







1、编写Spark SQL查询语句
在这之前创建Maven项目。创建的过程如:http://blog.csdn.net/tototuzuoquan/article/details/74571374
在这里:http://blog.csdn.net/tototuzuoquan/article/details/74907124,可以知道Spark Shell中使用SQL完成查询,下面通过在自定义程序中编写Spark SQL查询程序。首先在maven项目的pom.xml中添加Spark SQL的依赖。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.5.2</version>
</dependency>最终的Pom文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.toto.spark</groupId>
<artifactId>bigdata</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.10.6</scala.version>
<spark.version>1.6.2</spark.version>
<hadoop.version>2.6.4</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.5.2</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-make:transitive</arg>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>2、运行参数准备
person.txt的内容如下:
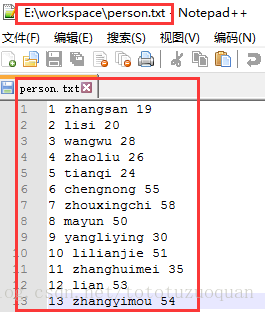
1 zhangsan 19
2 lisi 20
3 wangwu 28
4 zhaoliu 26
5 tianqi 24
6 chengnong 55
7 zhouxingchi 58
8 mayun 50
9 yangliying 30
10 lilianjie 51
11 zhanghuimei 35
12 lian 53
13 zhangyimou 543、通过反射推断出Schema
package cn.toto.spark
import org.apache.spark.sql.SQLContext
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by toto on 2017/7/10.
*/
object InferringSchema {
def main(args: Array[String]): Unit = {
//创建SparkConf()并设置App名称(本地运行的时候加上:setMaster("local"),如果不是本地就不加这句)
val conf = new SparkConf().setAppName("SQL-1").setMaster("local")
//SQLContext要依赖SparkContext
val sc = new SparkContext(conf)
//创建SQLContext
val sqlContext = new SQLContext(sc)
//从指定的地址创建RDD
val lineRDD = sc.textFile(args(0)).map(_.split(" "))
//创建case class
//将RDD和case class关联
val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt))
//引入隐式转换,如果不到人无法将RDD转换成DataFrame
//将RDD转换成DataFrame
import sqlContext.implicits._
val personDF = personRDD.toDF
//注册表
personDF.registerTempTable("t_person")
//传入SQL
val df = sqlContext.sql("select * from t_person order by age desc limit 2")
//将结果以JSON的方式存储到指定位置
df.write.json(args(1))
//停止Spark Context
sc.stop()
}
}
//case class一定要放在外面
case class Person(id:Int, name:String, age : Int)参数配置:
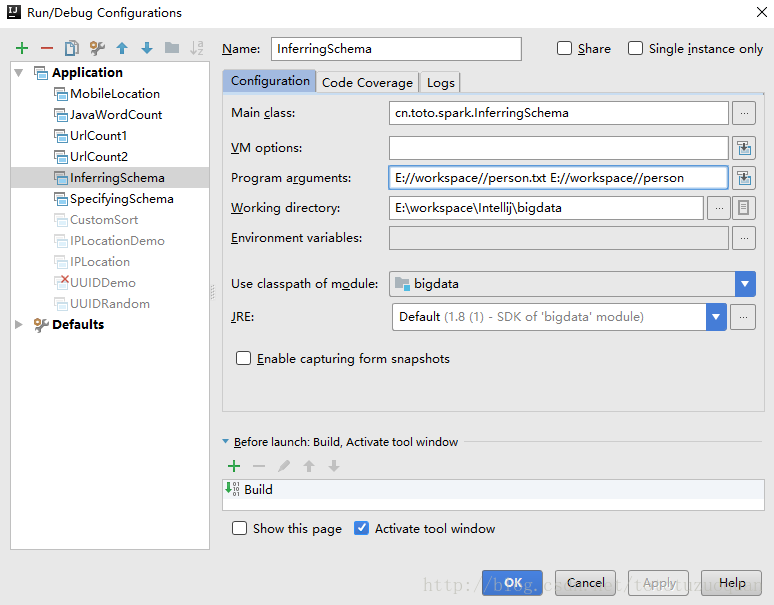
运行程序,结果如下:
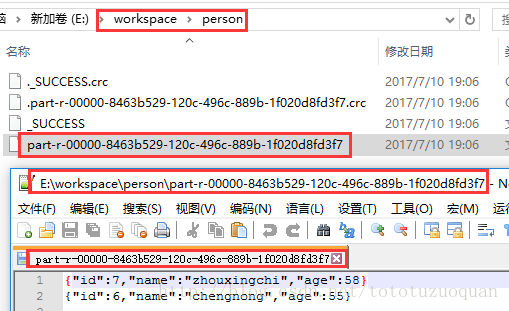
将程序打包成jar,上传到Spark集群,提交Spark任务(要以代码中要去掉setMaster(“local”))
[root@hadoop1 spark-2.1.1-bin-hadoop2.7]# cd $SPARK_HOME
[root@hadoop1 spark-2.1.1-bin-hadoop2.7]# bin/spark-submit --class cn.toto.spark.InferringSchema --master spark://hadoop1:7077,hadoop2:7077 /home/tuzq/software/sparkdata/bigdata-1.0-SNAPSHOT.jar hdfs://mycluster/person.txt hdfs://mycluster/out4.通过StructType直接指定Schema
代码如下:
package cn.toto.spark
import org.apache.spark.sql.{Row, SQLContext}
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by toto on 2017/7/10.
*/
object SpecifyingSchema {
def main(args: Array[String]): Unit = {
//创建SparkConf()并设置App名称
val conf = new SparkConf().setAppName("SQL-2").setMaster("local")
//SQLContext要依赖SparkContext
val sc = new SparkContext(conf)
//创建SQLContext
val sqlContext = new SQLContext(sc)
//从指定的地址创建RDD
val personRDD = sc.textFile(args(0)).map(_.split(" "))
//通过StructType直接指定每个字段的Schema,相当于是表的描述信息
val schema = StructType(
List(
StructField("id",IntegerType,true),
StructField("name",StringType,true),
StructField("age",IntegerType,true)
)
)
//将RDD映射到rowRDD
val rowRDD = personRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).toInt))
//将schema信息应用到rowRDD上
val personDataFrame = sqlContext.createDataFrame(rowRDD,schema)
//注册表
personDataFrame.registerTempTable("t_person")
//执行SQL
val df = sqlContext.sql("select * from t_person order by age desc limit 4")
//将结果以JSON的方式存储到指定位置
df.write.json(args(1))
//停止Spark Context
sc.stop()
}
}运行参数配置:
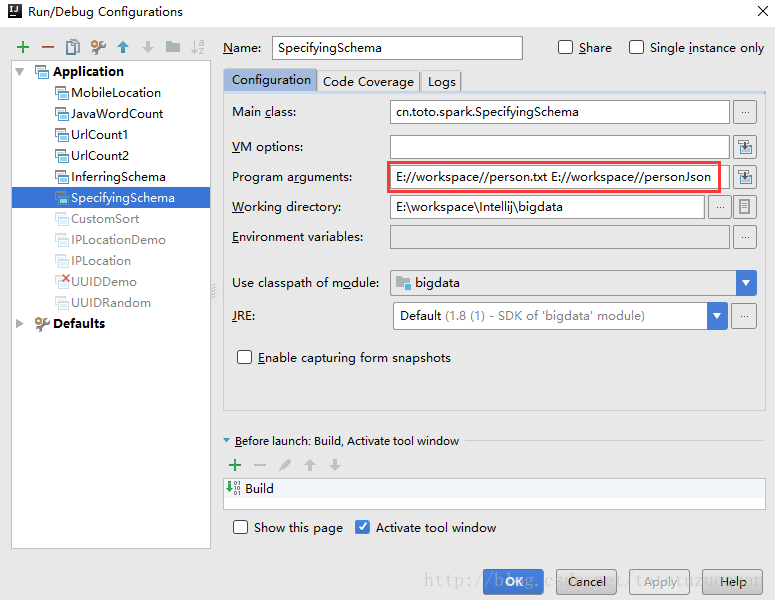
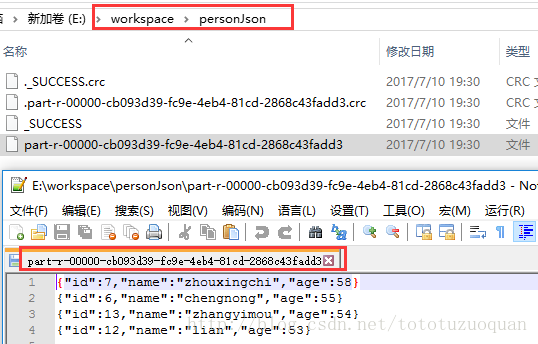
运行后的结果:
















 705
705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











