






本文是https://en.algorithmica.org/hpc/和MIT 6.172的课后题解析
课程地址:
文章目录
HW2 Profiling Serial Merge Sort
HW2的课程对应的是L2: Bentley’s Rules和L3:Bit Hacks
关于Bit Hacks可以看https://zhuanlan.zhihu.com/p/37014715
测试DEBUG和非DEBUG区别
HW2介绍了下perf和valgrind,不多展开。
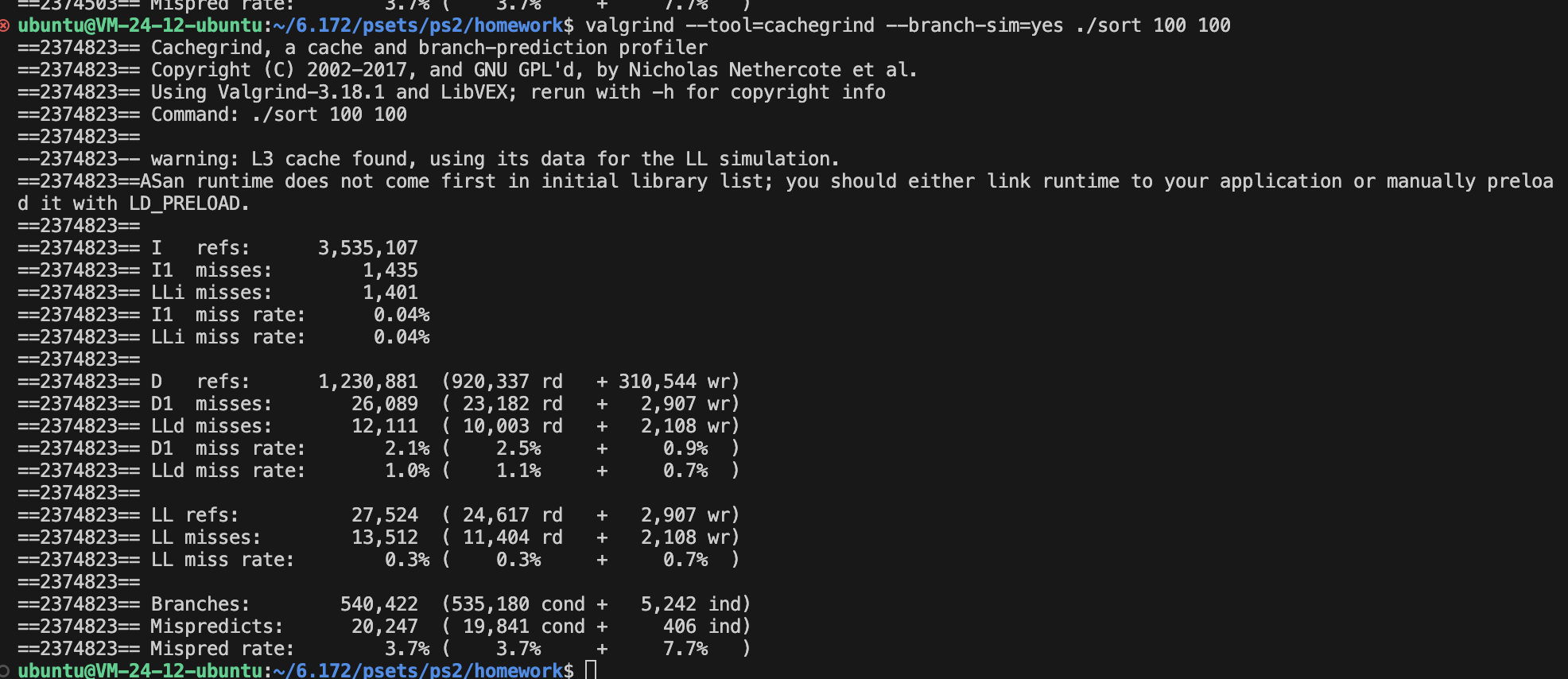
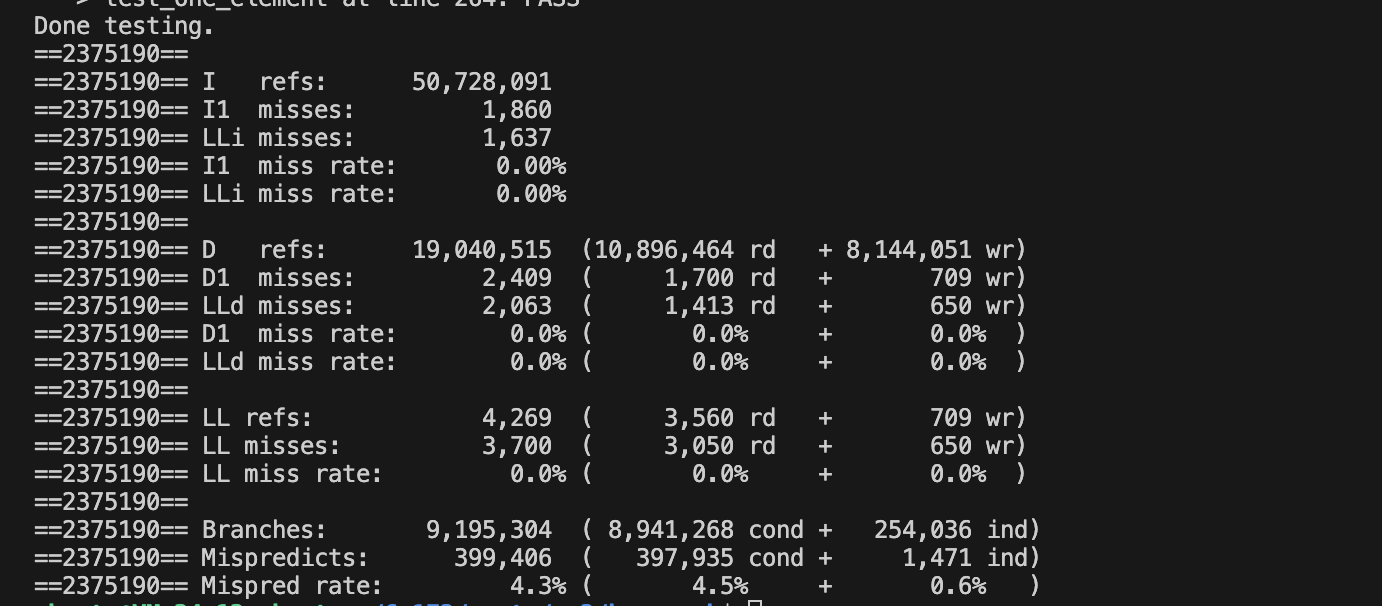
首先课程要求我们用cachegrind分析sort在DEBUG和非DEBUG模式下的命中情况,并且解释指令计数代替时间的优点和缺点。
课程默认是用clang的,但是clang14和clang17经过我测试对cachegrnd的兼容性都不好,读镜像文件报错,需要打补丁:https://bugs.kde.org/show_bug.cgi?id=452758
太麻烦了,因此我换成了gcc
DEBUG模式:
非DEBUG模式:
测试inline和非inline区别
这里和我的直觉相违背,事实上:
编译器几乎不需要inline辅助内联,但是我们仍然可以用inline增加被内联的概率。
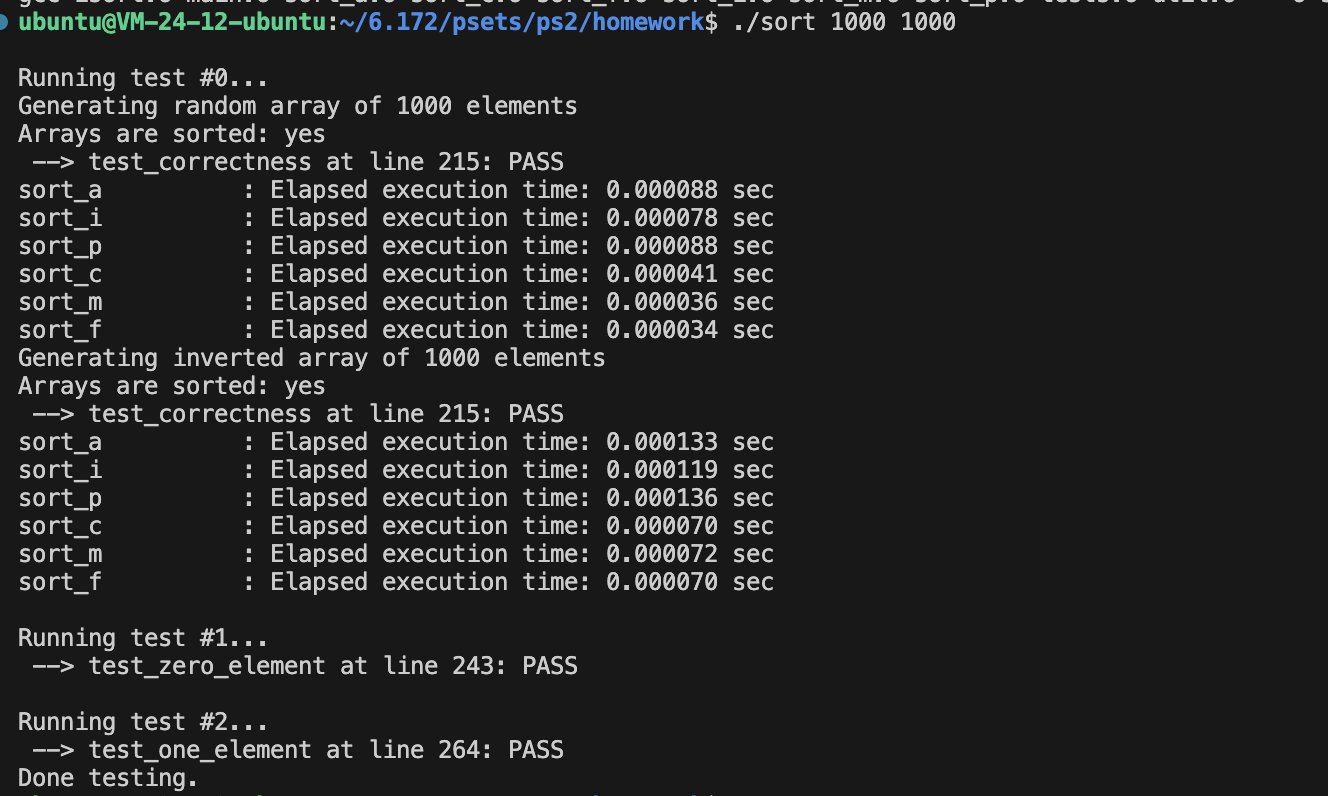
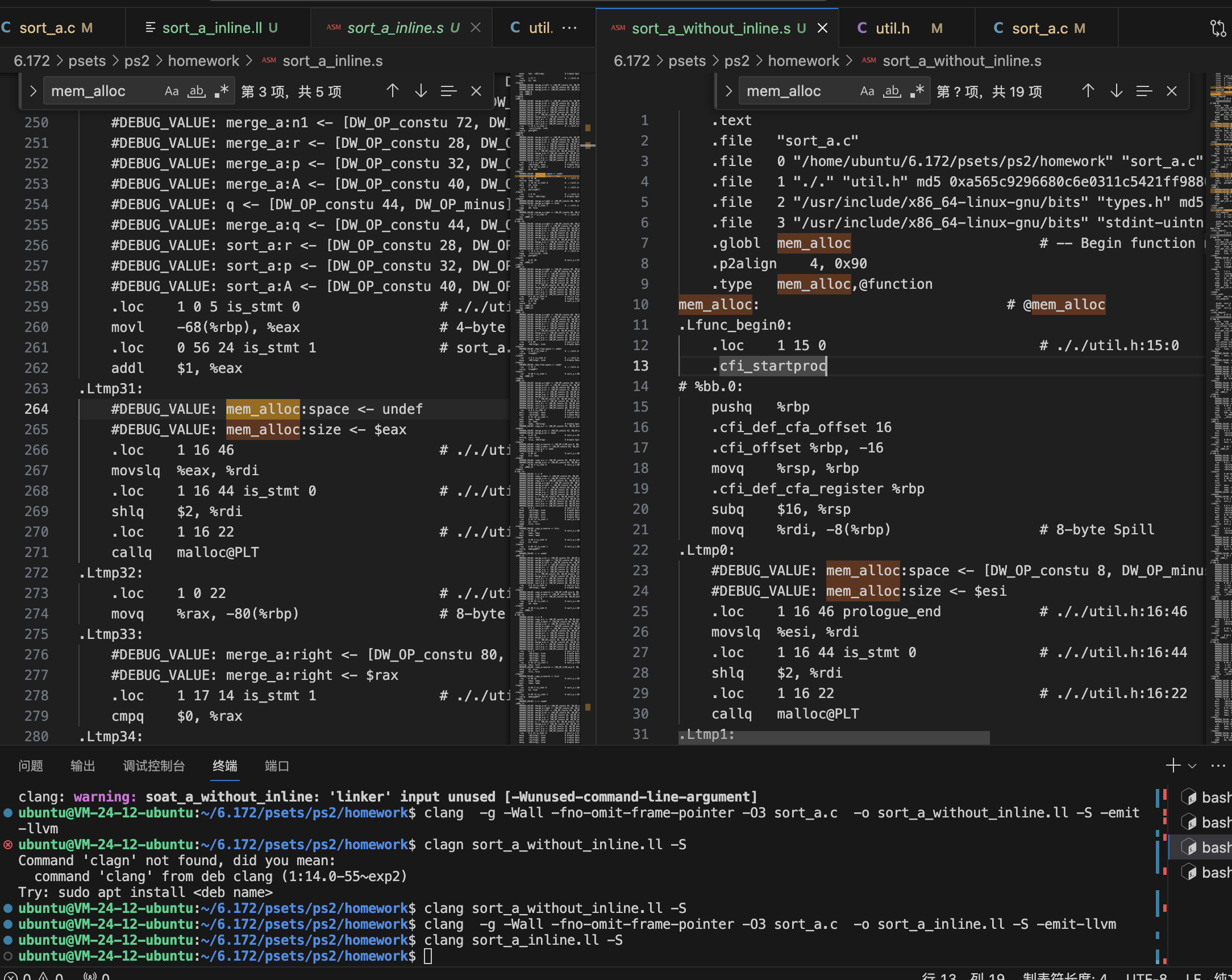
这里的性能差距主要是下面的跨翻译单元的alloc函数带来的:
void inline mem_alloc(data_t** space, int size) {
*space = (data_t*) malloc(sizeof(data_t) * size);
if (*space == NULL) {
printf("out of memory...\n");
}
}
void inline mem_free(data_t** space) {
free(*space);
*space = 0;
}
我们看这里生成的汇编代码:
指针和数组的比较比较简单,在此跳过。
Coarsening
void sort_c(data_t* A, int p, int r) {
assert(A);
// In practice, merge sort is slow for small array sizes. As such, using
// faster sorting techniques (i.e. insertion sort) when the array size is
// small (aka < 100), can make a significant improvement in the runtime.
if (r-p < 16) {
isort(&(A[p]), &(A[r]));
} else {
int q = (p + r) / 2;
sort_c(A, p, q);
sort_c(A, q + 1, r);
merge_c(A, p, q, r);
}
}
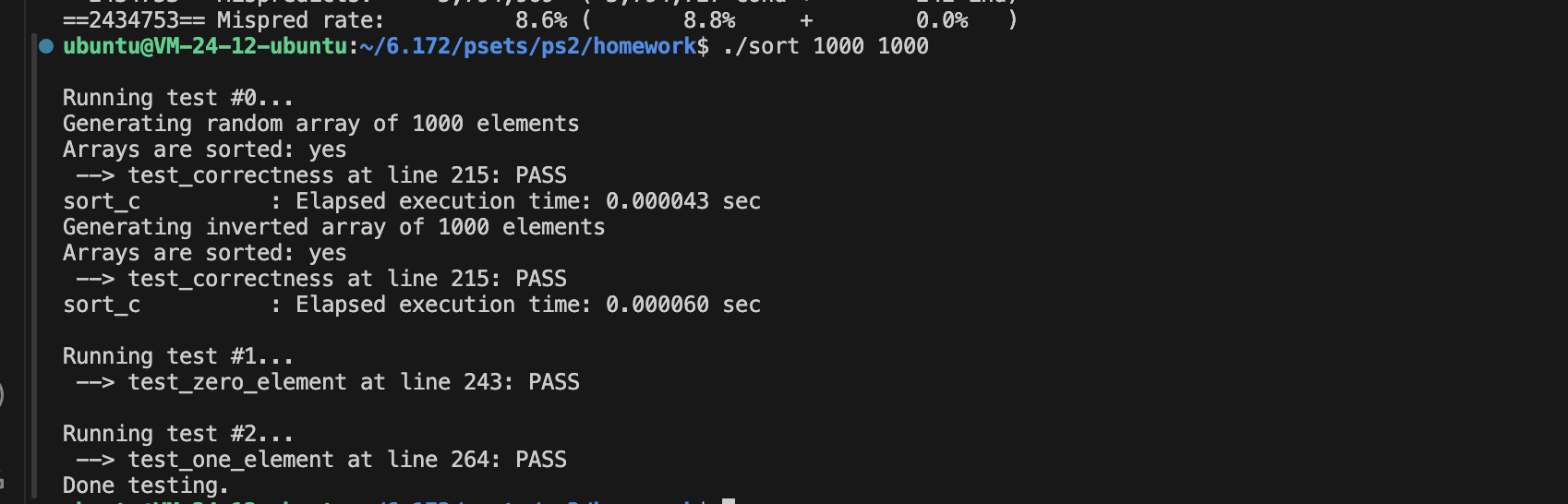
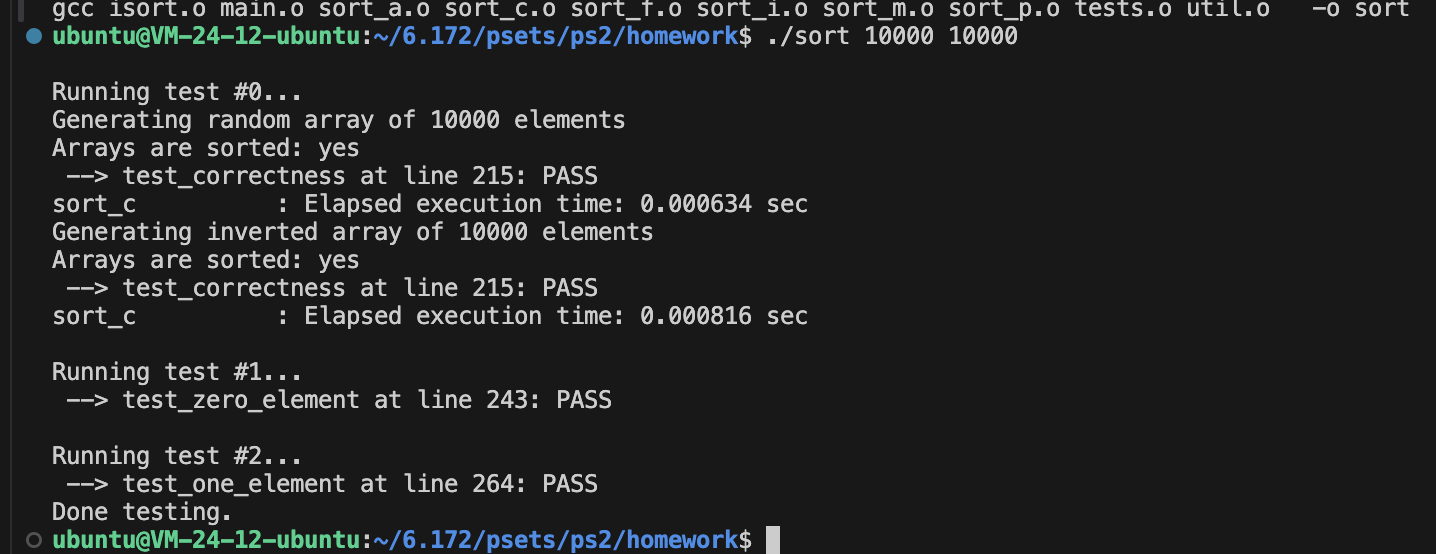
这里Coarsening的粒度主要收到cacheline的影响,因为L1的miss率是0。
用64字节的cacheline可以算出最佳参数应该是16。
16
100
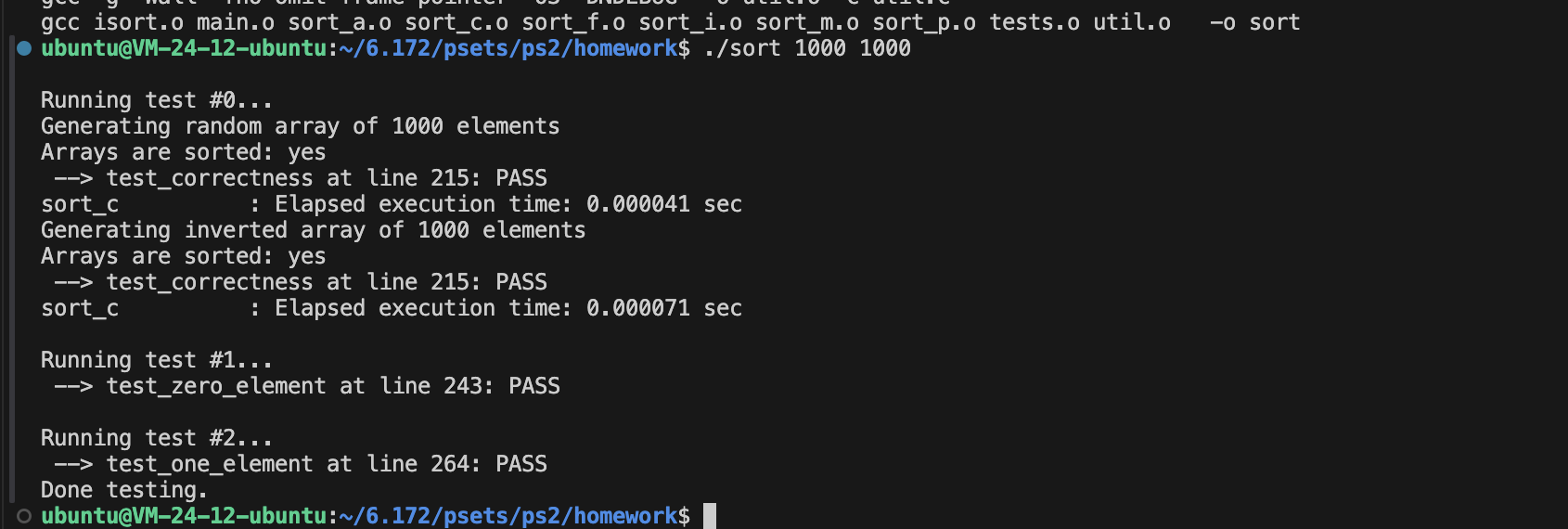
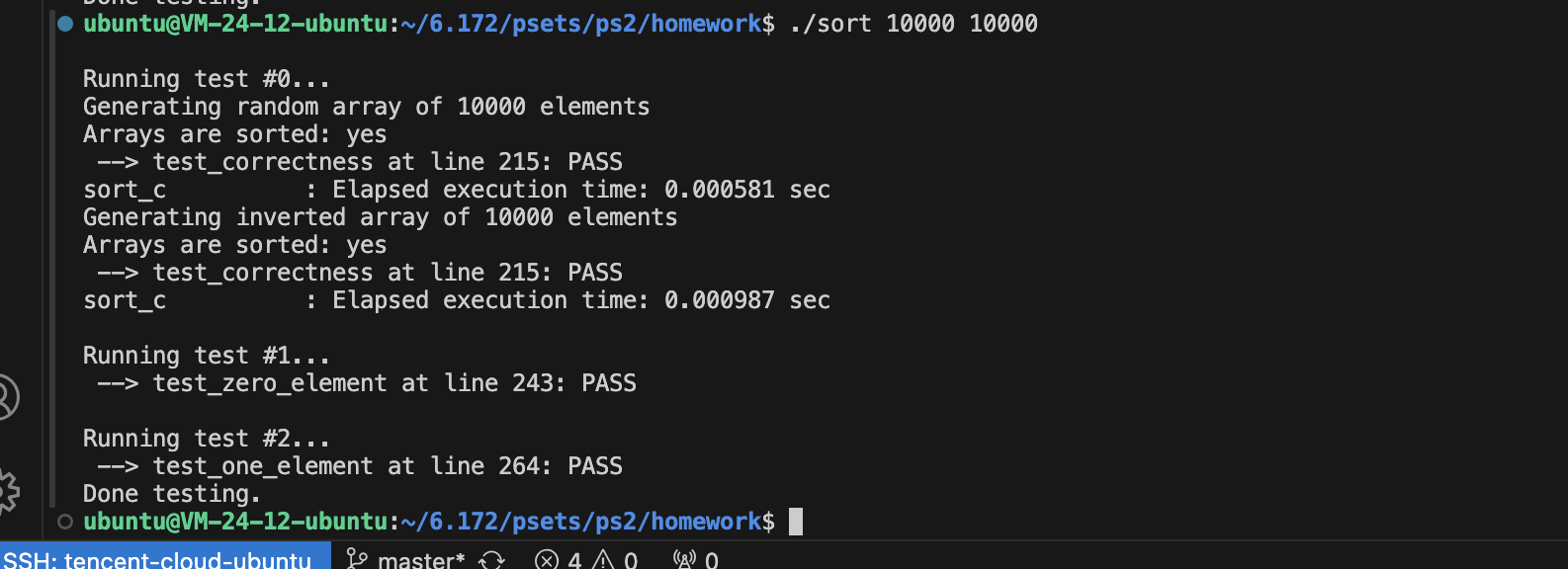
剩下的就是空间重用,很简单不多介绍了。
HW3 向量化
为什么用负偏移量
第一个问题很申必:


这里没有memcpy那种overlap问题,为什么用负偏移量呢?
问了下别人说是因为loop latch可以省一个cmp,而且现在clang已经不会这样做了(有指令fusion所以意义不大了),因此我们不需要太在意这个问题。
测量向量化
没有向量化的情况:

4宽向量化

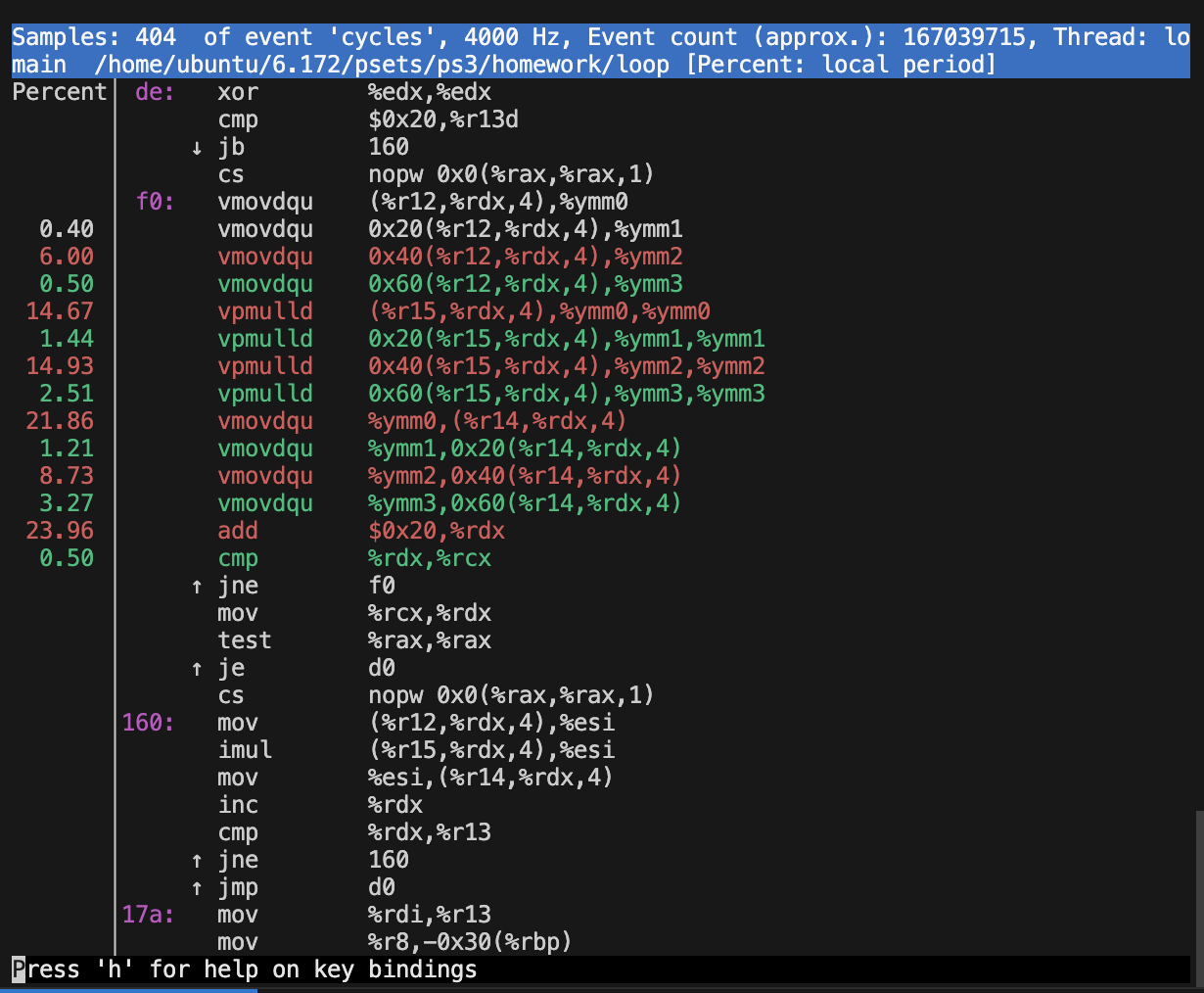
perf分析乘法:
耗时最多的是索引更新操作
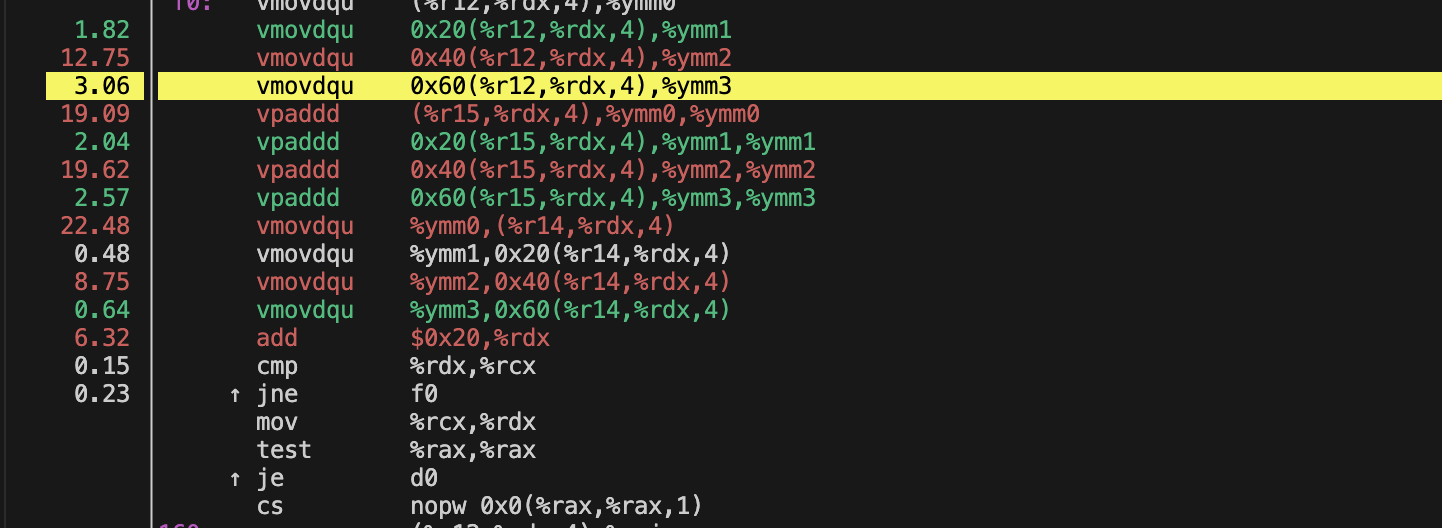
perf分析加法:
耗时最多的是向量化的加法
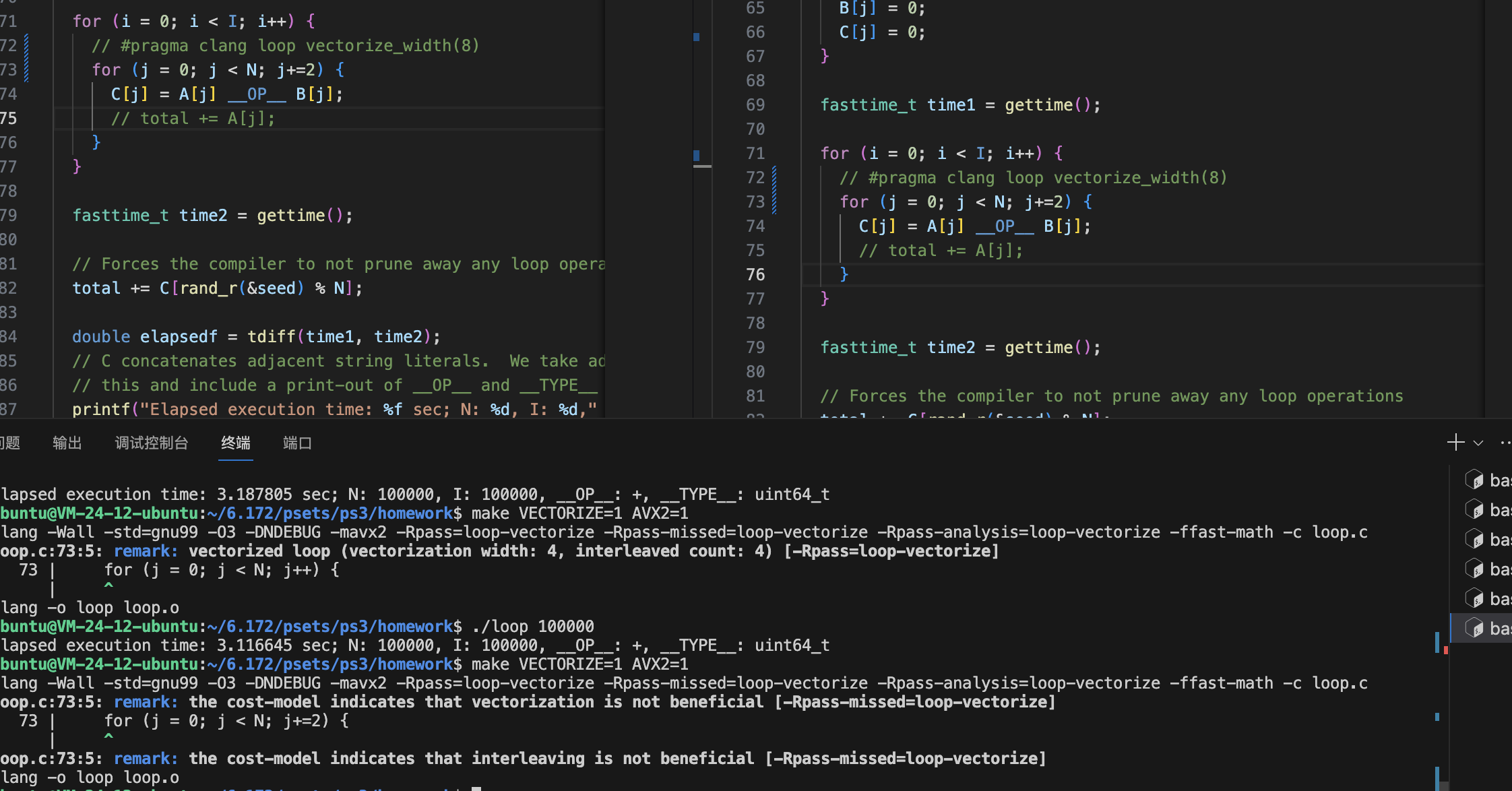
跨步向量化
跨步不会进行向量化:
强制进行向量化试试:
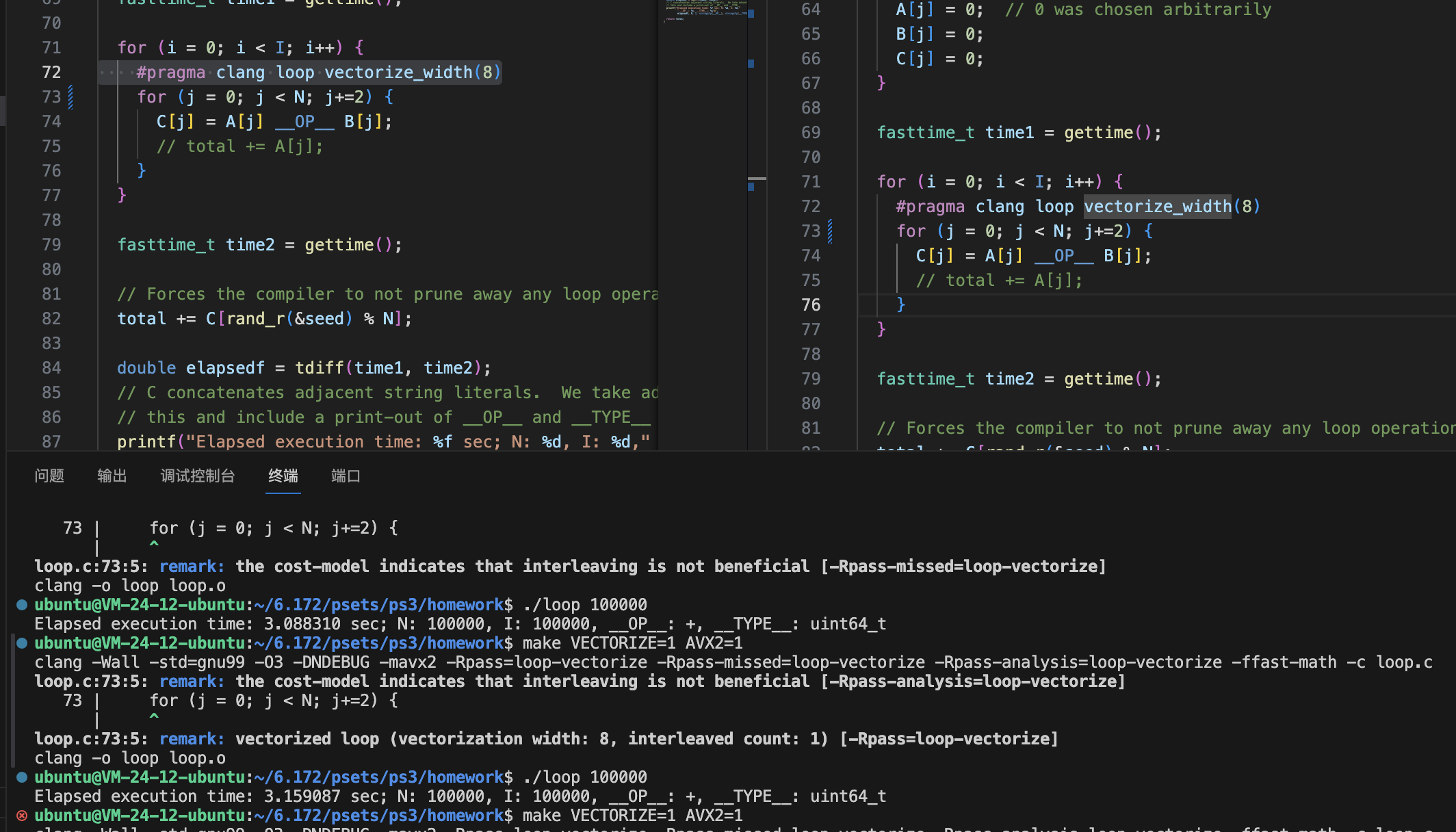
并没有变快
我们看看跨步向量化的汇编代码

跨步向量化会多出一个vextracti128指令进行提取,但是耗时很低
HW4 Reducer Hyperobjects
比较openmp和pthread
https://en.wikipedia.org/wiki/OpenMP#Pros_and_cons
优点:
可移植的多线程代码(在C/C++和其他语言中,通常必须调用特定于平台的原语才能获得多线程)。
简单:不需要像MPI那样处理消息传递。
数据布局和分解由指令自动处理。
可扩展性与共享内存系统上的MPI相当。[39]
增量并行:可以一次处理程序的一个部分,不需要对代码进行显著的更改。
串行和并行应用程序的统一代码:当使用顺序编译器时,OpenMP构造被视为注释。
在使用OpenMP并行化时,通常不需要修改原始(串行)代码语句。这减少了无意中引入错误的机会。
粗粒度和细粒度并行都是可能的。
在不完全遵循SPMD计算模式的不规则多物理应用中,如在紧密耦合的流体颗粒系统中遇到的那样,OpenMP的灵活性可以比MPI具有很大的性能优势。
可用于各种加速器,如GPGPU[41]和FPGA。
缺点:
引入难以调试的同步错误和竞争条件的风险。
截至2017年,仅在共享内存多处理器平台上有效运行(但请参阅Wayback Machine和其他分布式共享内存平台上的英特尔集群OpenMP存档2018-11-16)。
需要支持OpenMP的编译器。
可扩展性受到内存体系结构的限制。
不支持比较和交换。
缺少可靠的错误处理。
缺乏细粒度机制来控制线程处理器映射。
意外编写错误共享代码的几率很高。
omp汇编指令分析
见https://github.com/Chang-LeHung/openmp-tutorial/blob/master/docs/for.mdhttps://github.com/Chang-LeHung/openmp-tutorial/blob/master/docs/for.md
omp关键的几个操作用到了
lock cmpxchg、cmpxchg和__sync_fetch_and_add
如果划分的块比较小,那就不会用失败率比较高的cmpxchg,而是用__sync_fetch_and_add
omp task实现
见https://github.com/Chang-LeHung/openmp-tutorial/blob/master/docs/task.md
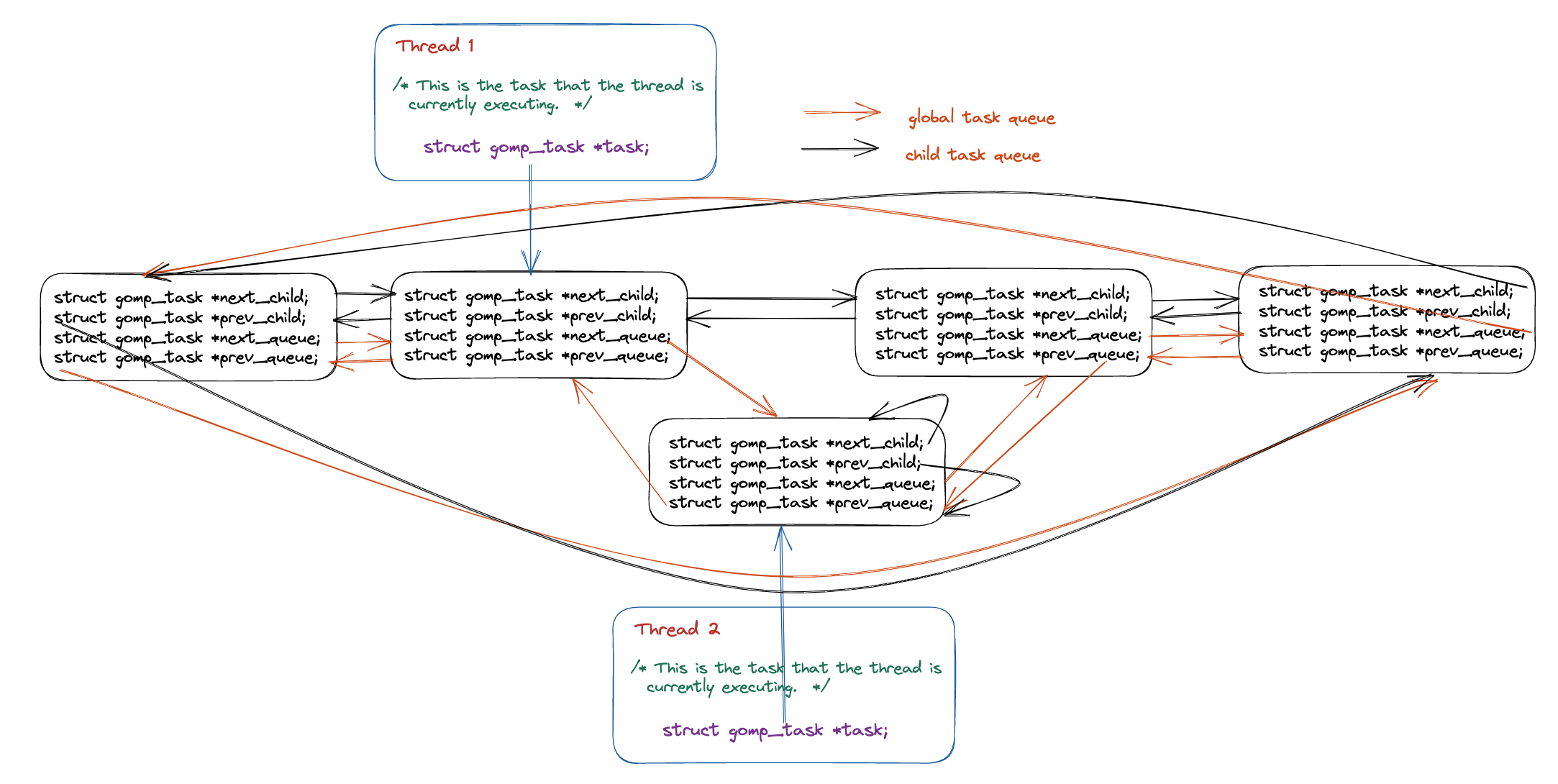
优化fib
#include <stdio.h>
#include <inttypes.h>
#include <stdlib.h>
#include "omp.h"
int64_t fib(int64_t n) {
if (n < 2) return n;
int64_t x, y;
if (n < 19) {
x = fib(n - 1);
y = fib(n - 2);
}
else {
#pragma omp task shared(x)
x = fib(n - 1);
#pragma omp task shared(y)
y = fib(n - 2);
#pragma omp taskwait
}
return (x + y);
}
int main(int argc, char* argv[]) {
int64_t n = atoi(argv[1]);
int64_t result;
omp_set_num_threads(4);
int nthreads = omp_get_num_threads();
printf("N = %d\n", nthreads);
// result = fib(n);
#pragma omp parallel
{
#pragma omp master
{
result = fib(n);
}
}
printf("Fibonacci of %" PRId64 " is %" PRId64 ".\n", n, result);
}
优化transpose
void transpose(Matrix* arr) {
uint16_t i, j;
// Parallel section:
#ifdef _OPENMP
#pragma omp parallel for private(i, j) num_threads(8) schedule(dynamic)
for (i = 1; i < arr->rows; i++) {
for (j = 0; j < i; j++) {
uint8_t tmp = arr->data[i][j];
arr->data[i][j] = arr->data[j][i];
arr->data[j][i] = tmp;
}
}
goto end;
#endif
// Serial section:
for (i = 1; i < arr->rows; i++) {
for (j = 0; j < i; j++) {
uint8_t tmp = arr->data[i][j];
arr->data[i][j] = arr->data[j][i];
arr->data[j][i] = tmp;
}
}
goto end;
end:
return;
}
schedule dynamic/static/runtime
https://stackoverflow.com/questions/10850155/whats-the-difference-between-static-and-dynamic-schedule-in-openmp
schedule(static,2) 每个线程分配两个循环块
比如:
#pragma omp parallel for schedule(static,2) num_threads(8)
for (i = 0; i < 8; i++)
memset(&a[i*4096], 1, 4096);
| | core 0 | thread 0 | a[0] ... a[8191] <- OK, same memory node
| socket 0 | core 1 | thread 1 | a[8192] ... a[16383] <- OK, same memory node
| NUMA node 0 | core 2 | thread 2 | a[16384] ... a[24575] <- Not OK, remote memory
| | core 3 | thread 3 | a[24576] ... a[32768] <- Not OK, remote memory
| | core 4 | thread 4 | <idle>
| socket 1 | core 5 | thread 5 | <idle>
| NUMA node 1 | core 6 | thread 6 | <idle>
| | core 7 | thread 7 | <idle>
#pragma omp for schedule(dynamic,1)
用在每个循环块执行时间由较大差别的情况。**schedule(runtime) 是 OpenMP 中用于动态选择循环迭代分配方式的一种方式。具体含义如下:
- runtime:表示在运行时动态选择循环迭代分配方式。这意味着循环迭代的分配方式将在程序运行时由运行时系统根据环境和系统的情况进行选择。
Cilk运行时

- RIP:RIP是英特尔x86处理器架构中的指令指针寄存器(Instruction Pointer Register)的缩写。该寄存器存储了当前正在执行的指令的内存地址。当处理器执行指令时,它会从RIP寄存器中获取下一条要执行的指令的地址。
- RBP:RBP是英特尔x86处理器架构中的基址指针寄存器(Base Pointer Register)的缩写。在函数调用过程中,RBP通常被用作栈帧的基址指针,用于定位函数的局部变量和参数。通过RBP,函数可以访问其局部变量和参数的内存位置。
- RSP:RSP是英特尔x86处理器架构中的栈指针寄存器(Stack Pointer Register)的缩写。栈是一种常用的数据结构,用于存储函数调用期间的局部变量、参数和返回地址等信息。RSP寄存器指向当前栈顶的内存地址,当新的数据被推入或弹出栈时,RSP的值会相应地更新。
HW 6 & HW7: Custom Memory Allocators
后面的两节都是选修课,因为有很多优秀的实现,比如mimalloc、tcmalloc,我之前也分析过,所以这节就跳过了,我们看下一节,lock free和wait free,这个还是很重要的。
HW9 & HW10 lock-free和wait-free
x86的默认内存模型

并行编程的golden和silver法则
golden rule:永远不要编写非确定性程序
silver rule:永远不要编写非确定性程序,如果必须要编写,那么使用完备的测试用例
使用setarch x86_64 -R来关闭ASLR
确定性的hashtable
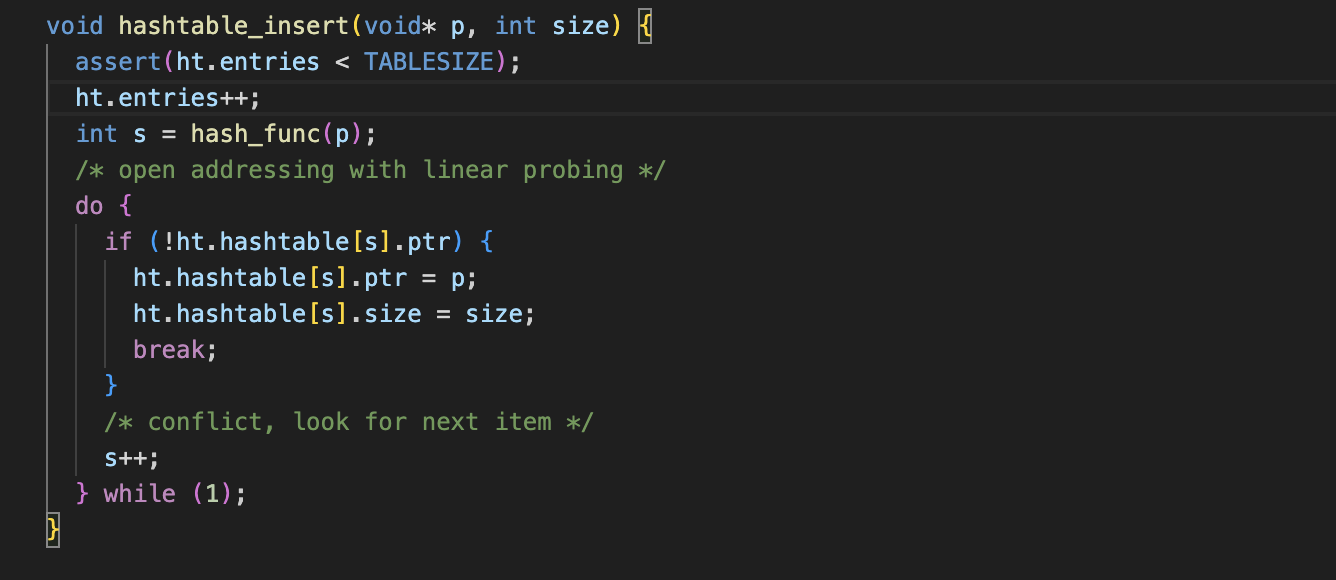
这里的问题在于probe可能超出范围,所以我们通过控制线程数可以实现 good和bad
矩阵乘法分析
https://en.algorithmica.org/hpc/algorithms/matmul/
strict alias能起到对齐的作用吗
在https://en.algorithmica.org/hpc/algorithms/matmul/中说__restrict__能解决alias问题,获得性能提升,但实际上:
https://quick-bench.com/q/GxzfeO3Jmul8g0dw9K1oKgQ_9fw
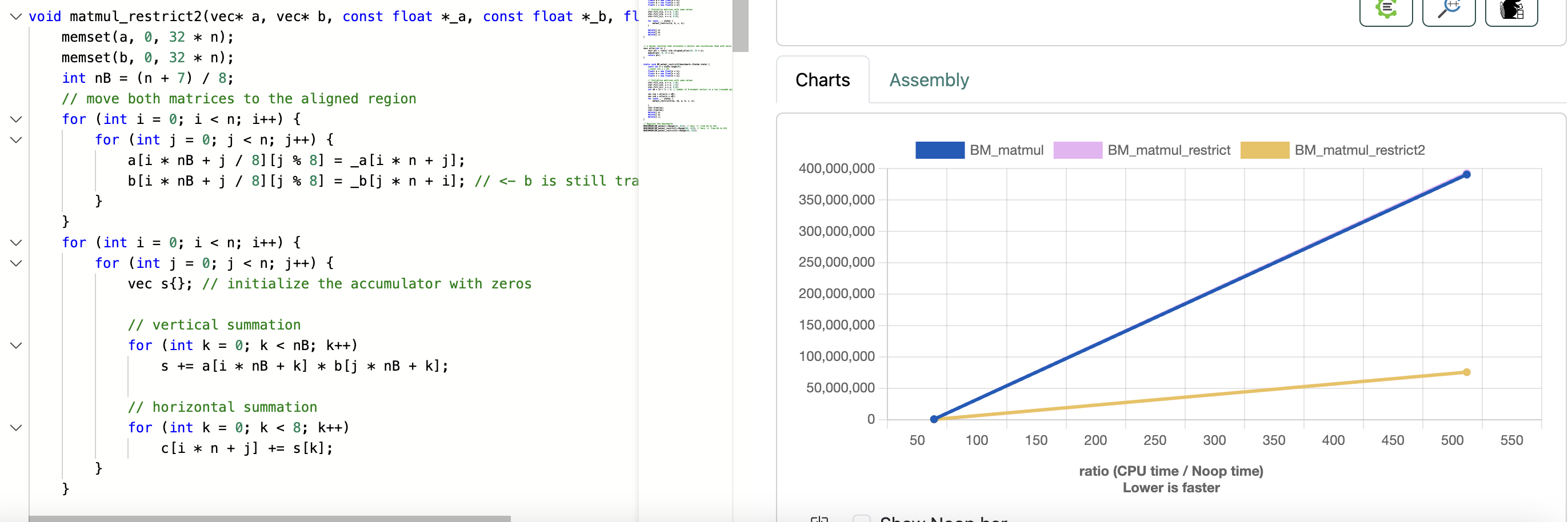
可以看得出来,对齐比alias在矩阵乘中作用大得多。

















 1619
1619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









