






目录
一、认识DataFrame
1.1 简介
DataFrame 是 Pandas 中的另一个核心数据结构,用于表示二维表格型数据。
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。
DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
DataFrame 提供了各种功能来进行数据访问、筛选、分割、合并、重塑、聚合以及转换等操作。
1.2 DataFrame特点
- 二维结构:
- DataFrame是一个二维表格,类似于Excel电子表格或SQL表,具有行和列。
- 可以被看作由多个Series(一维数组)组成的字典,其中每个Series代表一列数据。
- 数据类型多样性:
- 不同的列可以包含不同的数据类型,如整数、浮点数、字符串或Python对象等。
- 索引:
- DataFrame拥有行索引(通常是整数或日期)和列索引(可以是任意字符串)。
- 通过行和列的标签,可以进行灵活的索引和切片操作。
- 大小可变:
- 可以添加和删除列,类似于Python中的字典。
- 自动对齐:
- 在进行算术运算或数据对齐操作时,DataFrame会自动对齐索引。
- 处理缺失数据:
- DataFrame可以包含缺失数据,Pandas使用NaN(Not a Number)来表示。
- 提供了方便的方法来处理缺失值,如dropna()删除包含缺失值的行或列,fillna()填充缺失值。
- 数据操作:
- 支持丰富的数据操作方法,如数据切片、索引、子集分割、合并、重塑、聚合以及转换等。
- 提供了.loc、.iloc和.query()等方法来灵活地访问和筛选数据。
- 时间序列支持:
- 对时间序列数据有特别的支持,可以轻松地进行时间数据的切片、索引和操作。
- 数据可视化:
- 虽然DataFrame本身不是可视化工具,但它可以与Matplotlib或Seaborn等可视化库结合使用,进行数据可视化。
- 高效的数据输入输出:
- 可以方便地读取和写入数据,支持多种格式,如CSV、Excel、SQL数据库和HDF5格式。
- 描述性统计:
- 提供了一系列方法来计算描述性统计数据,如.describe()、.mean()、.sum()等。
- 支持多级索引:
- 可以在行和列上使用多个标签进行索引,以更复杂的方式组织和访问数据。
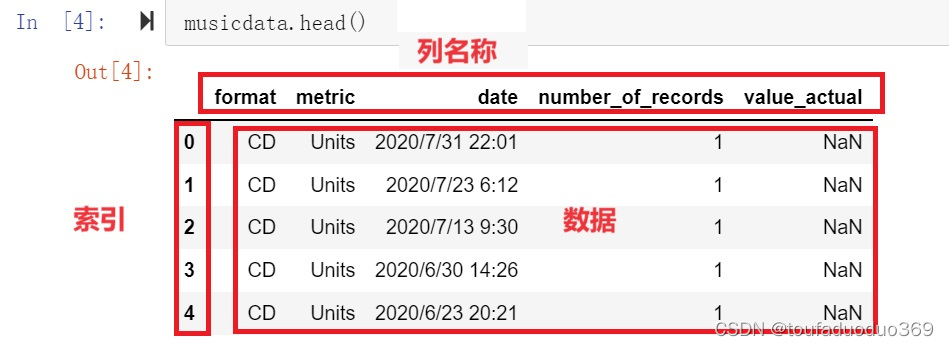
1.3 表格对象组成部分
表格对象的主要组成部分有三个:
- 数据(values)
- 索引(index)
- 列名称(columns)
二、创建DataFrame
2.1 DataFrame构造方法
DataFrame构造方法如下:
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)参数说明:
- data:DataFrame 的数据部分,可以是字典、二维数组、Series、DataFrame 或其他可转换为 DataFrame 的对象。如果不提供此参数,则创建一个空的 DataFrame。
- index:DataFrame 的行索引,用于标识每行数据。可以是列表、数组、索引对象等。如果不提供此参数,则创建一个默认的整数索引。
- columns:DataFrame 的列索引,用于标识每列数据。可以是列表、数组、索引对象等。如果不提供此参数,则创建一个默认的整数索引。
- dtype:指定 DataFrame 的数据类型。可以是 NumPy 的数据类型,例如 np.int64、np.float64 等。如果不提供此参数,则根据数据自动推断数据类型。
- copy:是否复制数据。默认为 False,表示不复制数据。如果设置为 True,则复制输入的数据。
2.2 创建DataFrame对象
2.2.1 通过Series对象创建
#1、通过单个Series对象创建。DataFrame是一组Series对象的集合,可以用单个Series创建一个单列的DataFrame
import pandas as pd
import numpy as np
#先创建一个Series对象
df1 = pd.Series({'California': 423967, 'Texas': 695662,
'New York': 141297, 'Florida': 170312,
'Illinois': 149995})
#创建单列的DataFrame对象
pd.DataFrame(df1,columns=['area'])运行效果如下:

#2、通过多个Series对象的字典创建DataFrame对象
#另外创建一个Series对象
df2 = pd.Series({'California': 38332521, 'Texas': 26448193,
'New York': 19651127, 'Florida': 19552860,
'Illinois': 12882135})
#使用字Series对象字典方式创建DataFrame对象
pd.DataFrame({'area':df1, 'population':df2})运行效果如下:

2.2.2 使用字典列表创建
#所有元素都是字典的列表可以变成DataFrame
#创建一个元素为字典的列表
df3 = [{'a':i, 'b': 2*i} for i in range(10)]
#通过字典列表创建DataFrame
pd.DataFrame(df3)
运行效果如下:

2.2.3 通过Numpy创建
#假入有一个二维数组,就可以创建一个可以指定行列索引值的DataFrame
#创建一个numpy二维数组
np.random.seed(0)
a =np.random.randint(1,10,(3,2))
#基于a数组建立DataFrame
pd.DataFrame(a,columns=['foo', 'bar'],index=['a','b', 'c'])
#输出如下:
foo bar
a 6 1
b 4 4
c 8 4
#假如不指定行列索引,那么行列默认都是整数索引值
pd.DataFrame(a)
#输出如下:
0 1
0 6 1
1 4 4
2 8 4三、DataFrame 的属性和方法
DataFrame 对象有许多属性和方法,用于数据操作、索引和处理,例如:shape、columns、index、head()、tail()、info()、describe()、mean()、sum() 等。
# DataFrame 的属性和方法
print(df.shape) # 形状
print(df.columns) # 列名
print(df.index) # 索引
print(df.head()) # 前几行数据,默认是前 5 行
print(df.tail()) # 后几行数据,默认是后 5 行
print(df.info()) # 数据信息
print(df.describe())# 描述统计信息
print(df.mean()) # 求平均值
print(df.sum()) # 求和3.1访问 DataFrame 元素
访问列:使用列名作为属性或通过 .loc[]、.iloc[] 访问,也可以使用标签或位置索引。
# 通过列名访问
print(df['Column1'])
# 通过属性访问
print(df.Name)
# 通过 .loc[] 访问
print(df.loc[:, 'Column1'])
# 通过 .iloc[] 访问
print(df.iloc[:, 0]) # 假设 'Column1' 是第一列
# 访问单个元素
print(df['Name'][0])访问行:使用行的标签和 .loc[] 访问。
# 通过行标签访问
print(df.loc[0, 'Column1'])3.2 修改DataFrame
修改列数据:直接对列进行赋值。
df['Column1'] = [10, 11, 12]添加新列:给新列赋值。
df['NewColumn'] = [100, 200, 300]添加新行:使用 loc、append 或 concat 方法
# 使用 loc 为特定索引添加新行
df.loc[3] = [13, 14, 15, 16]
# 使用 append 添加新行到末尾
new_row = {'Column1': 13, 'Column2': 14, 'NewColumn': 16}
df = df.append(new_row, ignore_index=True)concat() 方法用于合并两个或多个 DataFrame,当你想要添加一行到另一个 DataFrame 时,可以将新行作为一个新的 DataFrame,然后使用 concat()
# 使用concat添加新行
new_row = pd.DataFrame([[4, 7]], columns=['A', 'B']) # 创建一个只包含新行的DataFrame
df = pd.concat([df, new_row], ignore_index=True) # 将新行添加到原始DataFrame
print(df)3.3 删除DataFrame元素
df_dropped = df.drop('Column1', axis=1)
df_dropped = df.drop(0) # 删除索引为 0 的行3.4 DataFrame 的统计分析
描述性统计:使用 .describe() 查看数值列的统计摘要。
df.describe()计算统计数据:使用聚合函数如 .sum()、.mean()、.max() 等。
df['Column1'].sum()
df.mean()3.5 DataFrame 的索引操作
重置索引:使用 .reset_index()。
df_reset = df.reset_index(drop=True)设置索引:使用 .set_index()。
df_set = df.set_index('Column1')3.6 DataFrame 的布尔索引
使用布尔表达式:根据条件过滤 DataFrame。
df[df['Column1'] > 2]3.7 DataFrame 的数据类型
查看数据类型:使用 dtypes 属性。
df.dtypes转换数据类型:使用 astype 方法。
df['Column1'] = df['Column1'].astype('float64')3.8 DataFrame 的合并与分割
合并:使用 concat 或 merge 方法。
# 纵向合并
pd.concat([df1, df2], ignore_index=True)
# 横向合并
pd.merge(df1, df2, on='Column1')分割:使用 pivot、melt 或自定义函数。
# 长格式转宽格式
df_pivot = df.pivot(index='Column1', columns='Column2', values='Column3')
# 宽格式转长格式
df_melt = df.melt(id_vars='Column1', value_vars=['Column2', 'Column3'])3.9 索引和切片
DataFrame 支持对行和列进行索引和切片操作。
# 索引和切片
print(df[['Name', 'Age']]) # 提取多列
print(df[1:3]) # 切片行
print(df.loc[:, 'Name']) # 提取单列
print(df.loc[1:2, ['Name', 'Age']]) # 标签索引提取指定行列
print(df.iloc[:, 1:]) # 位置索引提取指定列四、注意事项
DataFrame是一种灵活的数据结构,可以容纳不同数据类型的列。- 列名和行索引可以是字符串、整数等。
DataFrame可以通过多种方式进行数据选择、过滤、修改和分析。- 通过对
DataFrame的操作,可以进行数据清洗、转换、分析和可视化等工作。
















 1424
1424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









