







时间序列中的自注意力机制 (Self-Attention Mechanism) 详细解释及举例
自注意力机制在时间序列处理中非常有用,因为它能够捕捉序列中各时间步之间的相关性,从而有效地处理长程依赖关系。下面是自注意力机制的详细工作原理以及在时间序列中的应用举例。
工作原理
1. 输入向量变换为查询、键和值矩阵

2. 计算注意力得分

3. 计算加权值

举例说明
假设我们有一个简单的时间序列数据,表示某个传感器在不同时间步的测量值。我们要通过自注意力机制捕捉各时间步之间的相关性。
输入数据

1. 生成查询、键和值矩阵
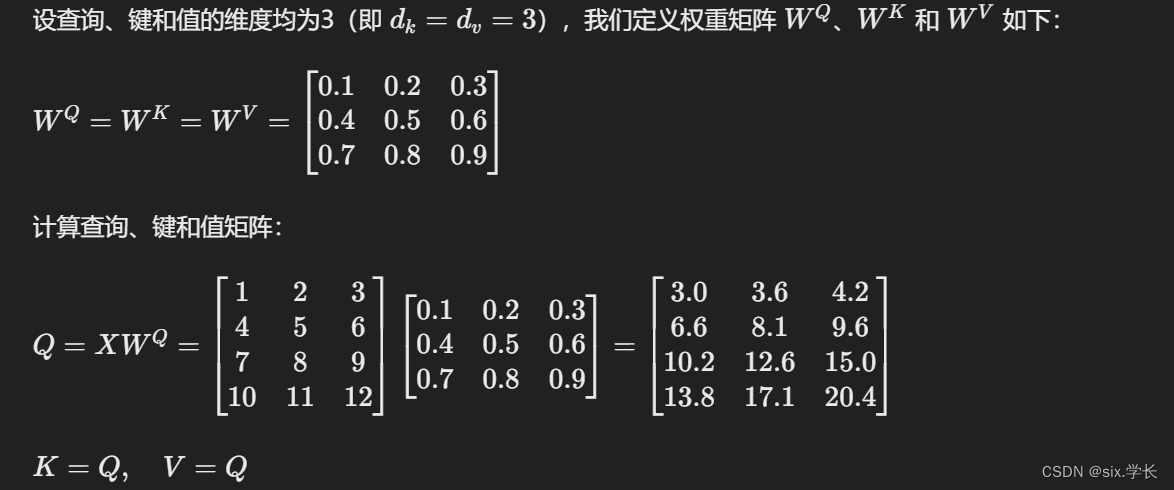
2. 计算注意力得分

3. 计算加权值

具体代码实现
下面是一个具体的Python代码示例,展示如何在时间序列中实现自注意力机制:
import numpy as np
def softmax(x 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 455
455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









