






 本文介绍逆向设计在模拟与数字电路中的应用,尤其适合于模拟芯片设计和10万门以下的数字电路。文章详细解释了逆向设计的过程,包括拆解、照相、提图、整理、分析和仿真等步骤。
本文介绍逆向设计在模拟与数字电路中的应用,尤其适合于模拟芯片设计和10万门以下的数字电路。文章详细解释了逆向设计的过程,包括拆解、照相、提图、整理、分析和仿真等步骤。
参考网址:http://www.ednchina.com/news/article/20170601IC?utm_source=EDNC%20Article%20Alert&utm_medium=Email&utm_campaign=2017-06-01
<--------------------------------------------------------------->
逆向设计非常适合模拟芯片设计,如ADC、DAC、锁相环等模拟电路,因为模拟电路的设计往往靠经验。此外,对于10万门以下的数字电路也适合,对于混合信号电路来讲,可以适合模拟部分的反向设计服务。在时间方面,普通的逆向设计往往需要3-5个月,而小于10万门的数字电路逆向设计一般需要2-3个月。
数字电路的反向是非常困难的,因为一般来说大规模的数字处理单元是通过程序综合成晶体管级电路,自动出layout,模拟电路部分相对容易,因为规模也很小,模拟电路的layout都是手工设计的,管子数量有限,电路层次化之后有经验的人很容易看出其功能,另外一点需要注意的是,反向别人的芯片,工艺的选择是一个重点,因为你选择的foundry可能和人家芯片的foundry不是一家,甚至工艺都不一样,你能学来的是别人的电路结构,完全照抄别人的电路(包括管子尺寸的大小,电容的大小,电阻的宽长等等)可能造成电路根本不能正常工作。
目前在国内,芯愿景公司、台湾宜硕也提供逆向设计服务;国际上著名的逆向设计企业主要有Chipworks和Semiconducto Insights(SI)公司。
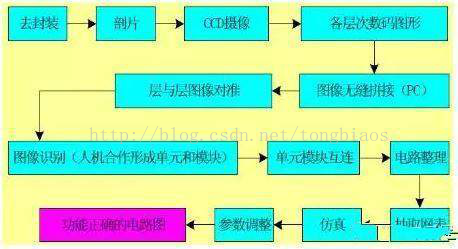
拆解:把要拆解的芯片放置在装了浓硫酸的容器里,容器需要盖住,但不能严实,这样里面的气体才能漫溢出来。把容器里的浓硫酸加热到沸腾(大约 300 摄氏度),在瓶底的周围铺上苏打粉——用来预防意外飞溅出来的硫酸液和冒出来的硫酸气体。
照相:在显微图像自动采集平台上逐层对芯片样品进行显微图像采集。与测量三维实体或曲面的逆向设计不同,测量集成电路芯片纯属表面文章:放好芯片位置、对对焦、选好放大倍数,使芯片表面在镜头中和显示器上清晰可见后,按下拍照按钮便可完成一幅显微图像的采集。取决于电路的规模和放大倍数,一层电路可能需要在拍摄多幅图像后进行拼凑,多层电路需要在拼凑后对准,有显微图像自动拼凑软件用于进行拼凑和对准操作。

该显微图像自动采集平台的放大倍数为1000倍,可将0.1um线条的放大至0.1mm的宽度。这意味着它已足以对付目前采用最先进工艺制作的0.09um集成电路芯片。
提图:集成电路由多层组成,每层用光刻工艺由光掩膜加以确定。制造集成电路时用的掩膜上的几何图形就是版图,版图是集成电路对应的物理层。
现在提图工作已经可以由电脑全部完成了。主流的电路原理图分析系统已经具有多层显微图像浏览、电路单元符号设计、电路原理图自动和交互式分析提取以及电路原理图编辑等强大功能,版图分析系统则可完成多层版图轮廓自动提取、全功能版图编辑、嵌入软件代码自动识别、提取、校验以及设计规则的统计和提取。
整理:数字电路需要归并同类图形,例如与非门、或非门、触发器等,同样的图形不要分析多次。提出的电路用电路绘制软件绘出(ViewWork、Laker、Cadence等),按照易于理解的电路布置,使其他人员也能看出你提取电路的功能,提取电路的速度完全由提图人员经验水平确定。注意,软件是按照版图的位置把各组件连接起来,如果不整理电路是看不出各模块的连接及功能的,所以完全靠软件是不能完成电路功能块划分和分析。
分析:提取出的电路整理成电路图,并输入几何参数(MOS为宽长比)。通过你的分析,电路功能明确,电路连接无误。
仿真:对电路进行功能仿真验证。模拟电路一般采用Hspice、Cadence等工具,小规模数字电路采用Cadence,Hsim等工具。根据新的工艺调整电路,调整后进行验证。
验证:对输入的电路原理图进行浏览、查询、编辑、调试与仿真。分析电路原理,调节电路参数,并在一定的激励输入下观测输出波形,以验证设计的逻辑正确性。要对提取的网表作仿真验证,并与前仿结果对比,版图导出GDS文件,Tape out(将设计数据转交给制造方)。
<--------------------------------------------------------------->
收集一下别人写的芯片制造相关的资料!

















 1723
1723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









