






申明:本代码为chatgpt生成,作者乃菜鸟一枚。
大致算法流程:
- 随机选取k个质心
- 根据设定的batch_size大小随机选取batch_size个样本作为代表样本集
- 计算代表样本集中每个样本到每个质心的距离,分别归到最近的质心所在簇
- 计算当前聚类簇的平均值,作为新的质心(原质心也参与平均值的计算)
- 判断是否已经收敛:如果聚类标签不再改变,则结束迭代
- 重复执行2-5步,直到算法收敛
参数:参照sklean.Minibatchkmeans,此处参数为:
- X:数据集
- y_pred_init:标签
- n_cluster:簇数
- batch_size:代表样本集大小
- n_init:随机选取初始质心次数
- max_iter:最大迭代次数
# 运行 mini-batch kmeans 算法
minibatch_kmeans(X, y, n_clusters=2, batch_size=5, n_init=1, max_iter=15)样本集:生成了一个只有30个样本,二维的,分为两类的样本集
# 生成 30 个样本,每个样本有 2个特征,分为 2 类
X = np.concatenate([
np.random.normal(loc=[0, 0], scale=[0.3, 0.3], size=(10, 2)), # 类别 0
np.random.normal(loc=[2, 2], scale=[0.3, 0.3], size=(10, 2)), # 类别 1
])
运行效果展示:
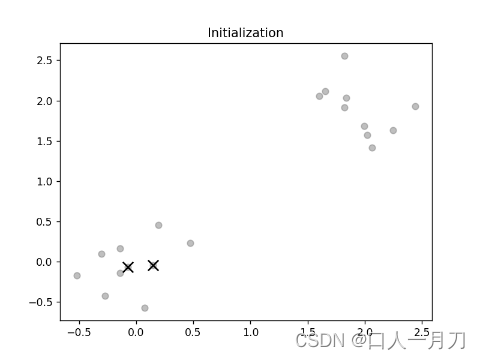
1.初始质心,将所有样本标签初始化为-1,表示未分类

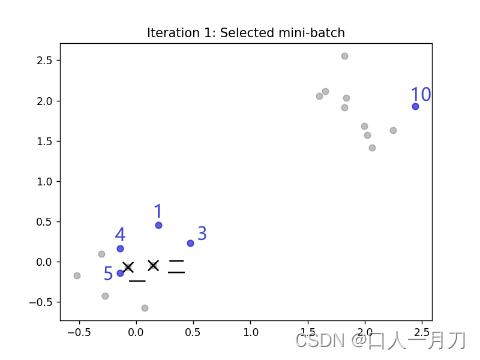
2.随机选取batch(batch_size=5)

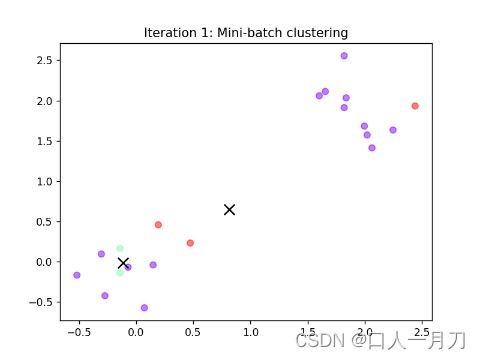
3. 计算距离、更新标签

显然样本4距离质心一更近,故被赋予标签‘0’
![]()
4.更新质心
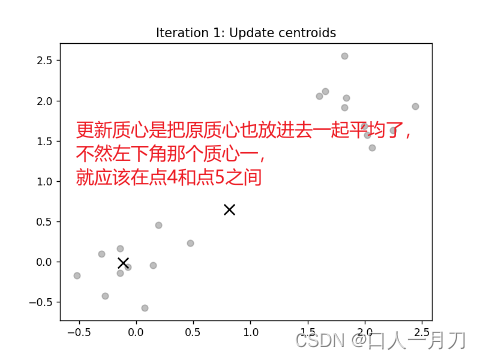
下面这张更加明显

5.把batch中的聚类结果合并到整个数据集中

6.判断收敛
n_iter_tol = 2 # 连续多少轮聚类结果相同认为已经收敛
# 判断聚类是否已经收敛
if np.array_equal(y_pred, y):
n_iter_same += 1
if n_iter_same >= n_iter_tol:
break
else:
n_iter_same = 0
每轮聚类结果:
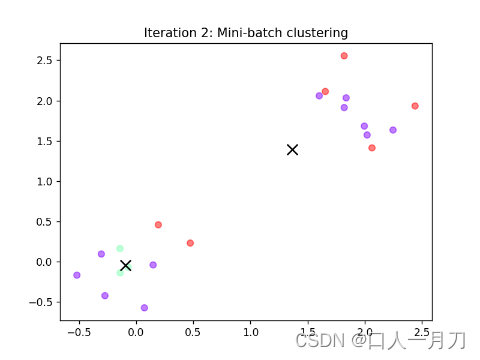

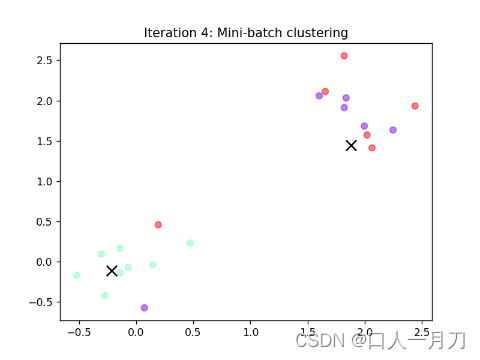
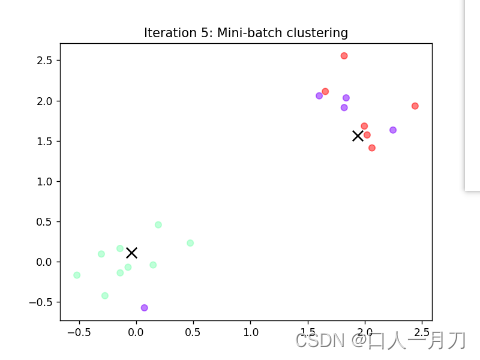
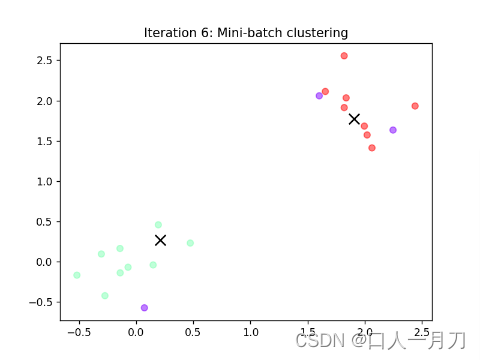

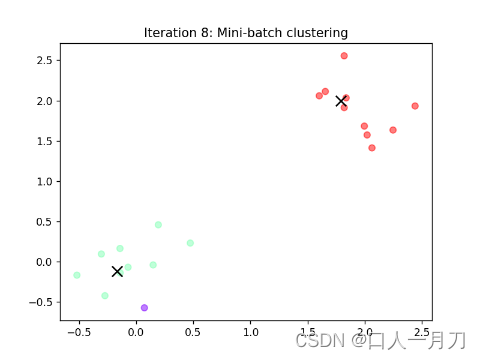

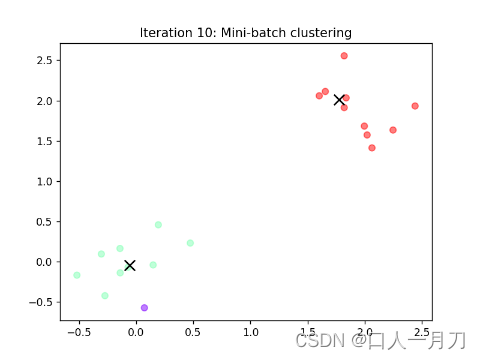
 第九轮和第十轮两轮没变化,结束迭代。
第九轮和第十轮两轮没变化,结束迭代。
完整代码:
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)#删掉该值,每次随机生成样本集
n_iter_tol = 2 # 连续多少轮聚类结果相同认为已经收敛
def minibatch_kmeans(X, y, n_clusters, batch_size, n_init, max_iter):
for i in range(n_init):
# 初始化聚类标签:将所有样本的标签初始化为 -1(表示未知)
y = np.zeros(X.shape[0], dtype=int) - 1
# 初始化聚类质心和上一轮迭代的聚类结果
centroids = X[np.random.choice(X.shape[0], n_clusters, replace=False)]
y_pred = np.zeros(X.shape[0], dtype=np.int32) - 1
# 绘制初始化的聚类质心和所有样本点
plt.scatter(X[:, 0], X[:, 1], c='gray', alpha=0.5)
plt.scatter(centroids[:, 0], centroids[:, 1], marker='x', color='black', s=100)
plt.title("Initialization")
plt.show()
for j in range(max_iter):
print('第', j+ 1, '轮:y_pred=', y_pred)
print('质心:', centroids)
# 随机选择一个 mini-batch
batch_indices = np.random.choice(X.shape[0], batch_size, replace=False)
X_batch = X[batch_indices]
y_pred_batch = y[batch_indices]
print('batch_indices:', batch_indices)
print('选的小样本集', X_batch)
print('小样本集的标签', y_pred_batch)
# 绘制 mini-batch 中的样本点和聚类质心
plt.scatter(X[:, 0], X[:, 1], c='gray', alpha=0.5)
plt.scatter(centroids[:, 0], centroids[:, 1], marker='x', color='black', s=100)
plt.scatter(X_batch[:, 0], X_batch[:, 1], c='blue', alpha=0.5)
plt.title("Iteration %d: Selected mini-batch" % (j+1))
plt.show()
# 计算每个样本到每个质心的距离
distances = np.sqrt(((X_batch - centroids[:, np.newaxis])**2).sum(axis=2))
print('每个质心到每个样本的距离:', distances)
# 将每个样本分配到距离最近的质心所在的聚类
y_pred_batch = np.argmin(distances, axis=0)
print('新y_pred_batch:', y_pred_batch)
for k in range(n_clusters):
# 选出当前聚类簇所属的样本点(包括原来的质心)
cluster_points = np.vstack((X_batch[y_pred_batch == k], centroids[k]))
# 计算当前聚类簇的平均值,作为新的质心
if len(cluster_points) > 0:
centroids[k] = np.mean(cluster_points, axis=0)
# 绘制更新后的聚类质心和未知样本点
plt.scatter(X[:, 0], X[:, 1], c='gray', alpha=0.5)
plt.scatter(centroids[:, 0], centroids[:, 1], marker='x', color='black', s=100)
plt.title("Iteration %d: Update centroids" % (j+1))
plt.show()
# 将 mini-batch 中的聚类结果合并到整个数据集中
y[batch_indices] = y_pred_batch
print('y:',y)
# 绘制 mini-batch 中的聚类结果和未知样本点
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='rainbow', alpha=0.5)
plt.scatter(centroids[:, 0], centroids[:, 1], marker='x', color='black', s=100)
plt.title("Iteration %d: Mini-batch clustering" % (j+1))
plt.show()
print('y_pred:',y_pred)
# 判断聚类是否已经收敛
if np.array_equal(y_pred, y):
n_iter_same += 1
if n_iter_same >= n_iter_tol:
break
else:
n_iter_same = 0
y_pred = y.copy()
# 绘制每个样本归为最近质心所在簇后的聚类结果和未知样本点
distances = np.sqrt(((X - centroids[:, np.newaxis])**2).sum(axis=2))
y_pred_final = np.argmin(distances, axis=0)
plt.scatter(X[:, 0], X[:, 1], c=y_pred_final, cmap='rainbow', alpha=0.5)
plt.scatter(centroids[:, 0], centroids[:, 1], marker='x', color='black', s=100)
plt.title("Final clustering")
plt.show()
# 生成 30 个样本,每个样本有 2个特征,分为 2 类
X = np.concatenate([
np.random.normal(loc=[0, 0], scale=[0.3, 0.3], size=(10, 2)), # 类别 0
np.random.normal(loc=[2, 2], scale=[0.3, 0.3], size=(10, 2)), # 类别 1
])
# 初始化聚类标签:将所有样本的标签初始化为 -1(表示未知)
y = np.zeros(X.shape[0], dtype=int) - 1
# 运行 mini-batch kmeans 算法
minibatch_kmeans(X, y, n_clusters=2, batch_size=5, n_init=1, max_iter=15)














 1020
1020











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









