






在当前大数据的背景下,工程师们往往为了追求更短的计算时间,不得不在一定程度上减少算法本身的计算精度,我说的是在一定程度上,所以肯定不能只追求速度而不顾其它。在KMeans聚类中,为了降低计算时间,KMeans算法的变种Mini Batch KMeans算法应运而生。
Mini Batch KMeans算法是一种能尽量保持聚类准确性下但能大幅度降低计算时间的聚类模型,采用小批量的数据子集减少计算时间,同时仍试图优化目标函数,这里所谓的Mini Batch是指每次训练算法时随机抽取的数据子集,采用这些随机选取的数据进行训练,大大的减少了计算的时间,减少的KMeans算法的收敛时间,但要比标准算法略差一点,建议当样本量大于一万做聚类时,就需要考虑选用Mini Batch KMeans算法。
这种对时间优化的思路不仅应用在KMeans聚类,还广泛应用于梯度下降、深度网络等机器学习和深度学习算法。
在sklearn.cluster 中MiniBatchKMeans与KMeans方法的使用基本是一样的,为了便于比较,继续使用与我上一篇博客同样的数据集。
在MiniBatchKMeans中可配置的参数如下:
class sklearn.cluster.MiniBatchKMeans(n_clusters=8, init='kmeans++',
max_iter=100, batch_size=100, verbose=0, compute_labels=True,
random_state=None, tol=0.0, max_no_improvement=10, init_size=None,
n_init=3, reassignment_ratio=0.01)通过参数batch_size可以设置Mini Batch的大小,这里默认值为100.
导入包
from sklearn.cluster import MiniBatchKMeans
import demo1
import numpy as np
import matplotlib.pyplot as plt画出数据的散点图和聚类中心的位置
def draw_pic(data_list):
# 画出散点图
for x in range(len(data_list)):
plt.scatter(data_list[x][0], data_list[x][1], s=30, c='b', marker='.')
def draw_cluster_centers(centers_mat):
# 画出聚类中心
for k in range(len(centers_mat)):
plt.scatter(centers_mat[k][0], centers_mat[k][1], s=60, c='r', marker='D')执行程序,进行Mini Batch KMeans聚类,为了方便,对数据集的处理我调用了我上一篇博客中的数据矩阵处理函数。
if __name__ == '__main__':
data_Set = demo1.file2matrix('testSet.txt', '\t')
draw_pic(data_Set)
k = 4 # 确定聚类中心的数目
# 执行KMeans算法
minibatchkmeans = MiniBatchKMeans(n_clusters=k, batch_size=50)
minibatchkmeans.fit(np.mat(data_Set))
draw_cluster_centers(minibatchkmeans.cluster_centers_)
plt.show()最终得出结果:
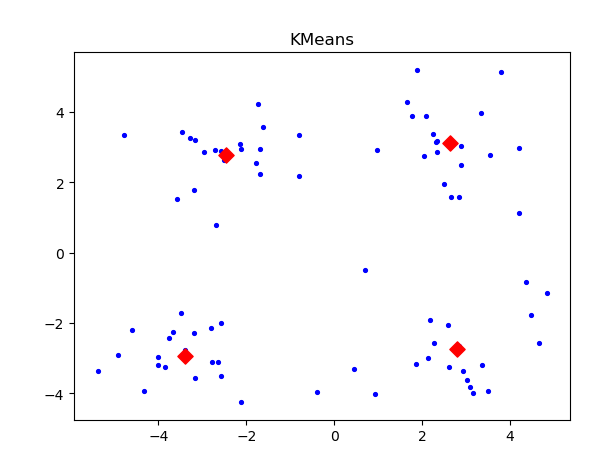
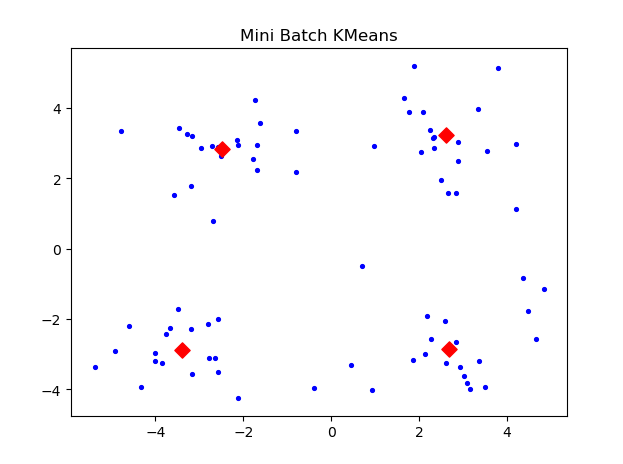
从结果来看,Mini Batch KMeans算法的聚类效果还是不错的,但我觉得这并不能说明什么问题,因为我的数据量太少了,以后有时间把爬虫技术弄熟练,再做一个数据量大的吧。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









