofRelatively Shallow Networks















 571
571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









