






注意力机制是一种非常流行的算法,看上去很简单,但是它的变体非常多,想要完全领悟也是有一定难度的,下面笔者就结合自己的学习经历,说一下在论文中看到的注意力机制。
一、最简单的注意力机制
1.1 计算过程详解
这种注意力机制虽然很简单,但是被广泛的采用。
假设输入向量的维度是(bs, T, d),现在考虑的问题是,如何从这个输入序列中有效地提取特征。
我们首先用数学语言把公式写出来,假设输入向量可以表示为:
,
n代表时间步的长度
那么假设我们要在时间步的维度上提取特征:
意思就是,在时间步的维度上乘一个全连接矩阵。给每个时间步分配一个权重。
第一步的作用是把传感器的数值转化为权重。说白了,全连接神经网络其实就是一种高维度的线性回归。如果想要在第二个维度上分配注意力,那么就要在第二个维度上乘一个全连接矩阵,这个矩阵学习到的参数是在第二个维度上,各个特征之间的关系。

如果想要在特征维度(d)上分配注意力,那么就要在特征维度上乘一个矩阵。圆圈中加一个点表现将矩阵的对应元素相乘。
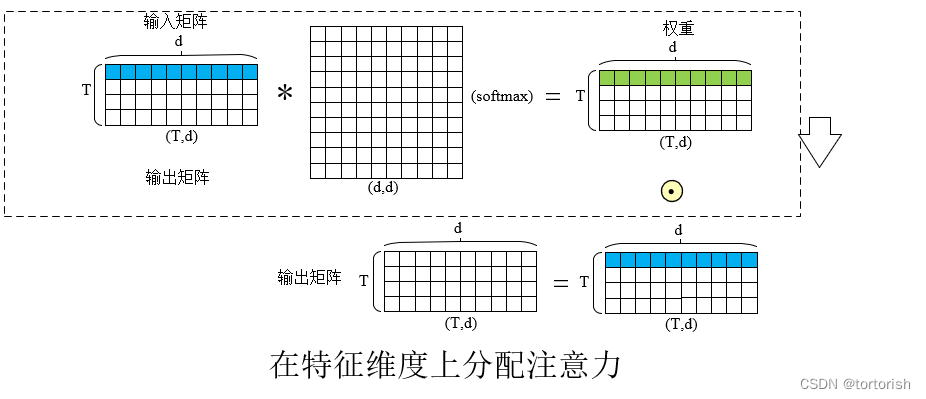
再提一句,这里之所以要在所需要的维度上乘一个全连接矩阵,是为了将原有的数值转化为各传感器间的权重关系。
1.2 注意力可视化分析
这种注意力机制特别容易理解,因为权重矩阵的维度和输入向量的大小是相等的,并且也特别容易去解释,并实现可视化。
把注意力矩阵(shape:(bs,T,d))进行可视化后的结果如下图所示,可以很清楚的看到注意力在哪个维度上分配的权重最大。

1.3 计算复杂度分析
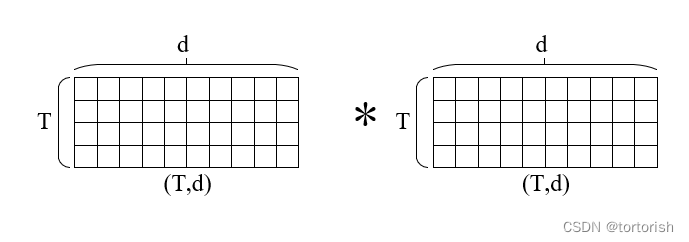
另外,这种注意力的计算复杂度也是最低的。计算复杂度可以理解为要进行多少次乘法。很明显,这种算法的计算复杂度是O(T*d)。
1.4 注意力评分函数分析
我们知道,在注意力机制中要用到评分函数,那在这边的评分函数是什么呢?
其实就是全连接的神经网络。如果在时间步上进行注意力分配,
那么相当于是矩阵(d*n)*(n*n)相乘,计算复杂度是O(n^2*d),和序列二次方的长度成正比。
如果在特征维度上进行注意力分配,相当于是(n*d)*(d*d)的矩阵做乘法,计算复杂度是O(n*d^2)。和隐藏单元的个数成正比。
我们再延伸一步,这是后面第二节中的内容,如果使用最常用的点积注意力,那么注意力的计算复杂度是多少呢?
我们知道,点积注意力的评分函数是
相当于是形状为(n*d)*(d*n)的矩阵相乘,结果为一个(n*n)的矩阵,计算复杂度也为(n^2*d)。

由于是和序列的二次方成正比,所以每一个输入的单元都要和其它所有的单元相连接。每一个圆圈代表一个向量,其维度为d,圆圈的个数代表着输入序列的长度。
计算加权和最简单有效的方法是使用矩阵乘积,我们还可以使用矩阵相乘的方法来计算注意力。
二、软性注意力机制
这种注意力机制比较难懂,但是普适性很强,基本讲深度学习注意力机制的书上都会提到这种算法,在自然语言处理里面用的基本都是这种注意力机制。
在读了基本有关深度学习的书以后,笔者认为,注意力机制被广泛采用,起源于自然语言处理领域。后面阐述的理论需要读者对NLP中的编解码器结构有一定的认识。这边阅读的时候如果不熟悉可以跳过,只是做一个简单的回顾。
2.1 软性注意力机制要解决的问题
在之前处理机器翻译任务的时候,编码器会把最后一个时间步上的信息传递给解码器,却忽略了编码器向量其它时间步上的信息。为了解决这个问题,引入了注意力机制。
这种注意力机制已经被广泛的采用,包括现在大火的transformer结构。如图所示,编码向量和解码器每个时间步上的向量做相似度计算。前者充当注意力机制中的键值对,后者充当查询!
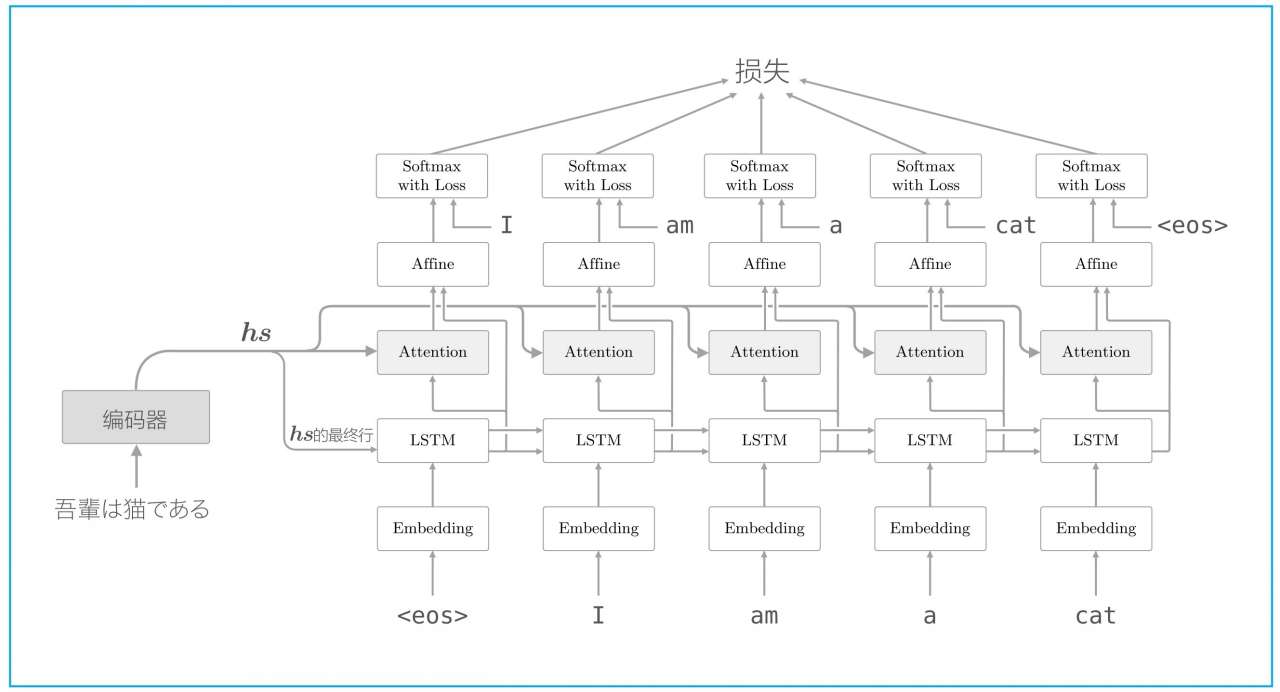
2.2 注意力计算
可以看到,和第一节中不同的是,这边多了一个叫做查询的向量。
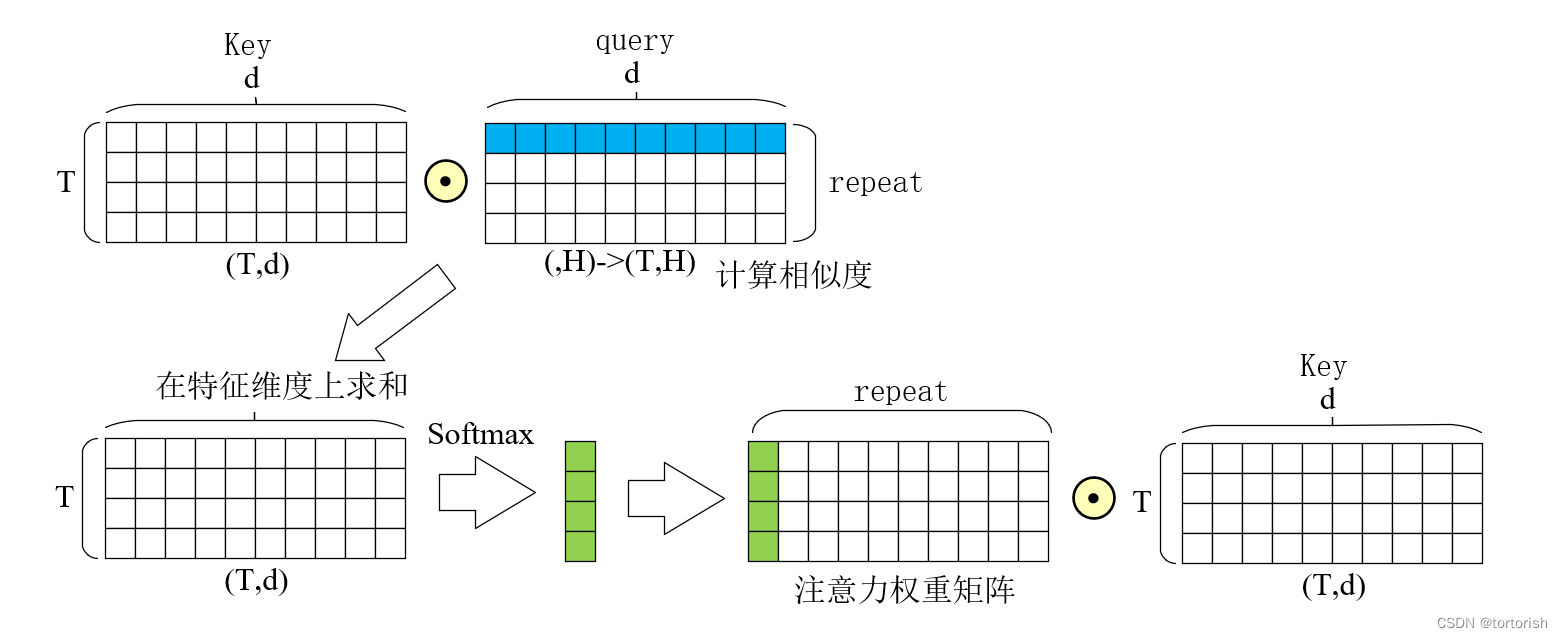
如图所示,先讲key和query的向量对应元素相乘,然后再求和,汇聚成一个向量,其实这就是点积注意力机制,然后将该注意力矩阵在特征维度上进行复制,最后乘以key向量,便得到了最终加权后的输出。
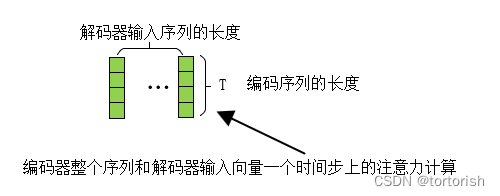
但是,这种注意力每次只能比较一个时间步上的query,那有没有什么办法可以一次性将整个query和整个key比较呢?
当然可以了,这种时候就需要借助矩阵的乘法。
这种注意力机制是为了衡量各个特征间的相似度!















 5684
5684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









